
Kimi开源Moonlight-16B-A3B:基于Muon优化器的高效大模型,性能与训练效率双突破!
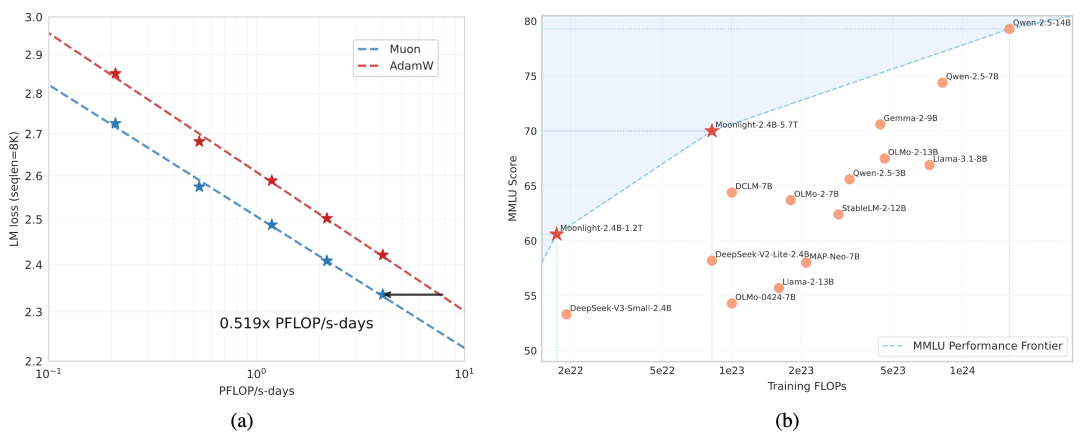
01前言 最近,Muon优化器在训练小规模语言模型方面展示了强大的效果,但其在大规模模型上的可扩展性尚未得到验证。Kimi确定了两个扩展Muon的关键技术: 权重衰减:对扩展到更大模型至关重要 一致的RMS更新:在模型更新中保持一致的均方根 这些技术使Muon能够在大规模训练中开箱即用,无需超参数调优。扩展定律实验表明,...
PyTorch基础之优化器模块、训练和测试模块讲解(附源码)
一、优化器模块torch.optim是一个具备各种优化算法的库,可以支持大部分常用的优化方法,并且这个接口具备足够的通用性,这使得它能够集成更加复杂的优化算法1:optimizer的使用构建一个optimizer对象参数设置(需要优化的参数、设置学习率等)另外,还可以单独设置每个参数值表示model.base的参数都将使用0.001的学习率,model.regression的参数将使用0.000....

减少内存消耗、降低大模型训练成本,ACL杰出论文作者揭秘CAME优化器
在语言模型的训练中,优化器往往占据了大量的内存使用。然而,随着大语言模型参数量的不断增加,随之而来的是训练时的内存消耗更为严峻。目前,自适应梯度优化算法,如 Adam 和 LAMB,在大规模语言模型的训练中表现出出色的训练性能。然而,传统优化算法对自适应的需求需要保存每个参数梯度的二阶矩估计,从而导致额外的内存开销。为了解决这个问题,研究者们提出了一些内存高效的优化器(例如 Adafactor)....
全面碾压AdamW!谷歌新出优化器内存小、效率高,网友:训练GPT 2果然快
谷歌的 Lion 优化器将成为训练大模型或大批量的「福音」。优化器即优化算法,在神经网络训练中起着关键作用。近年来,研究者引入了大量的手工优化器,其中大部分是自适应优化器。Adam 以及 Adafactor 优化器仍然占据训练神经网络的主流,尤其在语言、视觉和多模态领域更是如此。除了人工引入优化器外,还有一个方向是程序自动发现优化算法。此前有人提出过 L2O(learning to optimi....

Sea AI Lab和北大Adan项目原作解读:加速训练深度模型的高效优化器
自 Google 提出 Vision Transformer (ViT)以来,ViT 渐渐成为许多视觉任务的默认 backbone。凭借着 ViT 结构,许多视觉任务的 SOTA 都得到了进一步提升,包括图像分类、分割、检测、识别等。然而,训练 ViT 并非易事。除了需要较复杂的训练技巧,模型训练的计算量往往也较之前的 CNN 大很多。近日,新加坡 Sea AI Lab 和北大 ZERO Lab....
训练ViT和MAE减少一半计算量!Sea和北大联合提出高效优化器Adan,深度模型都能用
自Google提出Vision Transformer(ViT)以来,ViT渐渐成为许多视觉任务的默认backbone。凭借着ViT结构,许多视觉任务的SoTA都得到了进一步提升,包括图像分类、分割、检测、识别等。然而,训练ViT并非易事。除了需要较复杂的训练技巧,模型训练的计算量往往也较之前的CNN大很多。近日,新加坡Sea AI LAB (SAIL) 和北大ZERO Lab的研究团队共同提出....

【PyTorch基础教程9】优化器和训练过程
学习总结(1)每个优化器都是一个类,一定要进行实例化才能使用,比如:class Net(nn.Moddule): ··· net = Net() optim = torch.optim.SGD(net.parameters(), lr=lr) optim.step() (2)optimizer在一个神经网络的epoch中需要实现下面两个步骤:梯度置零,梯度更新。optimizer = t...
如何使用优化器让训练网络更快——神经网络的奥秘
通过使用Numpy来创建神经网络,让我意识到有哪些因素影响着神经网络的性能。架构、超参数值、参数初始化,仅是其中的一部分,而这次我们将致力于对学习过程的速度有巨大影响的决策,以及所获得的预测的准确性—对优化策略的选择。我们会研究很多流行的优化器,研究它们的工作原理,并进行对比。 你在GitHub上可以找到所有代码: 机器学习算法的优化 优化是搜索用于最小化或最大化函数参数的过程。当我们训练机器学....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

