
「大数据系列」:Apache Hive 分布式数据仓库项目介绍
Apache Hive™数据仓库软件有助于读取,编写和管理驻留在分布式存储中的大型数据集并使用SQL语法进行查询Hive 特性Hive构建于Apache Hadoop™之上,提供以下功能:通过SQL轻松访问数据的工具,从而实现数据仓库任务,如提取/转换/加载(ETL),报告和数据分析。一种在各种数据格式上强加结构的机制访问直接存储在Apache HDFS™或其他数据存储系统(如Apache HB....

应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
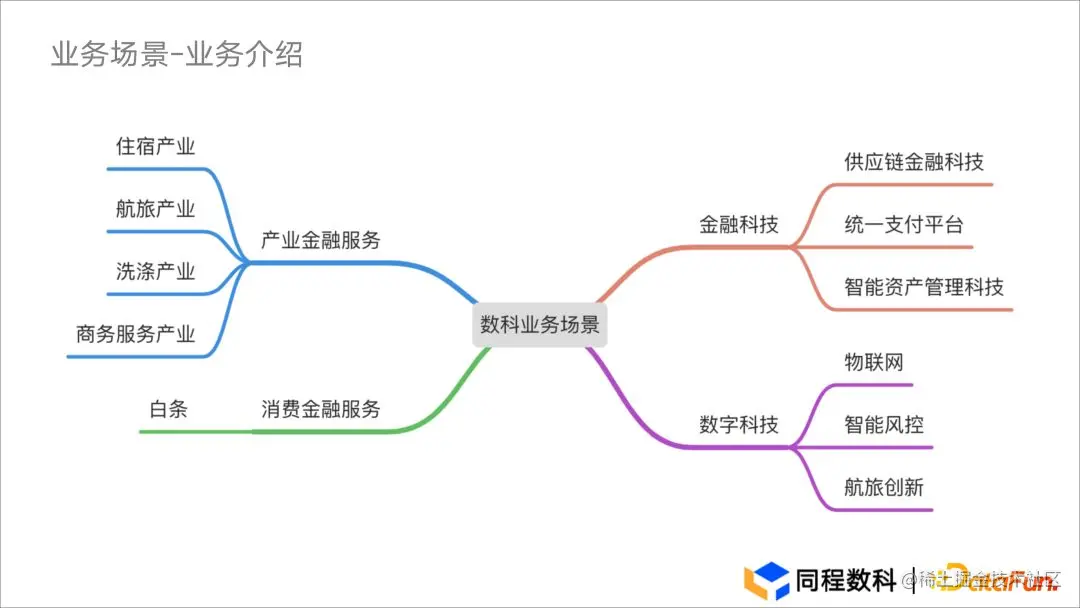
导读:同程数科成立于 2015 年,是同程集团旗下的旅游产业金融服务平台。2020 年,同程数科基于 Apache Doris 丰富的数据接入方式、优异的并行运算能力、极简运维等特性,引入 Apache Doris 进行数仓架构2.0 的搭建。本文详细讲述了架构1.0 到 2.0 的演进过程及 Doris 的应用实践,希望对大家有所帮助。作者|同程数科大数据高级工程师 王星业务背景业务介绍同程数....
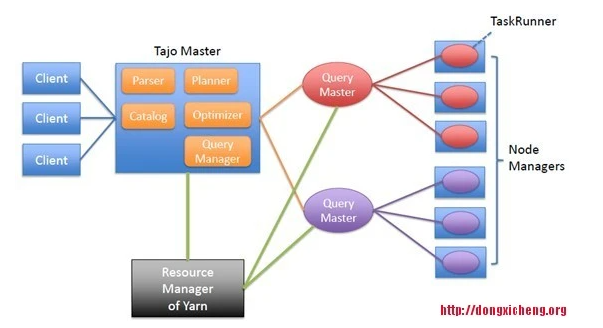
Apache Tajo:一个运行在YARN上支持SQL的分布式数据仓库
1. 背景当前,Hadoop之上的SQL引擎已经非常多了,概括起来有两类系统,分别是:(1)将SQL转化为MapReduce。典型代表是Apache Hive,这种系统的特点是扩展性和容错性好,但性能低下。为了弥补SQL on MapReduce的不足,google提出了Tenzing(见参考资料[3]),与Hive不同,Tenzing充分借鉴了MapReduce和DataBase的优势,首先,....
Apache iceberg:Netflix 数据仓库的基石
Apache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。 本文由 Ryan Blue 分享,他在 Netflix 从事开源数据项目,是 Apache Iceberg 的最初创建者之一,也是 Apache....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache您可能感兴趣
- Apache elasticsearch
- Apache方案
- Apache分析
- Apache doris
- Apache库
- Apache命令
- Apache服务器
- Apache数据处理
- Apache flink
- Apache湖仓
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache实践
- Apache应用
- Apache日志

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注