
Spark SQL交互式查询
如果您需要以交互式方式执行Spark SQL,可以指定Spark Interactive型资源组作为执行查询的资源组。资源组的资源量会在指定范围内自动扩缩容,在满足您交互式查询需求的同时还可以降低使用成本。本文为您详细介绍如何通过控制台、Hive JDBC、PyHive、Beeline、DBeaver等客户端工具实现Spark SQL交互式查询。
通过Spark SQL读写SQL Server数据
云原生数据仓库 AnalyticDB MySQL 版支持提交Spark SQL作业,您可以通过View方式访问自建SQL Server数据库或云数据库 RDS SQL Server 版数据库。本文以云数据库 RDS SQL Server 版为例,介绍如何通过Spark SQL访问SQL Server数据。
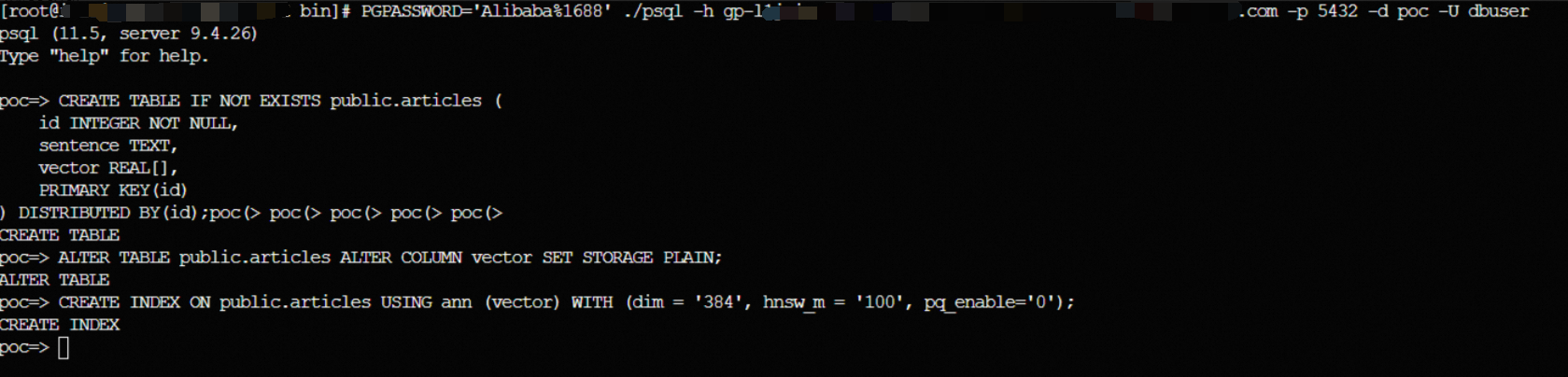
云原生数据仓库AnalyticDB PostgreSQL同一个SQL可以实现向量索引、全文索引GIN、普通索引BTREE混合查询,简化业务实现逻辑、提升查询性能
参考文档:https://help.aliyun.com/zh/analyticdb/analyticdb-for-postgresql/user-guide/fusion-search-use-guide?spm=a2c4g.11186623.help-menu-92664.d_2_8_3.4bf95fa2s3zEtw&scm=20140722.H_2528590._.OR_help-....
使用SQL实现机器学习预测
本文介绍如何在云原生数据仓库 AnalyticDB MySQL 版中,利用SQL语言快速部署BST(Behavior Sequence Transformer)模型执行机器学习任务,包括从数据加工、模型创建、训练到最终的评估与预测的整个流程。
通过Spark SQL读写Azure Blob Storage外表
本文主要介绍如何在云原生数据仓库 AnalyticDB MySQL 版中使用Spark SQL读写Azure Blob Storage中的数据。
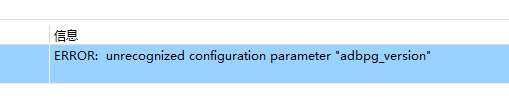
云原生数据仓库AnalyticDB PostgreSQL版用SQL链接数据库时?
云原生数据仓库AnalyticDB PostgreSQL版用SQL链接数据库时,这里的user和password填哪个用户名,还有命名空间和密码填在哪https://help.aliyun.com/zh/analyticdb-for-postgresql/user-guide/use-sql-operations-to-access-vector-databases?spm=a2c4g.1118....
云原生数据仓库使用问题之控制JDBC方式请求的SQL大小限制的参数是什么
问题一:云数据仓库ADB慢查询表中,shuffle_size 该列表示什么,是哪一部分的shuffl ? 云数据仓库ADB中,慢sql查询是什么? 参考答案: 慢SQL查询通常是指执行耗时长、消耗资源多的SQL语句,常见的资源消耗包括CPU、内存和磁盘I/O。以下是对阿里云ADB数据库中几种典型慢查询及其成因分析: 消耗CPU的慢查询原因可能包...
云原生数据仓库使用问题之怎么查看正在执行的SQL语句
问题一:云数据仓库ADB中,使用字符串类型字段作为分布键和主键,性能怎样? 云数据仓库ADB中,使用字符串类型字段作为分布键和主键,性能怎样? 参考答案: 使用字符串类型字段作为分布键和主键时,性能上可能不如数值类型理想。在阿里云ADB MySQL数据库中,推荐使用数值类型字段作为主键以获得较好的表性能,因为数值类型通常比字符串类型占用空间小且处理效率...
云原生数据仓库使用问题之如何修改历史数据清理的SQL
问题一:DMS中,昨天晚上任务重复调度的,有没有办法快速判断任务SQL业务逻辑是否幂等? DMS中,昨天晚上任务重复调度的,有没有办法快速判断任务SQL业务逻辑是否幂等? 参考答案: 在DMS中,若一个任务中的SQL语句被重复调度执行,要快速判断其业务逻辑是否幂等,需要分析SQL的具体内容。幂等性指的是一个操作无论执行多少次,结果都是一致的,不会因为多...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
实时数仓Hologres
Hologres是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。欢迎加入钉群:实时数仓Hologres交流群32314975
+关注