
阿里云E-MapReduce Spark SQL 作业配置
.注意:Spark SQL 提交作业的模式默认是 yarn-client` 模式。 2.进入阿里云E-MapReduce控制台作业列表。 3.单击该页右上角的创建作业,进入创建作业页面。 4.填写作业名称。 5.选择 Spark SQL 作业类型,表示创建的作业是一个 Spark SQL 作业。Spark SQL 作业在 E-MapReduce 后台使用以下的方式提交: spark-sql [o....
阿里云E-MapReduce Spark 作业配置
1.进入阿里云 E-MapReduce 控制台作业列表。 2.单击该页右上角的创建作业,进入创建作业页面。 3.填写作业名称。 4.选择 Spark 作业类型,表示创建的作业是一个 Spark 作业。Spark 作业在 E-MapReduce 后台使用以下的方式提交: spark-submit [options] --class [MainClass] xxx.jar args5.在应用参数选.....
阿里云E-MapReduce Pig 作业配置
E-MapReduce 中,用户申请集群的时候,默认为用户提供了 Pig 环境,用户可以直接使用 Pig 来创建和操作自己的表和数据。操作步骤如下。 1.用户需要提前准备好 Pig 的脚本,例如: /* Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreement.....
阿里云E-MapReduce Hive 作业配置
E-MapReduce 中,用户申请集群的时候,默认为用户提供了 Hive 环境,用户可以直接使用 Hive 来创建和操作自己的表和数据。操作步骤如下。 1.用户需要提前准备好 Hive SQL 的脚本,例如: USE DEFAULT; DROP TABLE uservisits; CREATE EXTERNAL TABLE IF NOT EXISTS uservisits (sourc...
阿里云E-MapReduce Hadoop MapReduce 作业配置
1.登录阿里云 E-MapReduce 控制台作业列表。 2.单击该页右上角的创建作业,进入创建作业页面。 3.填写作业名称。 4.选择 Hadoop 作业类型。表示创建的作业是一个 Hadoop Mapreduce 作业。这种类型的作业,其后台实际上是通过以下的方式提交的 Hadoop 作业。 hadoop jar xxx.jar [MainClass] -Dxxx ....5.在应用参数中填....
Hadoop MapReduce概念学习系列之作业配置(十七)
这些,只是一丁点而已。高手,一定要去深究。 本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5453379.html,如需转载请自行联系原作者
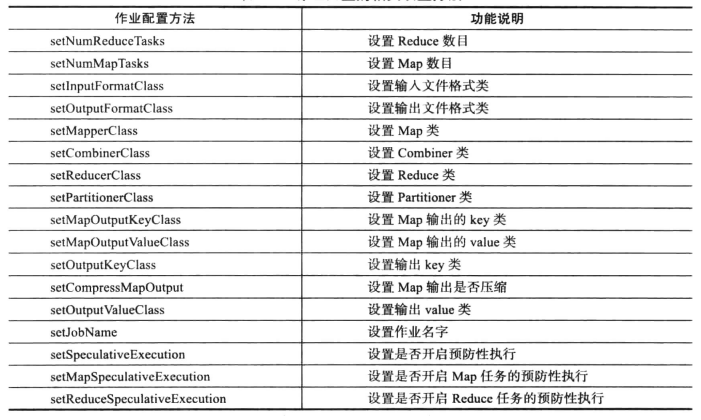
E-MapReduceHadoop MapReduce 作业配置是什么?
登录阿里云E-MapReduce 控制台作业列表。单击该页右上角的创建作业,进入创建作业页面。填写作业名称。选择 Hadoop 作业类型。表示创建的作业是一个 Hadoop Mapreduce 作业。这种类型的作业,其后台实际上是通过以下的方式提交的Hadoop 作业。hadoop jar xxx.jar [MainClass] -Dxxx .... 在 应用参数中填写提交该 job 需要提供的....
E-MapReduceHadoop MapReduce 作业配置是什么?
登录阿里云 E-MapReduce 控制台作业列表。单击该页右上角的[backcolor=transparent]创建作业,进入创建作业页面。填写作业名称。选择 Hadoop 作业类型。表示创建的作业是一个 Hadoop Mapreduce 作业。这种类型的作业,其后台实际上是通过以下的方式提交的 Hadoop 作业。[backcolor=transparent]hadoop jar xxx[b....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
- 开源大数据平台 E-MapReduce学习
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注