
如何配置Kafka输出组件用于向数据源写入数据
Kafka输出组件可以将外部数据库中读取数据写入到Kafka,或从大数据平台对接的存储系统中将数据复制推送至Kafka,进行数据整合和再加工。本文为您介绍如何配置Kafka输出组件。
使用Cluster Linking复制Kafka集群数据
Cluster Linking是Confluent Platform提供的一种功能,用于将多个Kafka集群连接在一起。该功能允许不同的Kafka集群之间进行数据的镜像和复制。Cluster Linking将在数据目标(Destination)集群启动,并复制数据源(Source)集群的数据到目标集群。本文将向您介绍如何使用云消息队列 Confluent 版的Cluster Linking。主要包...
实时计算 Flink版产品使用问题之如何使用Kafka Connector将数据写入到Kafka
问题一:Flink CDC里之前用mysql数据库join比较慢,这种join性能会比较好吗? Flink CDC里之前用mysql数据库join比较慢,所以才改成同步宽表到es,不知道doris,starorcks 这种join性能会比较好吗? 参考答案: Flink CDC 主要用于捕获和处理数据库变更数据流,而不是直接优化JOIN操作。MySQL...
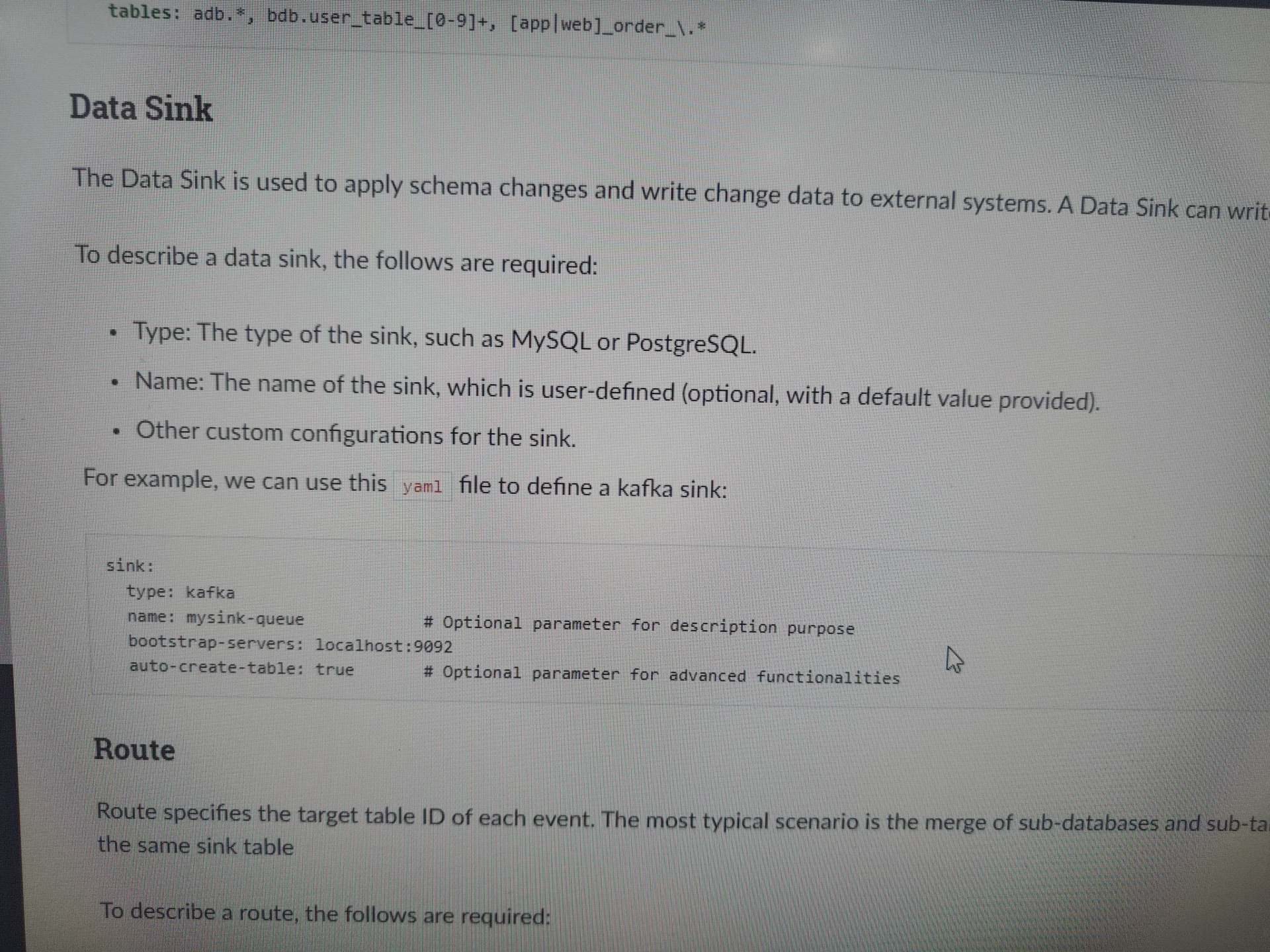
使用Confluent Replicator复制数据
Kafka MirrorMaker是一款用于在两个Apache Kafka集群之间复制数据的独立工具。它将Kafka消费者和生产者连接在一起。从源集群的Topic读取数据,并写入目标集群的同名Topic。相比于Kafka MirrorMaker,Confluent Replicator是一个更完整的解决方案,它能复制Topic的配置和数据,还能与Kafka Connect和Control Cent...
Flink 提供了与 Kafka 集成的官方 Connector,使得 Flink 能够消费 Kafka 数据
Apache Flink 是一个开源的分布式流处理框架,自 1.11 版本起,Flink 提供了与 Kafka 集成的官方 Connector,使得 Flink 能够消费 Kafka 数据。在 Flink 1.14.4 版本中,确实支持将 Kafka 偏移量保存在外部系统,如Kafka本身,并且可以手动维护这些偏...
有人知道这是啥问题吗?kafka connector,kafka有数据,打印不出来。这是kafka的
有人知道这是啥问题吗?kafka connector,kafka有数据,打印不出来。这是kafka的数据
kafka table connector保留多久的数据
你好, 用kafka table connector接过来的数据,在flink这边会保留多久,在参数列表里没有看到有这个设置,如果保留太久,内存会撑暴,比如我只想保留半个小时,之前的数据可以清除。*来自志愿者整理的flink邮件归档
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云消息队列 Kafka 版数据相关内容
- 云消息队列 Kafka 版数据磁盘
- 云消息队列 Kafka 版数据计算
- flinksql云消息队列 Kafka 版数据
- 产品云消息队列 Kafka 版数据
- 实时计算flink版云消息队列 Kafka 版数据
- 实时计算云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据数组
- 云消息队列 Kafka 版数据调节
- 数据云消息队列 Kafka 版分区有序
- cdc数据云消息队列 Kafka 版
- 数据云消息队列 Kafka 版
- 数据云消息队列 Kafka 版分区
- 同步数据云消息队列 Kafka 版
- 数仓云消息队列 Kafka 版数据
- python云消息队列 Kafka 版数据
- 报错云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据策略
- 云消息队列 Kafka 版机制数据
- 云消息队列 Kafka 版producer数据
- flinksql数据云消息队列 Kafka 版
- cdc云消息队列 Kafka 版数据配置
- 数据云消息队列 Kafka 版报错
- 云消息队列 Kafka 版数据配置
- 同步云消息队列 Kafka 版数据
- mysql云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据排查
- 阿里云云消息队列 Kafka 版数据
- 配置云消息队列 Kafka 版数据
- cdc同步云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据报错
云消息队列 Kafka 版更多数据相关
- 云消息队列 Kafka 版数据格式格式数据
- 云消息队列 Kafka 版格式数据
- 库云消息队列 Kafka 版数据
- 云消息队列 Kafka 版流处理数据
- 云消息队列 Kafka 版数据代码
- 云消息队列 Kafka 版任务数据
- streaming云消息队列 Kafka 版数据
- spark云消息队列 Kafka 版数据
- 数据云消息队列 Kafka 版snapshot
- 实时计算flink版数据云消息队列 Kafka 版
- flink云消息队列 Kafka 版数据
- 采集数据云消息队列 Kafka 版
- 云消息队列 Kafka 版数据mysql
- canal数据云消息队列 Kafka 版
- canal云消息队列 Kafka 版数据
- flink云消息队列 Kafka 版同步数据
- 实时计算flink云消息队列 Kafka 版数据
- canal同步数据云消息队列 Kafka 版
- 云消息队列 Kafka 版数据字段
- 云消息队列 Kafka 版数据参数
- 云消息队列 Kafka 版topic数据
- 云消息队列 Kafka 版数据清理
- 云消息队列 Kafka 版订阅数据
- 云消息队列 Kafka 版数据乱序
- 云消息队列 Kafka 版数据延迟
- 捕获数据云消息队列 Kafka 版
- 云消息队列 Kafka 版数据hive
- 连接云消息队列 Kafka 版数据
- flume云消息队列 Kafka 版数据
- 云消息队列 Kafka 版消费数据
云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版分配
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版生产者
- 云消息队列 Kafka 版平台
- 云消息队列 Kafka 版分析
- 云消息队列 Kafka 版分布式
- 云消息队列 Kafka 版实战
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版常见问题
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版日志
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版原理
- 云消息队列 Kafka 版连接
- 云消息队列 Kafka 版解析
- 云消息队列 Kafka 版java
- 云消息队列 Kafka 版入门
- 云消息队列 Kafka 版架构
