
20、 Python快速开发分布式搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
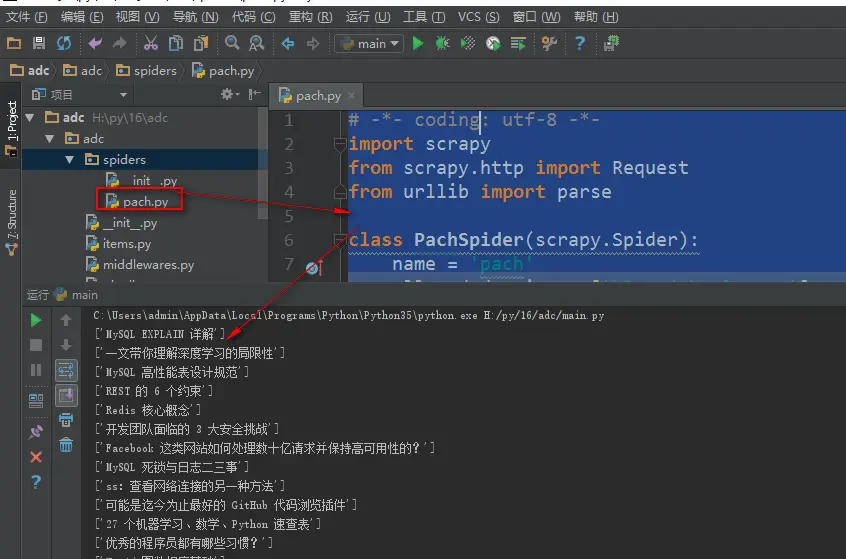
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield Request() parse.urljoin()方法,是urllib库下的方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接 # -*- ...
Python分布式抓取和分析京东商城评价
互联网购物现在已经是非常普遍的购物方式,在互联网上购买商品并且使用之后,很多人都会回过头来对自己购买的商品进行一些评价,以此来表达自己对于该商品使用后的看法。商品评价的好坏对于一个商品的重要性显而易见,大部分消费者都以此作为快速评判该商品质量优劣的方式。所以,与此同时,有些商家为了获得好评,还会做一些 "好评优惠" 或者 "返点" 活动来刺激消费者评价商品。 既然商品评价对于消费者选购商品而言至....

分布式单词发音抓取机器人
摘要 网络编程实验课程要求必须写一个套接字的应用程序,考虑到之前写过的单词发音抓取程序的效率比较低下,就顺便结合套接字做一个分布式的抓取软件。其中涉及到动态任务领取,负载均衡,多线程,加锁解锁,简单的HTML代码解析,文件读写等功能。程序还是使用Python完成,对于学习Python、套接字编程、分布式编程甚至集群编程都有一定的意义。 另外,...
Scrapy-Redis分布式抓取麦田二手房租房信息与数据分析
试着通过抓取一家房产公司的全部信息,研究下北京的房价。文章最后用Pandas进行了分析,并给出了数据可视化。 准备工作 麦田房产二手房页面(http://bj.maitian.cn/esfall/PG1)。 麦田房产租房页面(http://bj.maitian.cn/zfall/PG1)。 用Scrapy shell验证二手房XPath表达式 scrapy shel...
《Learning Scrapy》(中文版)第11章 Scrapyd分布式抓取和实时分析
序言第1章 Scrapy介绍第2章 理解HTML和XPath第3章 爬虫基础 第4章 从Scrapy到移动应用第5章 快速构建爬虫第6章 Scrapinghub部署第7章 配置和管理第8章 Scrapy编程第9章 使用Pipeline第10章 理解Scrapy的性能 第11章(完) Scrapyd分布式抓取和实时分析 我们已经学了很多东西。我们先学习了两种基础的网络技术,HTML和XPath,.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

阿里云分布式应用服务
企业级分布式应用服务 EDAS(Enterprise Distributed Application Service)是应用全生命周期管理和监控的一站式PaaS平台,支持部署于 Kubernetes/ECS,无侵入支持Java/Go/Python/PHP/.NetCore 等多语言应用的发布运行和服务治理 ,Java支持Spring Cloud、Apache Dubbo近五年所有版本,多语言应用一键开启Service Mesh。
+关注