
深度学习之自然语言预训练模型
自然语言预训练模型是近年来自然语言处理(NLP)领域取得显著进展的核心技术之一。预训练模型通过在大规模未标注文本数据上进行自监督学习,学到通用的语言表示,然后在下游任务上进行微调(Fine-tuning),从而显著提升了各种NLP任务的性能。以下是对这一领域的详细介绍: 1. 预训练模型概述 预训练模型通常分为两个阶段: 预训练阶段:在大规模未标注文本数据上进行自监督学习...
使用Python实现深度学习模型:迁移学习与预训练模型
迁移学习是一种将已经在一个任务上训练好的模型应用到另一个相关任务上的方法。通过使用预训练模型,迁移学习可以显著减少训练时间并提高模型性能。在本文中,我们将详细介绍如何使用Python和PyTorch进行迁移学习,并展示其在图像分类任务中的应用。 什么是迁移学习? 迁移学习的基本思想是利用在大规模数据集(如ImageNet&#x...

训练你自己的自然语言处理深度学习模型,Bert预训练模型下游任务训练:情感二分类
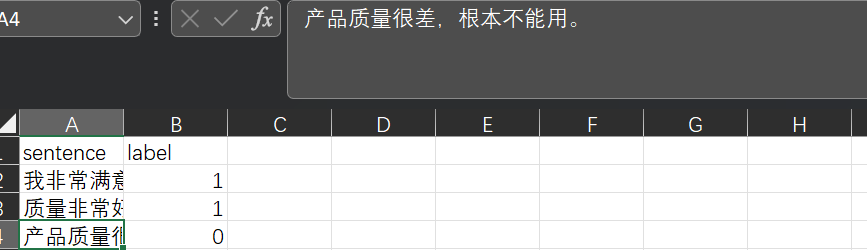
基础介绍:Bert模型是一个通用backbone,可以简单理解为一个句子的特征提取工具更直观来看:我们的自然语言是用各种文字表示的,经过编码器,以及特征提取就可以变为计算机能理解的语言了下游任务:提取特征后,我们便可以自定义其他自然语言处理任务了,以下是一个简单的示例(效果可能不好,但算是一个基本流程)数据格式:模型训练:我们来训练处理句子情感分类的模型,代码如下import torch fro....
【深度学习】实验11 使用Keras预训练模型完成猫狗识别
使用Keras预训练模型完成猫狗识别VGG16是一种深度卷积神经网络,由牛津大学计算机视觉研究小组在2014年提出。它是ImageNet图像识别竞赛的冠军,拥有较好的图像识别和分类效果。VGG16架构非常简单,特征提取部分由13个卷积层和5个池化层组成,分类器部分有3个全连接层。VGG16中的卷积层均为3×3的卷积核,池化层为2×2的最大池化,卷积核数量逐层增加,以提取越来越复杂的特征。VGG1....
人工智能领域:面试常见问题超全(深度学习基础、卷积模型、对抗神经网络、预训练模型、计算机视觉、自然语言处理、推荐系统、模型压缩、强化学习、元学习)
人工智能领域:面试常见问题 1.深度学习基础 为什么归一化能够提高求解最优解的速度?为什么要归一化?归一化与标准化有什么联系和区别?归一化有哪些类型?Min-max归一化一般在什么情况下使用?Z-score归一化在什么情况下使用?学习率过大或过小对网络会有什么影响?batch size...
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。 1.ERNIE-Doc: A Retrospective Long-Document Modeling Transformer 1.1. ERNIE-Doc简介 经典的Transformer在处理数据时,会将文本数据按照固定长度进行截断,这个看起来比...
![深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。](https://ucc.alicdn.com/fnj5anauszhew_20230529_5dfe9e7e0fad4be185d806d649fbe8ab.png)
深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解
深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解 后预训练模型时代 1.ERINE 1.1 ERINE简介 ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。在模型结构方面,它采用了Transformer的Encoder部分作为模...
![深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解](https://ucc.alicdn.com/fnj5anauszhew_20230528_47b9af59d4344b79843eaa18a3313d0e.png)
深度学习进阶篇-预训练模型4:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解
深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解 1.SpanBERT: Improving Pre-training by Representing and Predicting Spans 1.1. SpanBERT的技术改进点 相比于BERT,SpanBERT主要是在预训练阶段进行了调整,如...

深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解
深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解 1.XLNet:Generalized Autoregressive Pretraining for Language Understanding 1.1. 从AR和AE模型到XLNet模型 自回归模型(Autoregressiv...
![深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解](https://ucc.alicdn.com/fnj5anauszhew_20230526_a8ef174625f448c29fd038a273cbb6e5.png)
深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解
深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解 1.Transformer-XL: Attentive Language Models Beyonds a Fixed-Length Context 1.1. Transformer-XL简介 在正式讨论 Transformer-XL 之前,我们先来看看...
![深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解](https://ucc.alicdn.com/fnj5anauszhew_20230525_c86f2563fe3443868e28afc071677831.png)
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注