
使用PyJindo访问阿里云OSS-HDFS
本文将以两种方式为您介绍如何在Python 3.6及更高版本中,利用Python的工具包PyJindo来操作OSS-HDFS。
阿里云账号角色授权
使用EMR Serverless Spark前,需要授予您的阿里云账号AliyunServiceRoleForEMRServerlessSpark和AliyunEMRSparkJobRunDefaultRole系统默认角色。本文为您介绍角色授权的基本操作。
云数据库SelectDB使用MaxCompute数据源
本文介绍云数据库 SelectDB 版与阿里云MaxCompute数据源进行对接使用的流程,帮助您对阿里云MaxCompute数据源进行联邦分析。
阿里云大数据ACA及ACP复习题(341~350)
341.Mapreduce是一个分布式运算程序的编程框架,关于Mapreduce,描述正确的是( A )。A:适合海量静态数据(批数据)计算B:磁盘IO开销不大C:易编程,适合实时计算D:是分布式计算框架,当一台机器失败后,可以手动切换至其他节点运行该任务 解析:MapReduce的优点: 1、易...
开源大数据平台E-MapReduce产品服务协议_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
阿里云产品的服务协议,请参见阿里云产品服务协议。
阿里云大数据ACA及ACP复习题(101~110)
101.阿里云DataWorks是数据上云下云的枢纽,致力于提供复杂网络环境下、丰富的 (B) 之间高速稳定的数据移动及同步能力。A:关系型数据库B:异构数据源C:NosQLD:非结构化存储 解析:DataWorks的数据集成功能模块是稳定高效、弹性伸缩的数据同步平台,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。 htt...
阿里云大数据ACA及ACP复习题(21~30)
21.Hadoop的主要功能中,能完成对海量数据分布式运算的是哪个组件?(D)A:HDFSB:DFSC:RDDD:MapReduce 解析:MAPREDUCE(分布式运算编程框架) 22.以下选项中不属于MaxCompute特点的是(D)A:支持多种多种经典的分布式计算模型B:海量数据存储与计算C:保障数...
阿里云大数据ACA及ACP复习题(1~10)
1.(多选)MaxCompute在每一个项目空间在创建时,会自动创建admin的角色, 并且为该角色授予了确定的权限。以下权限中不属于admin的有哪些(ABC)。A:设定项目空间的安全配置B:修改项目空间的鉴权模型C:将admin权限指派给其他用户D:以package方式授权E:对其他用户或角色进行授权 ...
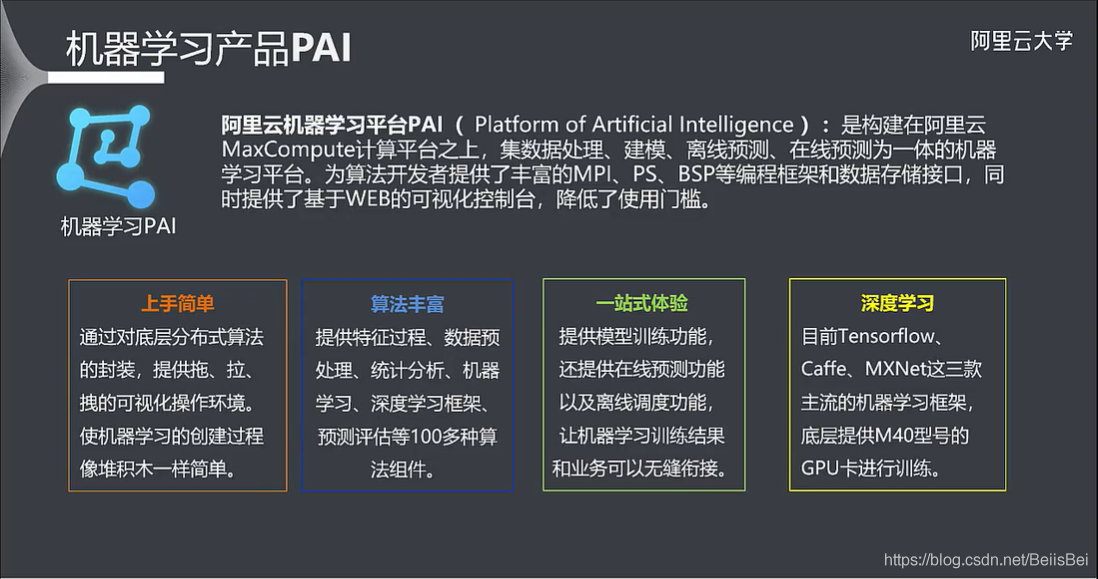
阿里云大数据ACP(四)机器学习 PAI 2
五、产品介绍5.1 PAI 架构5.2 PAI 功能特性5.3 PAI 的可视化5.4 PAI 支持的算法5.5 支持深度学习5.6 基本概念5.7 机器学习PAI 在线预测、离线调度六、产品应用6.1 应用流程6.2 数据预处理6.3 特征工程6.4 统计分析6.5 深度学习框架6.6 应用流程
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute阿里云相关内容
- 阿里云云原生大数据计算服务 MaxCompute产品升级
- 模型阿里云云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute升级
- 阿里云云原生大数据计算服务 MaxCompute产品
- 阿里云云原生大数据计算服务 MaxCompute人工智能
- 阿里云数据库ai云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute平台
- 阿里云云原生大数据计算服务 MaxCompute数据分析
- 阿里云云原生大数据计算服务 MaxCompute实战
- 阿里云云原生大数据计算服务 MaxCompute构建
- 阿里云云原生大数据计算服务 MaxCompute公测
- 阿里云emr云原生大数据计算服务 MaxCompute
- 阿里云构建云原生大数据计算服务 MaxCompute
- 阿里云人工智能云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute引擎
- 评测阿里云云原生大数据计算服务 MaxCompute
- 阿里云dataworks云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute spark
- 阿里云云原生大数据计算服务 MaxCompute oss
- 阿里云领跑云大云原生大数据计算服务 MaxCompute
- 连接阿里云云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute阿里云服务
- 云原生大数据计算服务 MaxCompute产品阿里云
- 阿里云平台云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute开源
- 开源阿里云云原生大数据计算服务 MaxCompute
- sreworks阿里云云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute云原生
- 阿里云云原生大数据计算服务 MaxCompute运维
- 阿里云云原生大数据计算服务 MaxCompute案例
云原生大数据计算服务 MaxCompute更多阿里云相关
- 阿里云飞天云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute入门
- 新能源汽车云原生大数据计算服务 MaxCompute阿里云lindorm
- 云原生大数据计算服务 MaxCompute阿里云功能
- 阿里云云原生大数据计算服务 MaxCompute工程
- 阿里云存储云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute解决方案
- 数据迁移阿里云云原生大数据计算服务 MaxCompute
- 阿里云大数据计算云原生大数据计算服务 MaxCompute
- 阿里云openapi云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute aca acp复习题
- 阿里云云原生大数据计算服务 MaxCompute月刊
- 阿里云云原生大数据计算服务 MaxCompute专业认证考试
- 阿里云云原生大数据计算服务 MaxCompute开服
- 云原生大数据计算服务 MaxCompute阿里云主账号
- 阿里云数加云原生大数据计算服务 MaxCompute
- 阿里云acp云原生大数据计算服务 MaxCompute
- 阿里云一站式云原生大数据计算服务 MaxCompute
- 开学季阿里云云原生大数据计算服务 MaxCompute
- 阿里云数据平台云原生大数据计算服务 MaxCompute
- 阿里云云原生大数据计算服务 MaxCompute ai
- 阿里云云原生大数据计算服务 MaxCompute函数
- 阿里云云原生大数据计算服务 MaxCompute quickbi
- 阿里云平台云原生大数据计算服务 MaxCompute教学案例
- 阿里云云原生大数据计算服务 MaxCompute专业认证
- 阿里云云原生大数据计算服务 MaxCompute数据集成
- 阿里云云原生大数据计算服务 MaxCompute dataworks
- 阿里云acp云原生大数据计算服务 MaxCompute考试
- 阿里云云原生大数据计算服务 MaxCompute项目
- 阿里云云原生大数据计算服务 MaxCompute分析
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute解析
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute操控
- 云原生大数据计算服务 MaxCompute工具
- 云原生大数据计算服务 MaxCompute较量
- 云原生大数据计算服务 MaxCompute温度
- 云原生大数据计算服务 MaxCompute数据链路
- 云原生大数据计算服务 MaxCompute预测性维护
- 云原生大数据计算服务 MaxCompute故障
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目
