
近端策略优化(PPO)算法的理论基础与PyTorch代码详解
近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度强化学习领域获得了广泛应用。特别是在大语言模型(LLM)的人类反馈强化学习(RLHF)过程中,PPO扮演着核心角色。本文将深入探讨PPO的基本原理和实现细节。 PPO属于在线策略梯度方法的范畴。其基础形式可以用带有优势函数的策略梯度表达式来描述: 策略梯度的基础表达式(包含优.....
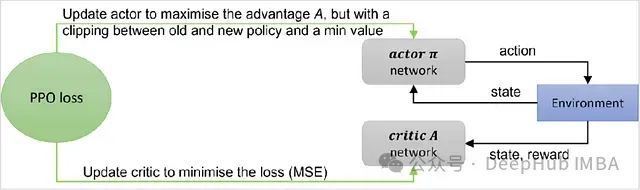
深度强化学习中SAC算法:数学原理、网络架构及其PyTorch实现
深度强化学习是人工智能领域最具挑战性的研究方向之一,其设计理念源于生物学习系统从经验中优化决策的机制。在众多深度强化学习算法中,软演员-评论家算法(Soft Actor-Critic, SAC)因其在样本效率、探索效果和训练稳定性等方面的优异表现而备受关注。 传统的深度强化学习算法往往在探索-利用权衡、训练稳定性等方面面临挑战。SAC算法通过引入最大熵强化学习框架,在策略优化过程中自动调节探索程....

【从零开始学习深度学习】42. 算法优化之AdaDelta算法【基于AdaGrad算法的改进】介绍及其Pytorch实现
1. AdaDelta算法介绍 2. 从零实现AdaDelta算法 AdaDelta算法需要对每个自变量维护两个状态变量,即st和Δxt。我们按AdaDelta算法中的公式实现该算法。 ...

【从零开始学习深度学习】41. 算法优化之RMSProp算法【基于AdaGrad算法的改进】介绍及其Pytorch实现
1. RMSProp算法介绍 %matplotlib inline import math import to...

【从零开始学习深度学习】43. 算法优化之Adam算法【RMSProp算法与动量法的结合】介绍及其Pytorch实现
1. Adam算法介绍 2. 从零实现Adam算...

【从零开始学习深度学习】40. 算法优化之AdaGrad算法介绍及其Pytorch实现
1. AdaGrad算法介绍 1.1 AdaGrad算法特点 需要强调的是,小批量随机梯度按元素平方的累加变量st出现在学习率的分母项中。因此,如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素...

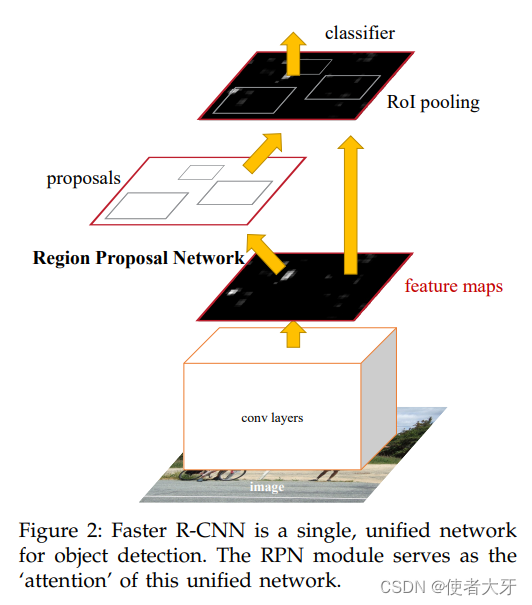
RPN(Region Proposal Networks)候选区域网络算法解析(附PyTorch代码)
0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。 本文基于论文Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks对RPN候选区...
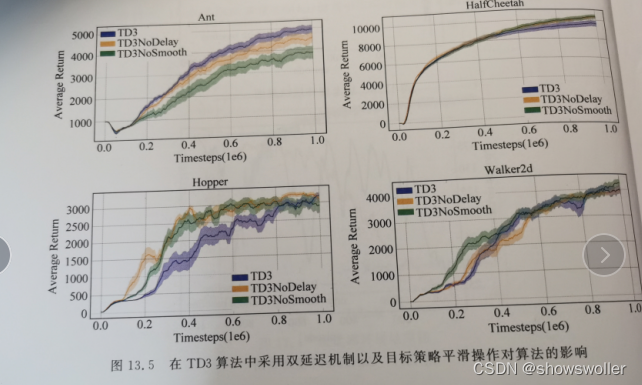
【PyTorch深度强化学习】TD3算法(双延迟-确定策略梯度算法)的讲解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言~~~一、双延迟-确定策略梯度算法在DDPG算法基础上,TD3算法的主要目的在于解决AC框架中,由函数逼近引入的偏差和方差问题。一方面,由于方差会引起过高估计,为解决过高估计问题,TD3将截断式双Q学习(clipped Double Q-Learning)应用于AC框架;另一方面,高方差会引起误差累积,为解决误差累积问题,TD3分别采用延迟策略更新和添加噪声平滑....
【PyTorch深度强化学习】DDPG算法的讲解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言留下QQ~~~一、DDPG背景及简介 在动作离散的强化学习任务中,通常可以遍历所有的动作来计算动作值函数q(s,a)q(s,a),从而得到最优动作值函数q∗(s,a)q∗(s,a) 。但在大规模连续动作空间中,遍历所有动作是不现实,且计算代价过大。针对解决连续动作空间问题,2016年TP Lillicrap等人提出深度确定性策略梯度算法(Deep Determ....

基于Pytorch的LSTM物品移动预测算法
实验目的:实现了一个多层双向LSTM模型,并用于训练一个时间序列预测任务训练程序:#!/usr/bin/env python # -*- coding: utf-8 -*- import os import torch import torch.nn as nn import torch.optim as optim import numpy as np from torch.utils.dat....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注