
Scrapy框架简介
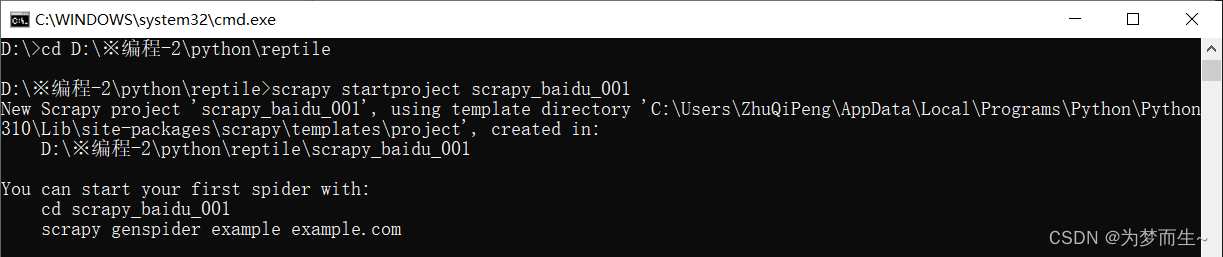
Scrapy框架简介 Scrapy是一个用于网络抓取的快速高级框架,用于从网站上抓取结构化的数据。它提供了多种类型的爬虫(Spiders)来定义如何抓取页面(Page)以及如何从页面中提取结构化数据(Scraped Item)。 创建一个Scrapy项目 首先,我们需要安装Scrapy...
【 ⑬】Scrapy库概述(简介、安装与基本使用)
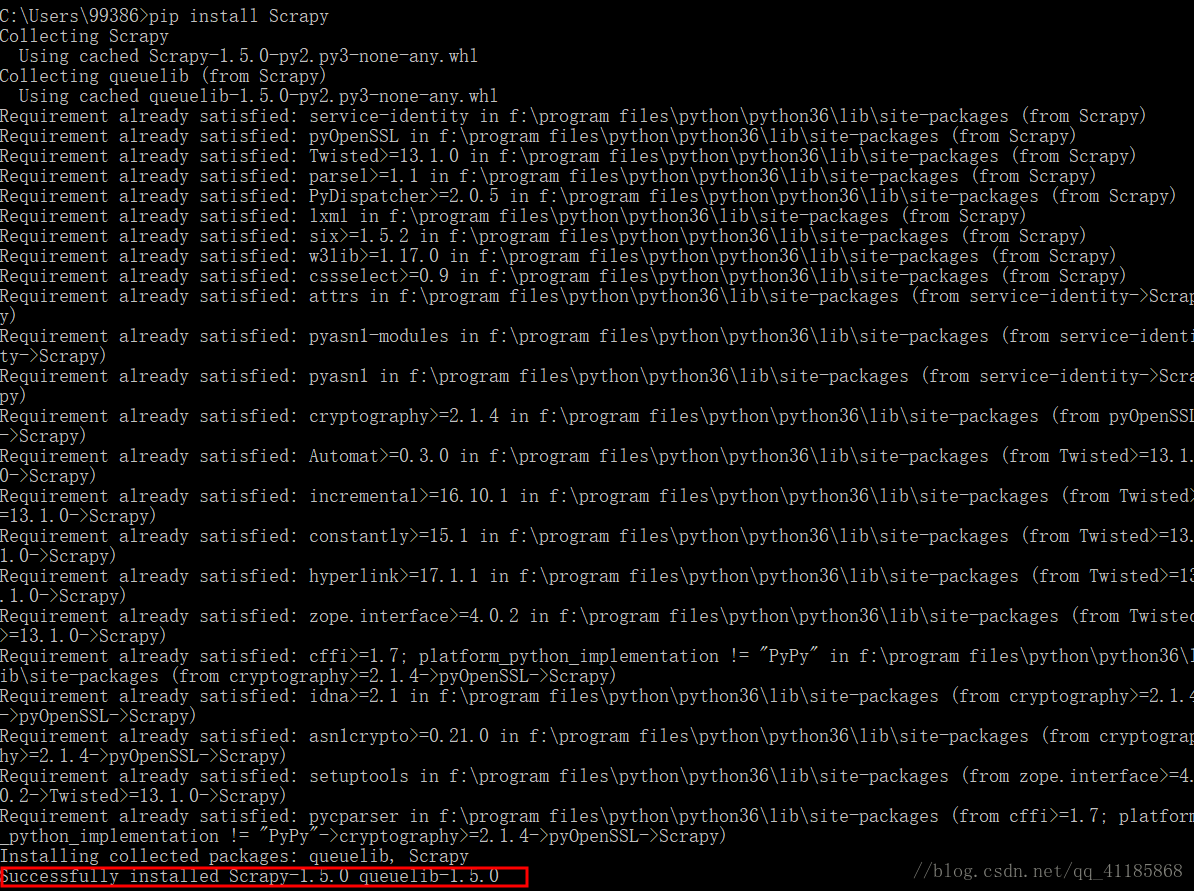
1 Scrapy简介Scrapy是一个用于快速、高效地抓取和提取数据的Python开发框架。它基于异步网络库Twisted,并提供了强大的自定义功能,使得开发者能够灵活地编写网络爬虫和数据抓取程序。以下是Scrapy框架的主要特点:基于异步的架构:Scrapy使用了异步的方式处理网络请求和响应,能够高效地处理大量的并发任务。强大的爬取能力:Scrapy支持多线程和分布式爬取,可以同时处理多个请求....
Crawler之Scrapy:Scrapy简介、安装、使用方法之详细攻略
scrapy简介 Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。 Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web....
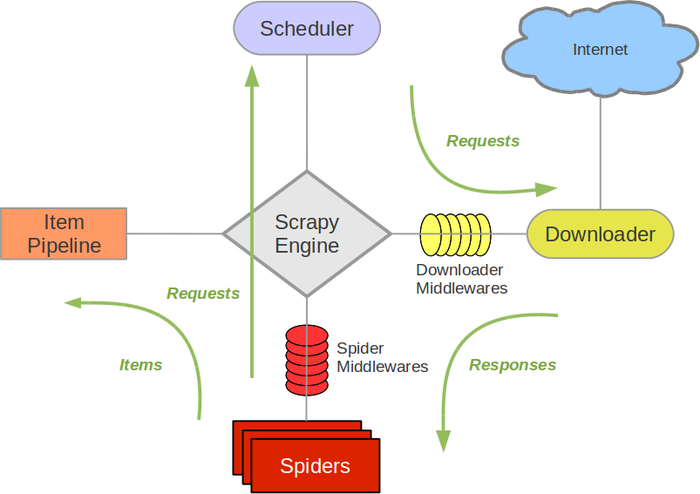
Scrapy 架构及数据流图简介
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中。本文着重介绍 Scrapy 架构及其组件之间的交互。 Scrapy 组件介绍 Scrapy Engine 引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。 调度器(Schedul...
Scrapy简介
Scrapy at a glance(Scrapy简介) Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注