
MapReduce系统学习(2)
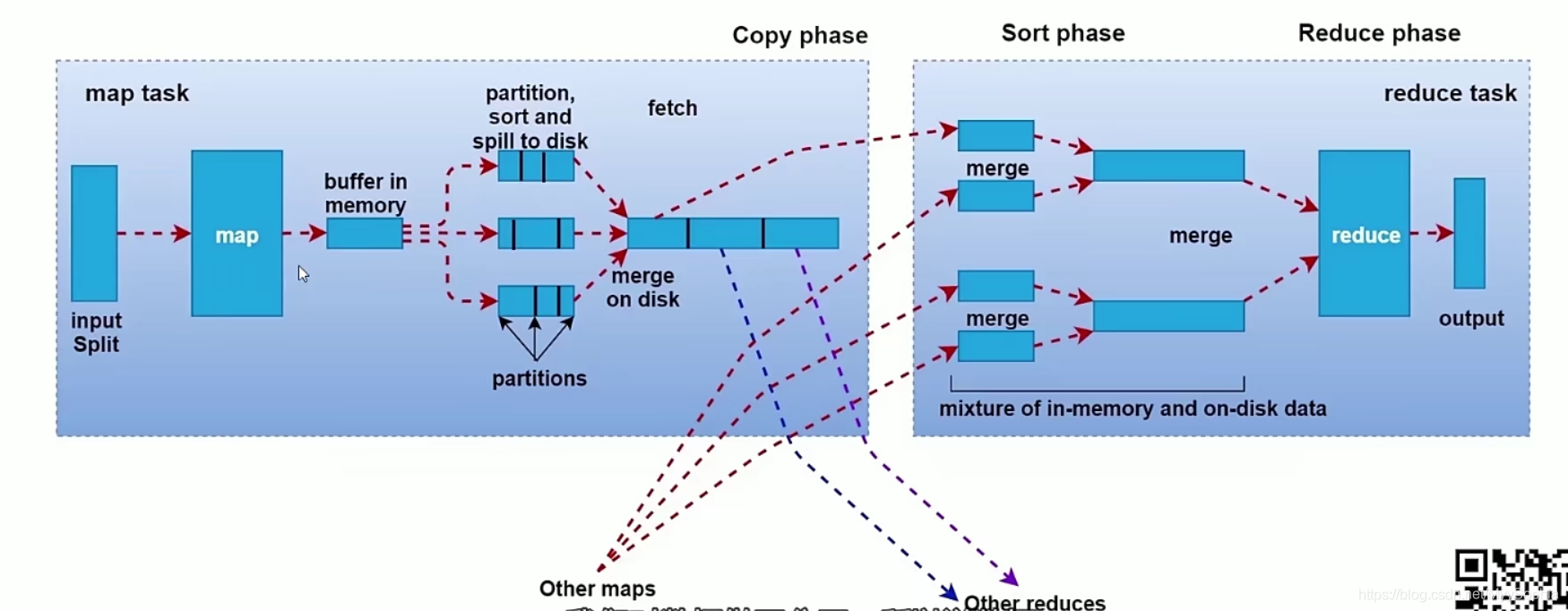
Shuffle过程详解shuffer是一个网络拷贝的过程,是指通过网络把数据从map端拷贝到reduce端的过程.map阶段最左边有一个inputsplit,最终会产生一个map任务,map任务在执行的时候会k1,v1转化为k2,v2,这些数据会先临时存储到一个内存缓冲区中,这个内存缓冲区的大小默认是100M(io.sort.mb属性),当达到内存缓冲区大小的80%(io.sort.spill.per....
MapReduce系统学习
MapReduce介绍计算扑克牌中的黑桃个数就是我们平时打牌时用的扑克牌,现在呢,有一摞牌,我想知道这摞牌中有多少张黑桃最直接的方式是一张一张检查并且统计出有多少张是黑桃,但是这种方式的效率比较低,如果说这一摞牌只有几十张也就无所谓了,如果这一摞拍有上千张呢?你一张一张去检查还不疯了?这个时候我们可以使用MapReduce的计算方法第一步:把这摞牌分配给在座的所有玩家 ....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
阿里云E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注
