
极空间 NAS 上线“AI 实验室”功能:自然语言搜图、以图搜图、文字识别
在数字化时代,家庭私有云已经成为许多家庭数据存储的方案。北京天顶星智能信息技术有限公司推出的极空间NAS,凭借其卓越的产品工艺、安全可靠的性能、绿色环保的设计、多功能的操作界面以及低功耗高效能的特点,赢得了广泛的市场认可。2024年3月,极空间推出了全新的“AI 实验室”功能,这一创新举措不仅为用户带来了前所未有的便捷体验,也标志着极空间在AI NAS领域的新篇章。 “AI 实验室”功能的推出.....

自然语言开发AI应用,利用云雀大模型打造自己的专属AI机器人
如今,大模型层出不穷,这为自然语言处理、计算机视觉、语音识别和其他领域的人工智能任务带来了重大的突破和进展。大模型通常指那些参数量庞大、层数深、拥有巨大的计算能力和数据训练集的模型。 但不能不承认的是,普通人使用大模型还是有一定门槛的,首先大模型通常需要大量的计算资源才能进行训练和推理。这包括高性能的图形处理单元(GPU)或者专用的张量处理单元(TPU),以及大内存和高速存储器。说白了,本地...
【NLP】Datawhale-AI夏令营Day10打卡:微调ChatGLM2-6B
1. 学习内容AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程今天学习的是任务三:进阶实践 - 大模型方法微调方法介绍1️⃣ LoRA(Low-Rank Adaptation):基本思想是对模型的一部分进行低秩适应,即找到并优化那些对特定任务最重要的部分。也就是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些....

【NLP】Datawhale-AI夏令营Day8-10打卡:大模型基础Transformer
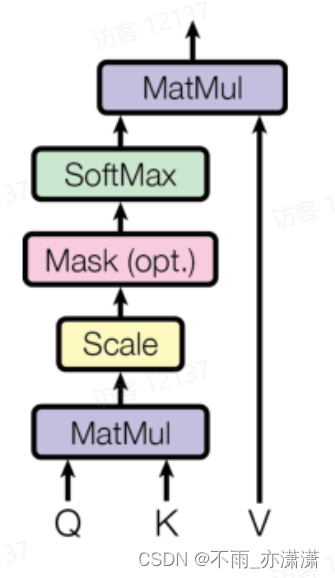
概要在编码器(encoder)和解码器(decoder)之间一般采用CNN或者RNN,而本研究提出了一种简单的仅仅基于注意力机制的架构——Transformer,主要用于机器翻译上面。Transformer是一种完全基于注意力的序列转录模型,它用 多头自注意力(multi-headed self-attention) 取代了编码器-解码器架构中最常用的循环层。Transformer, a seq....

【NLP】Datawhale-AI夏令营Day5打卡:预训练模型
1. 学习内容AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程✅ 预训练模型✒️ 预训练模型是人工智能发展的重要里程碑。✒️ 预训练模型(Pretrained Language Model) 指在大规模数据集上进行的无监督学习,通过学习数据中的潜在结构和规律,生成一种通用的语言表示能力。这种语言表示能力可以被用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。使用预训练....

【NLP】Datawhale-AI夏令营Day4打卡:预训练+微调范式
1. 学习内容AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程✅ Bert - 预训练+微调范式✏️:BERT(Bidirectional Encoder Representations from Transformers)的意思是基于双向Transformer的编码器表示,BERT的核心思想是使用双向Transformer来编码文本数据,从而获得文本中每个词的上下文相关的向量表示....
【NLP】Datawhale-AI夏令营Day3打卡:Bert模型
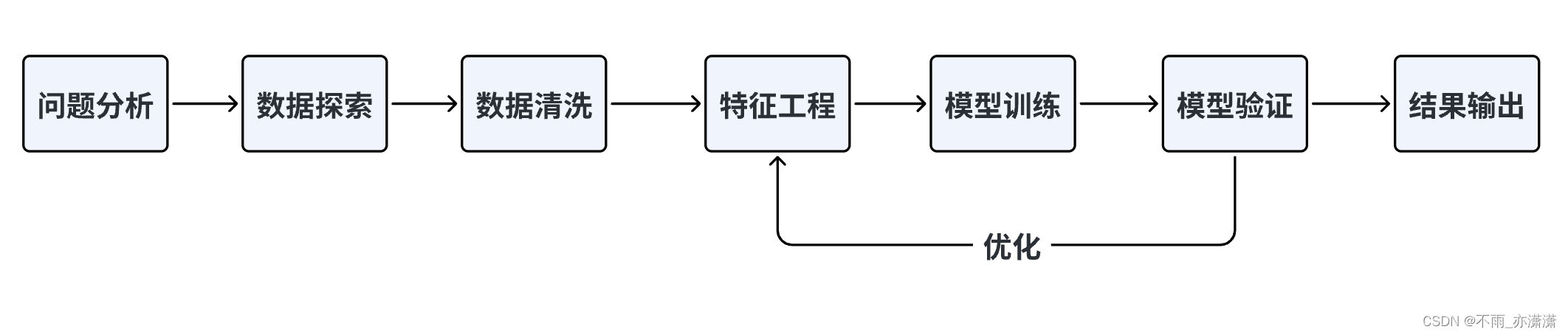
1. 学习内容AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程1.1 文本分类的两种实现思路✅ 特征提取 + 机器学习:数据预处理: 首先,对文本数据进行预处理,包括文本清洗(如去除特殊字符、标点符号)、分词等操作。可以使用常见的NLP工具包(如NLTK或spaCy)来辅助进行预处理。特征提取: 使用TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法将文本转换为向量表示。TF....
【NLP】Datawhale-AI夏令营Day2打卡:数据分析
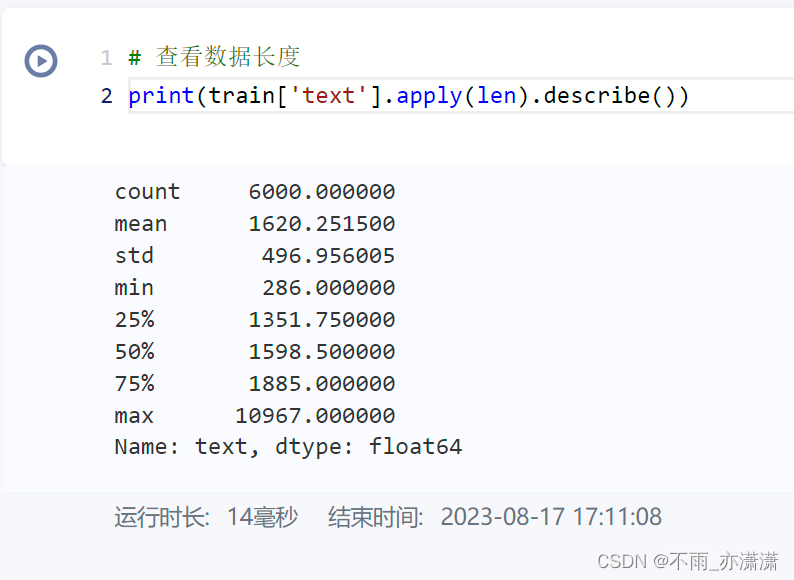
昨天学习了Python 数据分析相关的库(pandas和sklearn),文本特征提取的方法(基于TF-IDF提取和基于BOW提取,以及停用词的用法),划分数据集的方法,以及机器学习的模型。1. 学习内容AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程1.1 数据探索数据探索性分析,是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,对已有数据在尽量少的先验假设下通过....
【NLP】Datawhale-AI夏令营Day1打卡:文本特征提取
1. 学习内容AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程1.1 库本次项目主要会用到 pandas 和 scikit-learn 库。✅ pandaspandas 是 Python 语言的一个扩展程序库,用于数据分析。pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。pandas 可以从各种文件格式比如 CSV、JSON、SQL、Mi....

【NLP】Datawhale-AI夏令营Day6-7打卡:大模型
1. 学习内容AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程✅ 大模型的概念语言本质上是一个错综复杂的人类表达系统,受到语法规则的约束。因此,开发能够理解和精通语言的强大 AI 算法面临着巨大挑战。过去二十年,语言建模方法被广泛用于语言理解和生成,包括统计语言模型和神经语言模型。近些年,研究人员通过在大规模语料库上预训练 Transformer 模型产生了预训练语言模型(PLMs....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
自然语言处理您可能感兴趣
自然语言处理
