
Spark访问MaxCompute数据
MaxCompute开放存储支持Spark通过Connector调用Storage API,直接读取MaxCompute的数据,简化了读取数据的过程,提高了数据访问性能。同时,Spark集成MaxCompute的数据存储能力,实现了高效、灵活和强大的数据处理和分析。
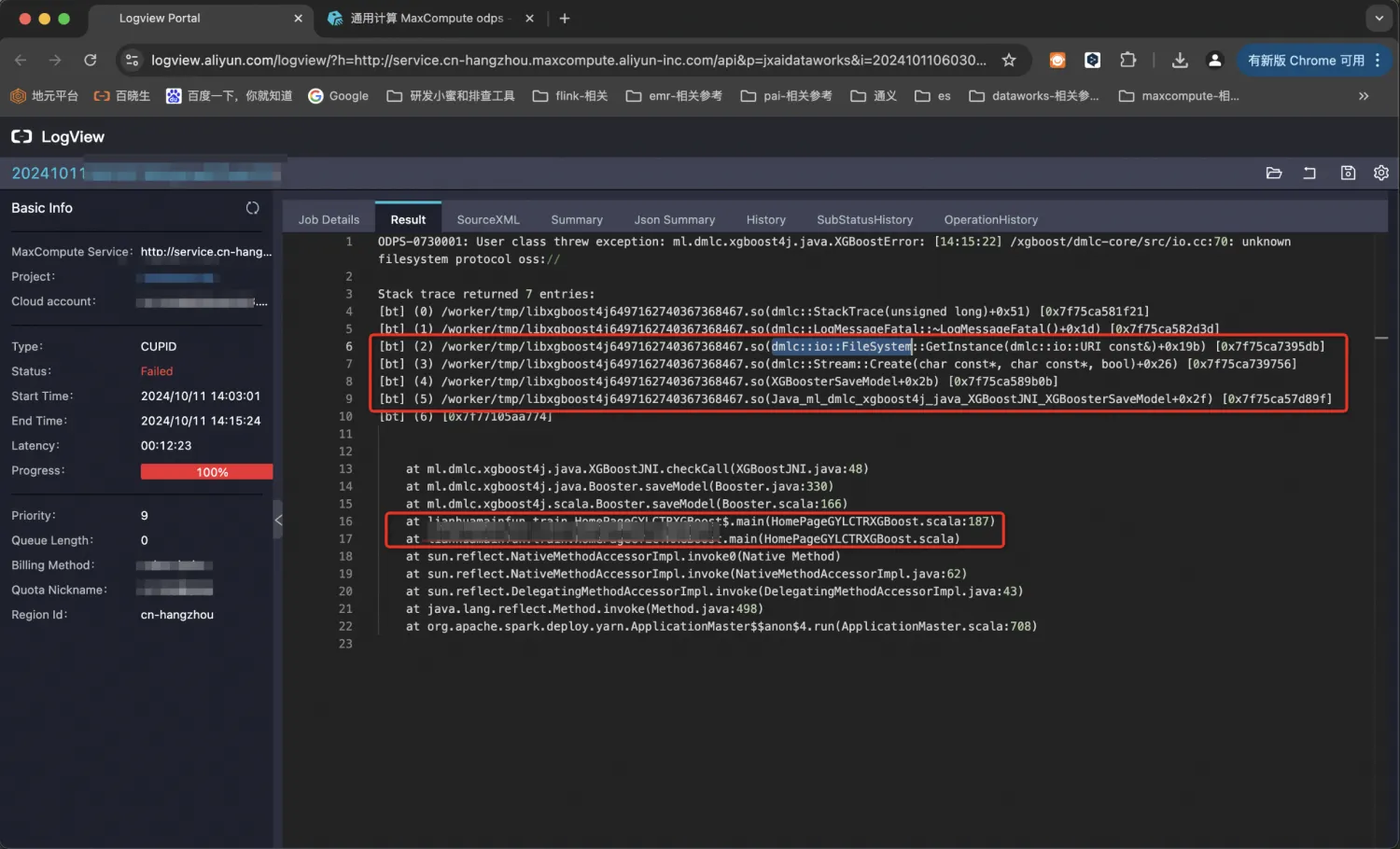
阿里云MaxCompute-XGBoost on Spark 极限梯度提升算法的分布式训练与模型持久化oss的实现与代码浅析
1. XGBoost简介 XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在GBDT框架的基础上实现机器学习算法。XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。XGBoost最初是一个研究项目,孵化于Distributed (Deep) Machine Learning Community (DMLC) ,由陈天奇博...
Spark SQL访问MaxCompute数据源
本文介绍如何使用云原生数据仓库 AnalyticDB MySQL 版Spark SQL读写MaxCompute数据。
如何使用MaxCompute访问外部数据源
Spark on MaxCompute目前已支持访问湖仓一体外部数据源,若您想将数据处理作业的环境从Spark更换为MaxCompute,无需再迁移Spark作业数据到MaxCompute,可直接进行访问,从而降低使用成本。本文为您介绍使用MaxCompute访问外部数据源的示例。
Spark on MaxCompute访问Lindorm报错连接超时
使用Spark on MaxCompute访问Lindorm实例时可能会出现Connection Timeout的报错,这可能涉及Spark on MaxCompute的网络架构和数据通信方式等多方面的影响。本文介绍出现Connection Timeout报错的原因和解决方法。
MaxCompute里如果我换成spark代码。昨天的功能可以实现吗?
请教一下,如果我换成spark代码。昨天的功能可以实现吗?后面用JDBC太慢了,最后还是执行错误,显示的也是网络错误,如果是直接写spark代码直接写进目标表,这种以前有小伙伴试验过能行不,是不是只有包年包月的才可以,后付费模式是不行的是吗,这个需要dataworks的版本是包年包月的是吧这个命令是在哪里执行的呢,我看如果是自己的就是直接在服务器运行,咋们这是在哪里运行呢?还有就是这个能不能和数....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache sparkmaxcompute相关内容
- maxcompute apache spark配置
- maxcompute apache spark数据
- maxcompute apache spark作业
- maxcompute apache spark运行模式
- maxcompute apache spark参数
- maxcompute apache spark driver
- maxcompute apache spark executor内存不足
- maxcompute apache spark申请资源
- maxcompute apache spark oom
- maxcompute apache spark jar包打包
- maxcompute apache spark任务参数
- maxcompute apache spark dataworks流程
- maxcompute apache spark mc节点资源参数
- maxcompute apache spark客户端
- maxcompute apache spark场景
- maxcompute apache spark是什么意思
apache spark您可能感兴趣
- apache spark向量
- apache spark引擎
- apache spark优化
- apache spark SQL
- apache spark框架
- apache spark数据
- apache spark rdd
- apache spark dstream
- apache spark Dataframe
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark任务
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark操作
- apache spark技术
- apache spark yarn
- apache spark程序
- apache spark报错
- apache spark大数据分析
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注