
深度学习中的正则化技术:防止过拟合的利器
在深度学习的实践中,构建一个既能捕捉数据复杂模式又具备良好泛化能力的模型是一项挑战。随着模型层数的增加,参数数量也随之增长,这虽然提升了模型的学习能力和表达能力,但也增加了过拟合的风险。过拟合发生时,模型在训练数据上的表现可能非常出色,但在未见过的测试数据上却表现不佳,这是因为模型过度学习了训练数据...
深度学习中的正则化技术
深度学习模型因其强大的特征学习能力而广受关注,但这种能力有时会导致模型在训练数据上过度优化,而在未见数据上泛化性能下降,即所谓的过拟合问题。为了解决这一问题,研究者们提出了多种正则化技术,以限制模型复杂度,提高泛化能力。 L1和L2正则化是最常见的正则化技术之一。L1正则化,也称为Lasso回归&#...
深度学习中的正则化技术:防止过拟合的策略
深度学习模型在处理复杂数据时展现出了前所未有的能力,尤其是在图像识别、语音处理和自然语言理解等领域。然而,随着模型复杂度的增加,过拟合成为了一个不可忽视的问题。过拟合发生在模型对训练数据学得“太好”,以至于无法很好地泛化到新的、未见过的数据上。为了解决这一难题,研究者们提出了多种正则化技术。 L1和L2正则化是最常见的正则化方...
【深度学习】3、正则化技术全面了解(二)
6、 Dropout Bagging是通过结合多个模型降低泛化误差的技术,主要的做法是分别训练几个不同的模型,然后让所有模型表决测试样例的输出。而Dropout可以被认为是集成了大量深层神经网络的Bagging方法, 因此它提供了一种廉价的Bagging集成近似方法,能够训练和评估值数据数量的神经网络。 Dropout指暂时丢弃一部分神经元及其....
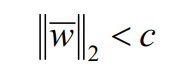
【深度学习】3、正则化技术全面了解(一)
1、简介 正则化就是结构风险最小化策略的实现, 是在经验风险最小化的情况下加入一个正则化项或者罚项。 正则化技术令参数数量多于输入数据量的网络避免产生过拟合现象。正则化通过避免训练完美拟合数据样本的系数而有助于算法的泛化。为了防止过拟合, 增加训练样本是一个好的解决方案。此外, 还可使用数据增强、 L1正则化、 L2 正则化、 Dropout、....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
深度学习更多技术相关
- 深度学习技术医疗应用
- 深度学习技术卷积神经网络
- 深度学习性能技术
- 深度学习正则化技术过拟合
- 深度学习正则技术
- 深度学习数据增强技术
- 深度学习技术数据
- 深度学习技术图像
- 深度学习技术训练
- 深度学习技术前景
- 深度学习技术自动驾驶系统应用
- 深度学习技术智能
- 深度学习智能监控技术
- 深度学习图像识别技术进展
- 深度学习智能监控图像识别技术应用
- 深度学习技术智能监控
- 深度学习驱动技术
- 深度学习系统技术
- 智能深度学习技术
- 深度学习技术自然语言处理
- 深度学习ai技术
- 深度学习技术构建
- 深度学习推荐系统技术
- 深度学习技术代码
- 深度学习技术实战
- 深度学习技术机器
- 深度学习卷积神经网络技术
- 深度学习技术图像处理
- 深度学习技术洞察
- 开发深度学习技术

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注