
432.4 FPS 快STDC 2.84倍 | LPS-Net 结合内存、FLOPs、CUDA实现超快语义分割模型(二)
3、实验3.1、Lightweight Designs3.2、SOTA对比3.3、速度对比3.4、可视化对比4、参考[1].Lightweight and Progressively-Scalable Networks for Semantic Segmentation5、推荐阅读YOLOU开源 | 汇集YOLO系列所有算法,集算法学习、科研改进、落地于一身!MobileDenseNet | 一....
432.4 FPS 快STDC 2.84倍 | LPS-Net 结合内存、FLOPs、CUDA实现超快语义分割模型(一)
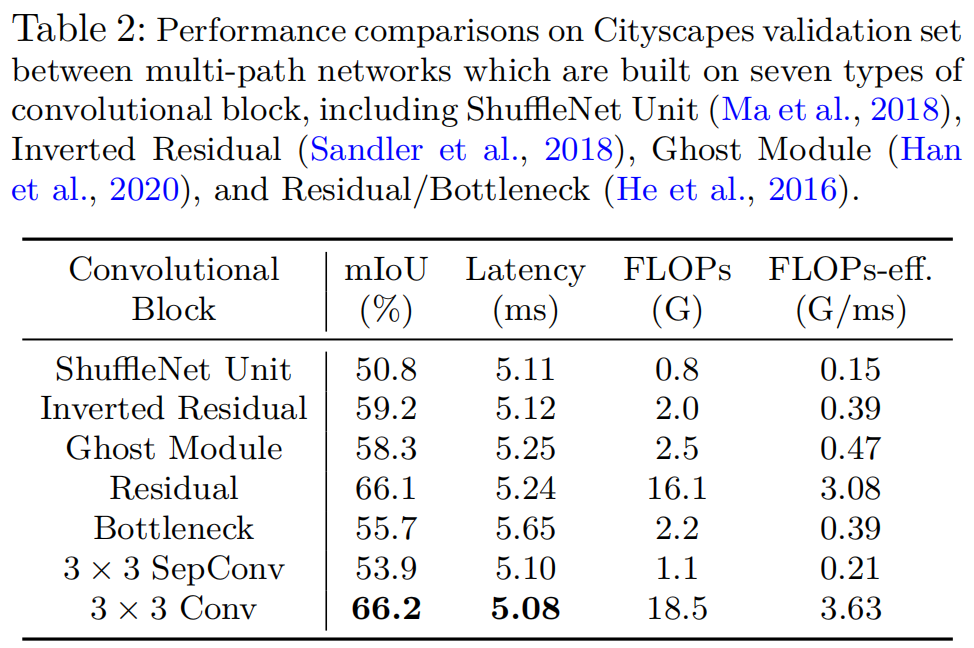
多尺度学习框架被认为是促进语义分割的一类模型。然而,这个问题并不想象的那么轻描淡写,特别是对于现实应用的部署,这通常需要高效率的推理延迟。在本文中,作者从轻量级语义分割的角度彻底分析了卷积块的设计(卷积类型和卷积中的通道数)以及跨多个尺度的交互方式。通过如此深入的比较,作者总结出3个原则,并相应地设计了轻量级和渐进式可扩展网络(LPSNet),它以贪婪的方式扩展了网络的复杂性。从技术上讲,LPS....

【CUDA学习笔记】第五篇:内存以及案例解释(附案例代码下载方式)(二)
3、向量点乘和矩阵乘法的例子3.1、向量点乘 两个向量的点乘是重要的数学运算,也将会解释CUDA编程中的一个重要概念:归约运算。两个向量的点乘运算定义如下: 其实显示的应用中真正的向量肯定会很长很长,两个向量里面有多个元素,而不仅仅只有三个。最终也会将多个乘法结果累加(归约运算)起来,而不仅仅是3个。现在,你看下这个运算,它和之前的元素两两相加的向量加法操....
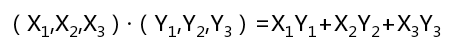
【CUDA学习笔记】第五篇:内存以及案例解释(附案例代码下载方式)(一)
1、常量内存 NVIDIA GPU卡从逻辑上对用户提供了64KB的常量内存空间,可以用来存储内核执行期间所需要的恒定数据。常量内存对一些特定情况下的小数据量的访问具有相比全局内存的额外优势。使用常量内存也一定程度上减少了对全局内存的带宽占用。 话不多说,直接coding吧:#include "stdio.h" #include<iostream>...

432.4 FPS 快STDC 2.84倍 | LPS-Net 结合内存、FLOPs、CUDA实现超快语义分割模型
多尺度学习框架被认为是促进语义分割的一类模型。然而,这个问题并不想象的那么轻描淡写,特别是对于现实应用的部署,这通常需要高效率的推理延迟。在本文中,作者从轻量级语义分割的角度彻底分析了卷积块的设计(卷积类型和卷积中的通道数)以及跨多个尺度的交互方式。通过如此深入的比较,作者总结出3个原则,并相应地设计了轻量级和渐进式可扩展网络(LPSNet),它以贪婪的方式扩展了网络的复杂性。从技术上讲,LPS....


CUDA编程(五)关注内存的存取模式
CUDA编程(五) 关注内存的存取模式 上一篇博客我们使用Thread完成了简单的并行加速,虽然我们的程序运行速度有了50甚至上百倍的提升,但是根据内存带宽来评估的话我们的程序还远远不够, 除了通过Block继续提高线程数量来优化性能,这次想给大家先介绍一个访存方面非常重要的优化,同样可以大幅提高程序的性能~ 什么样的存取模式是高效的? 大家知道一般显卡上的内存是 DRAM,因此最...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。