
MPP架构数据仓库使用问题之DADI的文件异步预取机制是怎么工作的
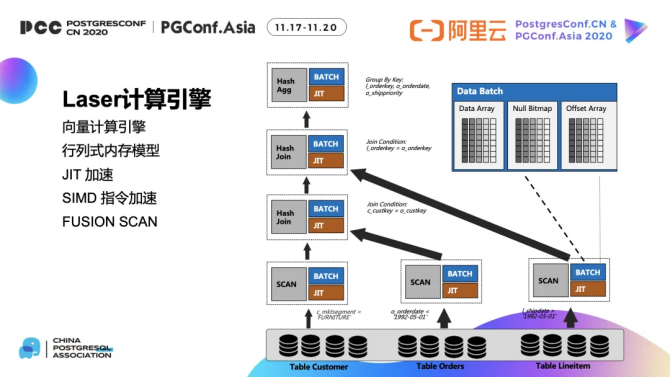
问题一:DADI的缓存优先级策略是如何实现的? DADI的缓存优先级策略是如何实现的? 参考回答: DADI的缓存优先级策略通过支持不同数据类型的不同缓存策略来实现。例如,统计信息被设置为高优先级并常驻内存,索引信息则常驻本地磁盘。同时,维度表数据也被赋予高优先级缓存在本地,以确保这些数据能够快速访问。 关于本问题的更多回答可点击原文...
MPP架构数据仓库使用问题之在ORC文件中,String类型字段是怎么进行编码的
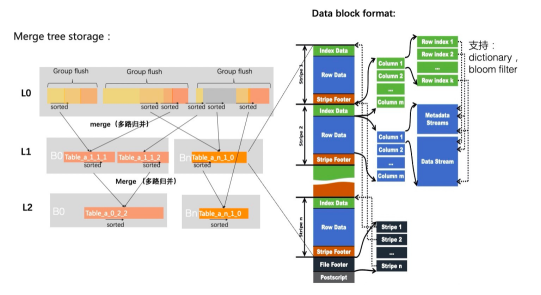
问题一:在Mergetree中,文件是如何跨层合并的? 在Mergetree中,文件是如何跨层合并的? 参考回答: 在Mergetree中,文件的合并是跨层的。符合合并条件的文件会被进行多路归并,合并后的文件内数据严格有序,但文件间大致有序。随着层数的增加,文件的大小也会增大,文件间的overlap则逐渐减小。 关于本问题的更多回答可...
MPP架构数据仓库使用问题之Visibility bitmap表被删除的文件信息是如何记录的
问题一:Level字段在ADB PG的Merge Tree中代表什么含义? Level字段在ADB PG的Merge Tree中代表什么含义? 参考回答: Level字段在ADB PG的Merge Tree中代表文件的合并层次。其中,0层代表实时写入的数据,这部分数据在合并时有更高的权重。Level值越大,表示该文件包含的数据越旧,合并时的权重越低。 ...
云数据仓库ADB采用的是标记删除方式,打标记的数据是存内存,还是落盘到磁盘里面的一个专门的标记文件里
云数据仓库ADB采用的是标记删除方式,这个打标记的数据是存内存,还是落盘到磁盘里面的一个专门的标记文件里啊?
云数据仓库ADB打标记的数据是存内存,还是落盘到磁盘里面的一个专门的标记文件里啊?
云数据仓库ADB采用的是标记删除方式,删除标记的数据如果定期清除的话,该数据会越来越大,应该有什么策略定期把标记数据与底层数据合并后并删除这部分标记数据吧?
云数据仓库ADB某个表里有50万行数据,怎么能导出excel文件?老是导出一部分的时候报错。
云数据仓库ADB某个表里有50万行数据,怎么能导出excel文件,老是导出一部分的时候报错,是adb报的错误。
云数据仓库ADB某个表里有190万行数据,怎么能导出excel文件?
云数据仓库ADB某个表里有190万行数据,怎么能导出excel文件,老是导出一部分的时候报错
云原生数据仓库AnalyticDB能否导出时到oss上是一个合并好的文件,而不是多个分片文件?
云原生数据仓库AnalyticDB使用upload命令导出csv到oss上,能否导出时到oss上是一个合并好的文件,而不是多个分片文件?https://help.aliyun.com/document_detail/186271.html?spm=a2c4g.35457.0.i5#961b7a9d16jcqUNLOAD ('SELECT FROM test')TO 'oss://adbpg-r.....
云数据仓库ADB load文件到数据库的时候有些时间报这个错,对这个报错你们有什么解决办法吗?
云数据仓库ADB load文件到数据库的时候有些时间报这个错,对这个报错你们有什么解决办法吗?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
实时数仓 Hologres
本技术圈将为大家分析有关阿里云产品Hologres的最新产品动态、技术解读等,也欢迎大家加入钉钉群--实时数仓Hologres交流群32314975
+关注