
FastAPI与Selenium:打造高效的Web数据抓取服务 —— 采集Pixabay中的图片及相关信息
引言 在互联网数据采集中,图片数据往往占据了重要位置。Pixabay作为一个免版权图片网站,拥有海量优质图片。本文将展示如何利用FastAPI搭建一个RESTful接口,通过Selenium模拟浏览器行为访问Pixabay,并使用代理IP、User-Agent和Cookie配置提高爬虫稳定性,进而采集页面中图片及其相关描述信息。 环境准备 本文示例依赖以下第三方库: FastAPI:用于搭建...

使用selenium+chromedriver+xpath爬取动态加载信息(一)
使用selenium+chromedriver+xpath爬取动态加载信息 使用selenium实现动态渲染页面的爬取,selenium是浏览器自动化测试框架,是一个用于Web应用程序测试的工具,可以直接运行在浏览器当中,并可以驱动浏览器执行指定的动作,如点击、下拉、填充数据、删除cookie等操作...
使用selenium+chromedriver+xpath爬取动态加载信息(二)
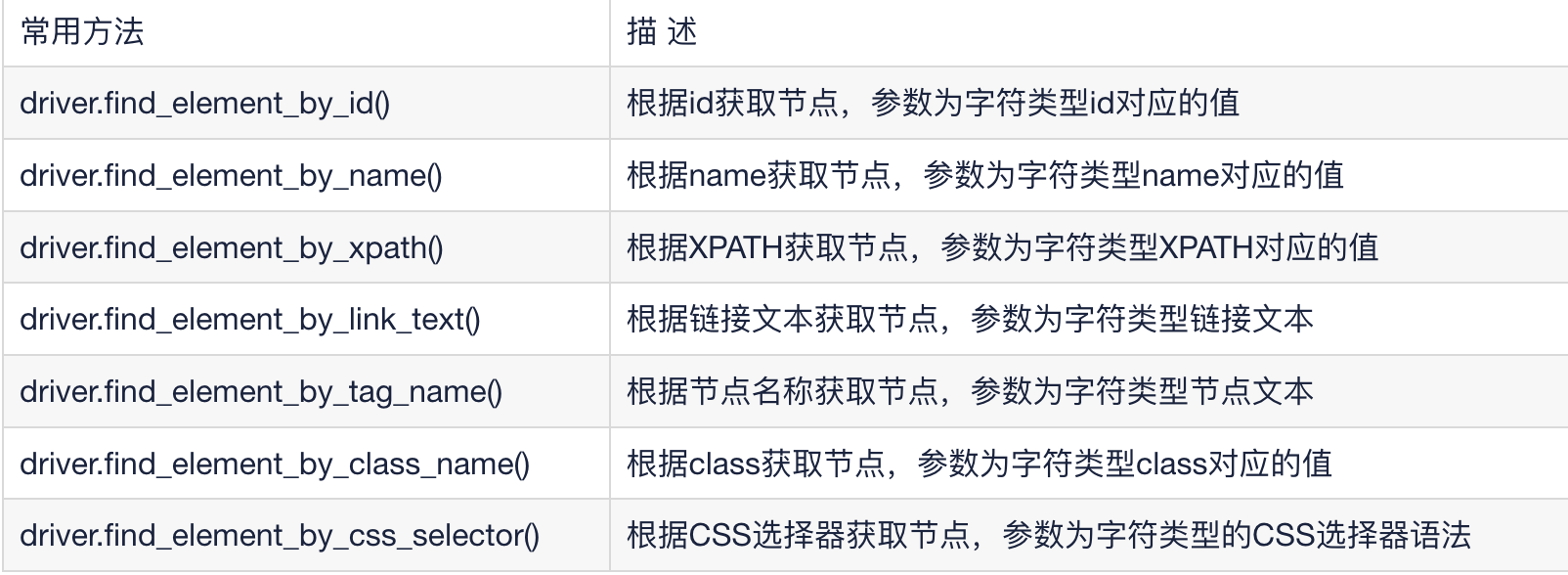
接上文使用selenium+chromedriver+xpath爬取动态加载信息(一)https://developer.aliyun.com/article/1617935 selenium 模块的常用方法selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下表:selenium 模块获取网页节点的常用方...
selenium 知网爬虫之根据【关键词】获取文献信息
哈喽大家好,我是咸鱼 之前咸鱼写过几篇关于知网爬虫的文章,后台反响都很不错。虽然但是,咸鱼还是忍不住想诉苦一下 有些小伙伴文章甚至代码看都没看完,就问我 ”为什么只能爬这么多条文献信息?“(看过代码的会发现我代码里面定义了 papers_need 变量来设置爬取篇数),”为什么爬其他文献不行?我想爬 XXX 文献“(因为代码里面写的是通过【知网高级搜索中的文献来源】来搜索文章),或者是有些小...
深入网页分析:利用scrapy_selenium获取地图信息
导语 网页爬虫是一种自动获取网页内容的技术,它可以用于数据采集、信息分析、网站监测等多种场景。然而,有些网页的内容并不是静态的,而是通过JavaScript动态生成的,例如图表、地图等复杂元素。这些元素往往需要用户的交互才能显示出来,或者需要等待一定时间才能加载完成。如果使用传统的爬虫技术,如requests或urllib,就无法获取到这些元素的内容,因为它们只能请求网页的源代码,而不能执行J.....

selenium--记录日志信息
前戏在我们进行web自动化的时候,我们希望记录下日志信息,方便我们进行定位分析,我们可以使用logging模块来进行记录实战先写个配置文件Logger.conf来管理日志的配置[loggers] keys=root,example01,example02 [logger_root] level=DEBUG handlers=hand01,hand02 [logger_example01] han....
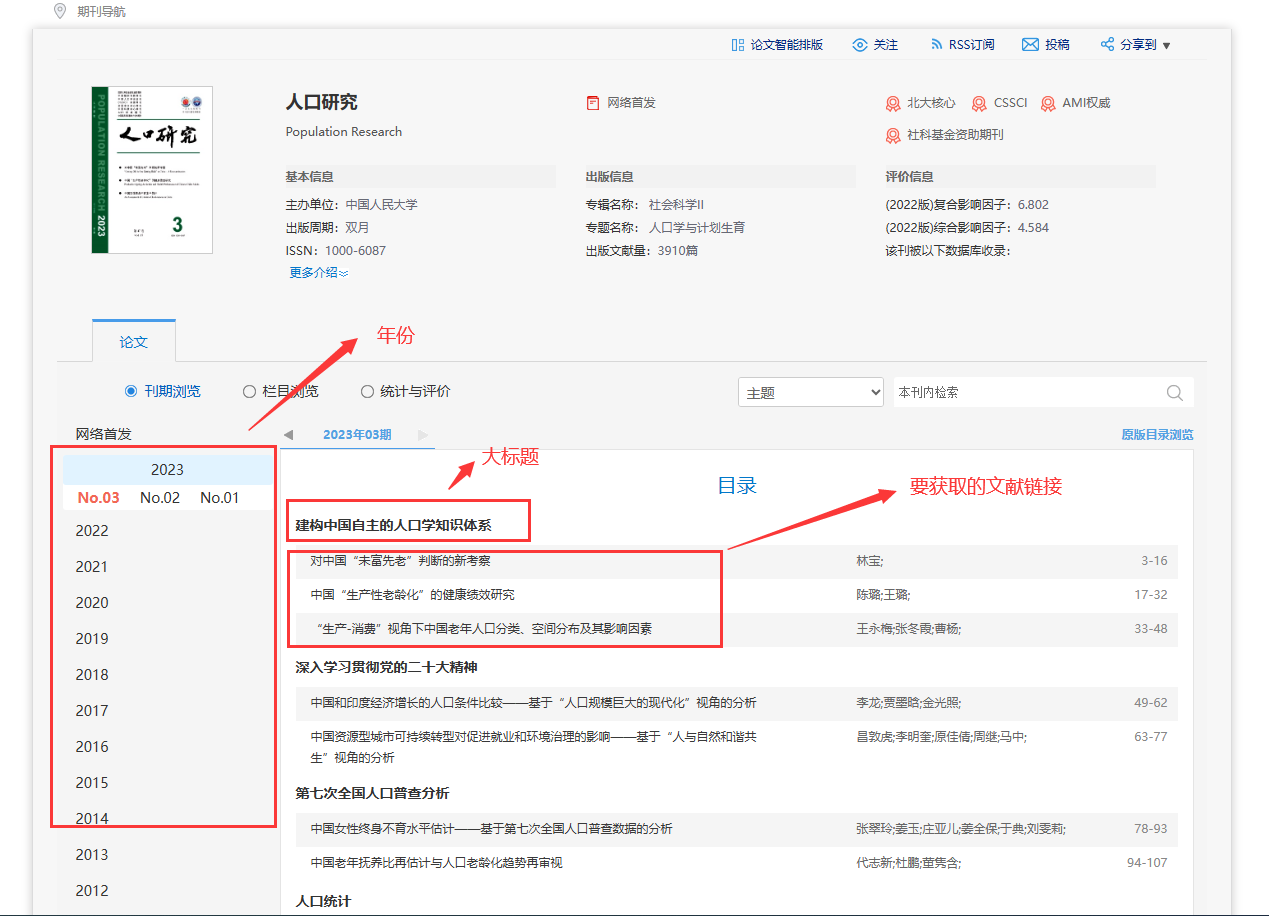
selenium 根据期刊信息获取知网文献信息 pt.1
哈喽大家好,我是咸鱼 之前写过一篇获取知网文献信息的文章(关于《爬取知网文献信息》中代码的一些优化),看了下后台数据还挺不错 所以咸鱼决定再写一篇知网文献信息爬取的文章 需要注意的是文章只是针对某一特定期刊的爬取,希望小伙伴们把关注点放在如何分析网页以及如何定位元素上面 这样就能写出适合自己的爬虫代码了,而不是照搬我的 网址链接:https://navi.cnki.net/knavi/...
软件测试|selenium常用页面信息对比方法expected_conditions
说明:本篇博客基于selenium 4.1.0expected_conditions介绍expected_conditions是selenium的一个模块(简称EC),提供了一系列的对比页面信息的方法expected_conditions作用expected_conditions可结合WebDriverWait中的until()和until_not()中的方法,完成显示等待expected_co....

用selenium获取直播信息
作者简介:大家好,我是阿牛。 格言:迄今所有人生都大写着失败,但不妨碍我继续向前!目录前言一、本文使用的第三方包和工具二、selenium的介绍和浏览器驱动的安装三、代码思路分析四、完整代码总结前言 目前是直播行业的一个爆发期,由于国家对直播行业进行整顿和规范,现在整个直播行业也在稳固发展。随着互联网和网络直播市场的快速发展...
通过爬虫中的selenium控制chrome,Firefox等浏览器自动操作获取相关信息
1.首先将我们需要的selenium的包导入fromselenium.webdriverimportChrome(如果使用chrome浏览器就导入chrome,如果使用别的浏览器则将名称换掉即可) 2.创建浏览器对象web=Chrome() 3.打开浏览器web.get("http://www.baidu.com")(此处以百度举例) 4.找到某个元素. 点击它el=web.find_elem.....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Selenium您可能感兴趣
- Selenium playwright
- Selenium数据
- Selenium chromedriver
- Selenium表单
- Selenium库
- Selenium模拟登录
- Selenium python
- Selenium采集
- Selenium数据抓取
- Selenium web
- Selenium自动化
- Selenium测试
- Selenium自动化测试
- Selenium java
- Selenium教程
- Selenium浏览器
- Selenium webdriver
- Selenium框架
- Selenium元素
- Selenium爬虫
- Selenium定位
- Selenium方法
- Selenium chrome
- Selenium报错
- Selenium页面
- Selenium详细教程
- Selenium测试框架
- Selenium元素定位
- Selenium软件测试
- Selenium环境搭建
开发与运维
集结各类场景实战经验,助你开发运维畅行无忧
+关注