
python语言通过简单爬虫实例了解文本解析与读写
''' fb.write(headertxt) # 6.2 写文件主体 fb.write('\n') fb.write(sn) cha = link[1].replace(sn,''); cha = cha.replace('第章 ','') fb.write(' ') fb.write(cha) fb.writ...
Python爬虫:scrapy利用html5lib解析不规范的html文本
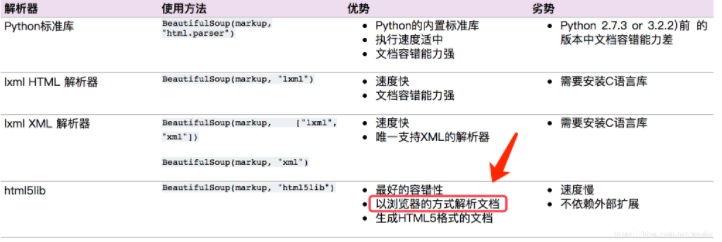
问题当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,程序却解析不到在chrome、火狐测试都有这个情况。出现这种原因是因为浏览器会对html文本进行一定的规范化scrapy 使用的解析器是 lxml ,下面使用lxml解析,只是函数表达不一样,xpath和css选择器的语法一样安装解析器pip install beautifulsoup4 lxml html5li....
Python爬虫,用第三方库解决下载网页中文本的问题
还在辛辛苦苦的查找网页规律,写正则或者其他方式去匹配文本内容吗?还在纠结怎么去除小说网站的其他字符吗? 先来看看下面2张图,都是某小说网站的小说内容 怎么样,是不是很简洁!这就是今天给大家介绍的库,newspaper库! newspaper python3.x安装: pip install newspaper3k python2.7安装: pip install newsp...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注