
RDS IO加速、IO突发与写优化更名
为提升产品功能命名的准确性与国际通用性,阿里云将于2025年04月27日对RDS MySQL IO加速、IO突发与写优化功能进行标准化命名调整。本次调整仅涉及功能更名,不改变功能逻辑,您无需进行任何业务适配操作。
Spark SQL诊断优化
云原生数据仓库 AnalyticDB MySQL 版推出Spark SQL诊断功能,若您提交的Spark SQL存在性能问题,您可以根据诊断信息快速定位、分析并解决性能瓶颈问题,优化Spark SQL。本文主要介绍如何进行Spark SQL性能诊断以及性能诊断的示例。
如何使用B-tree并发控制优化机制
PolarDB MySQL版优化了B-tree索引的并发控制机制,有效地提升了高并发读写场景下的性能。本文介绍了B-tree并发控制优化的使用方法和使用该机制的限制和前提条件等内容。
一文带你了解MySQL之基于成本的优化
一、连接查询的成本1.1 准备数据连接查询至少是要有两个表的,只有一个demo8表是不够的,所以为了故事的顺利发展,我们直接构造二个和demo8表一模一样的s1表和s2表mysql> create table s1 ( id int not null auto_increment, key1 varchar(100), &am...
一文带你了解MySQL之基于成本的优化
一、什么是成本我们之前老说MySQL执行一个查询可以有不同的执行方案,它会选择其中成本最低,或者说代价最低的那种方案去真正的执行查询。不过我们之前对成本的描述是非常模糊的,其实在MySQL中一条查询语句的执行成本是由下边这两个方面组成的:I/O成本我们的表经常使用的MyISAM、InnoDB存储引擎都是将数据和索引都存储到磁盘上的,当我们想查询表中的记录时,需要先把数据或者索引加载到内存中然后再....
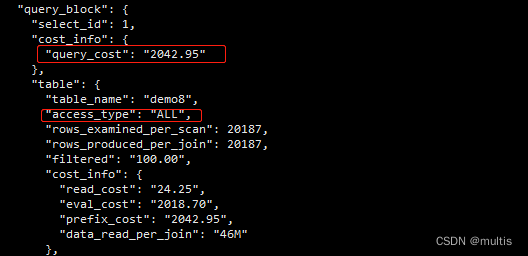
mysql基于成本的优化(1)---mysql进阶(四十一)
前面我们说了join查询原理,最基本的是嵌套查询,这种不推荐,如果数据量庞大,因为内存是有限的,不能放下所有的数据,可能查询到后面的时候,前面的数据就从内存从释放,为了减少磁盘的查询次数,有了join buffer这个缓存区,专门放被驱动表的数据,用来匹配查询出来的驱动表数据是否符合,当然还是建议用索引来查询。Join原理(2)--连接原理(四十)基于成本的优化前面我们都说mysql优化器,每次....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云数据库 RDS MySQL 版优化相关内容
- 京东云数据库 RDS MySQL 版优化
- 面试云数据库 RDS MySQL 版优化
- 云数据库 RDS MySQL 版分页优化
- 云数据库 RDS MySQL 版优化功能
- 云数据库 RDS MySQL 版数据优化
- 云数据库 RDS MySQL 版优化方案
- 云数据库 RDS MySQL 版日志优化
- 云数据库 RDS MySQL 版优化办法
- 云数据库 RDS MySQL 版概述优化
- 云数据库 RDS MySQL 版排序优化
- 云数据库 RDS MySQL 版join优化
- 云数据库 RDS MySQL 版优化原则
- 云数据库 RDS MySQL 版sql优化
- 云数据库 RDS MySQL 版explain优化
- 云数据库 RDS MySQL 版优化实践
- 云数据库 RDS MySQL 版优化应用
- 云数据库 RDS MySQL 版查询优化优化
- 优化云数据库 RDS MySQL 版
- 优化云数据库 RDS MySQL 版调优
- 云数据库 RDS MySQL 版协同作战优化
- 云数据库 RDS MySQL 版redis优化
- 云数据库 RDS MySQL 版优化实战
- 云数据库 RDS MySQL 版优化分页
- 云数据库 RDS MySQL 版优化数据统计
- 云数据库 RDS MySQL 版优化实录
- 云数据库 RDS MySQL 版数据量优化
- 云数据库 RDS MySQL 版索引优化数据库
- 日常工作云数据库 RDS MySQL 版优化
- 云数据库 RDS MySQL 版配置优化
- 云数据库 RDS MySQL 版分组分页优化
云数据库 RDS MySQL 版更多优化相关
- 云数据库 RDS MySQL 版子查询优化
- 云数据库 RDS MySQL 版排序分组优化
- 云数据库 RDS MySQL 版分组优化
- 云数据库 RDS MySQL 版优化脚本
- 云数据库 RDS MySQL 版优化cpu
- 云数据库 RDS MySQL 版优化内存
- 云数据库 RDS MySQL 版优化解析
- 云数据库 RDS MySQL 版运维优化
- 云数据库 RDS MySQL 版优化测试
- 云数据库 RDS MySQL 版主从复制优化
- 云数据库 RDS MySQL 版优化索引
- 云数据库 RDS MySQL 版order优化
- 云数据库 RDS MySQL 版优化配置
- 云数据库 RDS MySQL 版架构优化
- 云数据库 RDS MySQL 版分析优化
- 云数据库 RDS MySQL 版性能优化优化
- 云数据库 RDS MySQL 版优化查询优化
- 云数据库 RDS MySQL 版优化步骤
- 云数据库 RDS MySQL 版内存优化
- 数据库云数据库 RDS MySQL 版优化
- 云数据库 RDS MySQL 版优化学习
- 云数据库 RDS MySQL 版优化explain
- 云数据库 RDS MySQL 版大表优化方案
- 云数据库 RDS MySQL 版系统优化
- 云数据库 RDS MySQL 版硬件优化
- 云数据库 RDS MySQL 版优化器优化
- 云数据库 RDS MySQL 版技术优化
- 云数据库 RDS MySQL 版优化系统
- 云数据库 RDS MySQL 版优化笔记
- 云数据库 RDS MySQL 版优化参数
云数据库 RDS MySQL 版您可能感兴趣
- 云数据库 RDS MySQL 版自动同步
- 云数据库 RDS MySQL 版主实例
- 云数据库 RDS MySQL 版购买
- 云数据库 RDS MySQL 版读写分离
- 云数据库 RDS MySQL 版数据
- 云数据库 RDS MySQL 版数据迁移
- 云数据库 RDS MySQL 版sqlserver
- 云数据库 RDS MySQL 版sql
- 云数据库 RDS MySQL 版方法
- 云数据库 RDS MySQL 版代理
- 云数据库 RDS MySQL 版数据库
- 云数据库 RDS MySQL 版安装
- 云数据库 RDS MySQL 版同步
- 云数据库 RDS MySQL 版连接
- 云数据库 RDS MySQL 版mysql
- 云数据库 RDS MySQL 版查询
- 云数据库 RDS MySQL 版报错
- 云数据库 RDS MySQL 版配置
- 云数据库 RDS MySQL 版rds
- 云数据库 RDS MySQL 版索引
- 云数据库 RDS MySQL 版flink
- 云数据库 RDS MySQL 版cdc
- 云数据库 RDS MySQL 版表
- 云数据库 RDS MySQL 版实例
- 云数据库 RDS MySQL 版备份
- 云数据库 RDS MySQL 版操作
- 云数据库 RDS MySQL 版linux
- 云数据库 RDS MySQL 版polardb
- 云数据库 RDS MySQL 版阿里云
- 云数据库 RDS MySQL 版php

