
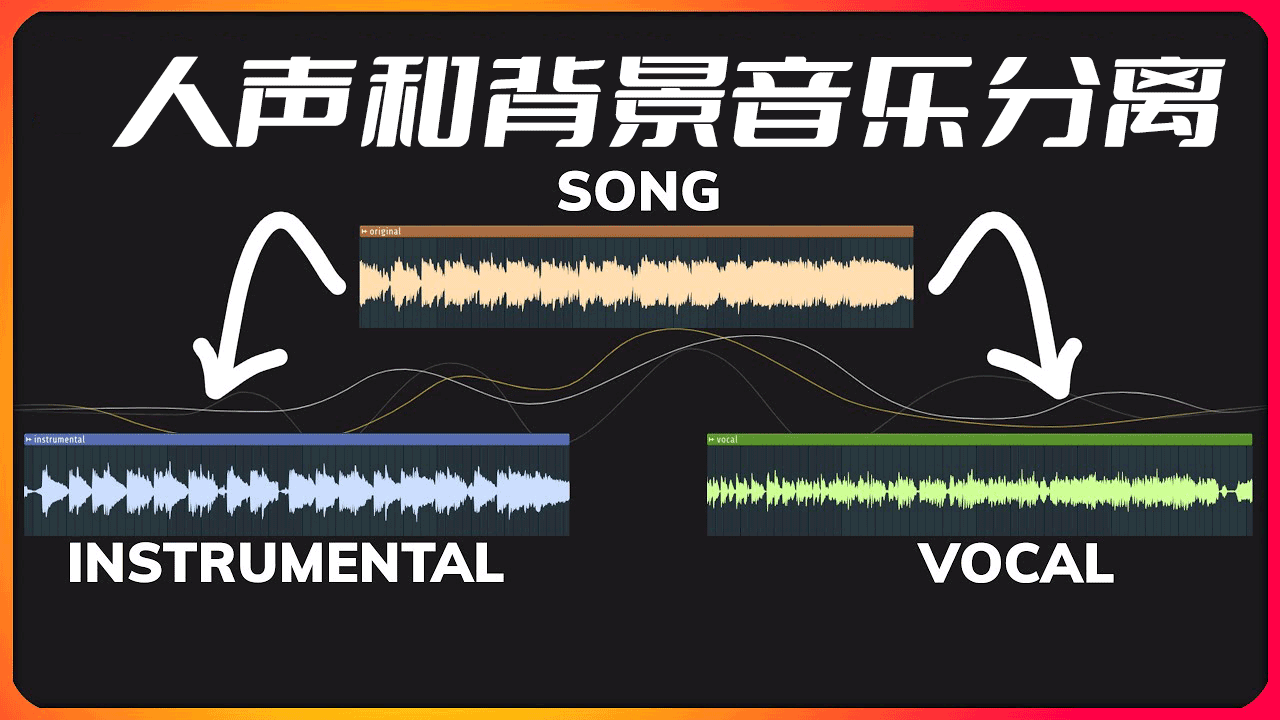
TIGER:清华突破性模型让AI「听觉」进化:参数量暴降94%,菜市场都能分离清晰人声
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术! 微信公众号|搜一搜:蚝油菜花 「你的降噪耳机过时了!清华突破性模型让AI「听觉」进化:参数量暴降94%,菜市场都能分离清晰人声」 大家好,我是蚝油菜花。当你在这些场景崩溃时—— 地铁电话会议:同事发言总被报站声「截胡」...

阿里云语音AI阿里云有说话人分离的服务吗?或者,谁知道通义听悟API可否返回分离后的语音文件?
阿里云语音AI阿里云有说话人分离的服务吗?或者,谁知道通义听悟API可否返回分离后的语音文件?
请问阿里云语音AI有针对客服通话录音的吗?业务场景是客服通话。不是分离,阿里没做语音分离方面的吗?
请问阿里云语音AI有针对客服通话录音的吗?业务场景是客服通话。不是分离,阿里没做语音分离方面的吗?
请问阿里云语音AI中有提供客户电话录音声音分离的业务吗?
问题1:请问阿里云语音AI中有提供客户电话录音声音分离的业务吗?问题2:可以分离出录音中的声音分别保存成音频文件吗?如果有,可以发一下链接吗?我看一下,以及价格如何?效果如何?
我刚才测试了一下 阿里语音AI这个角色分离好像不行啊?
我刚才测试了一下 阿里语音AI这个角色分离好像不行啊?这分离出来的 还是重复的 还标记成了 不同角色。
人工智能AI库Spleeter免费人声和背景音乐分离实践(Python3.10)
在视频剪辑工作中,假设我们拿到了一段电影或者电视剧素材,如果直接在剪辑的视频中播放可能会遭遇版权问题,大部分情况需要分离其中的人声和背景音乐,随后替换背景音乐进行二次创作,人工智能AI库Spleeter可以帮我们完成大部分素材的人声和背景音乐的分离流程。 Spleeter的模型源来自最大的音乐网站Deezer,底层基于深度学习框架Tensorflow,它可以通过模型识别出素材中的背景音乐素材,.....
一周AI最火论文 | 分离听不清的七嘴八舌,只需一张面部快照
本周关键词:GANs、Julia+R、AI数据库本周最火学术研究FaR-GAN单次面部重现随着生成模型,尤其是生成对抗网络(GAN),在计算机视觉中的快速发展,人们越来越关注具有挑战性的任务,例如生成逼真的照片,图像到图像翻译,文本到图像翻译以及超分辨率等。面部重现是这些具有挑战性的任务之一,它需要对面部的几何形状和运动进行3D建模。它在图像编辑,增强和交互式系统中具有许多应用,例如使用自然的人....
MIT又出新玩法,利用AI可轻松分离视频中的乐器声音
均衡器是大概是被用来在音乐中加入低音的一种常用方式,但近日,麻省理工学院计算机科学与人工智能实验室(CSAIL)的研究人员研发了一个更好的解决方案。他们的深度学习系统——PixelPlayer——可以通过人工智能来分离乐器演奏视频中的乐器声音,同时还能改变音量,让它们变得更响亮或更柔和。 经过充分训练的PixelPlayer系统,以视频作为输入,可以对相应的音频进行分割,识别声音来源,然后根据每....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
阿里云机器学习平台PAI
阿里云机器学习PAI(Platform of Artificial Intelligence)面向企业及开发者,提供轻量化、高性价比的云原生机器学习平台,涵盖PAI-iTAG智能标注平台、PAI-Designer(原Studio)可视化建模平台、PAI-DSW云原生交互式建模平台、PAI-DLC云原生AI基础平台、PAI-EAS云原生弹性推理服务平台,支持千亿特征、万亿样本规模加速训练,百余落地场景,全面提升工程效率。
+关注