
【 ⑭】Scrapy架构(组件介绍、架构组成和工作原理)
1 Scrapy的组件介绍Scrapy 是一个用于爬取网站数据和执行抓取任务的Python框架。它提供了一系列的组件,用于构建和管理爬虫项目。下面是对 Scrapy的几个重要组件的介绍:Spider(爬虫)Spider 是 Scrapy 的最基本组件,用于定义如何抓取特定网站的数据。每一个 Spider 都包含了一些用于抓取站点的初始URL和如何跟进页面中的链接的规则。Spider 通过解析页面....
scrapy中scrapy_redis分布式内置pipeline源码及其工作原理
scrapy_redis分布式实现了一套自己的组件,其中也提供了Redis数据存储的数据管道,位于scrapy_redis.pipelines,这篇文章主要分析器源码及其工作流程,源码如下: from scrapy.utils.misc import load_objectfrom scrapy.utils.serialize import&nbs...
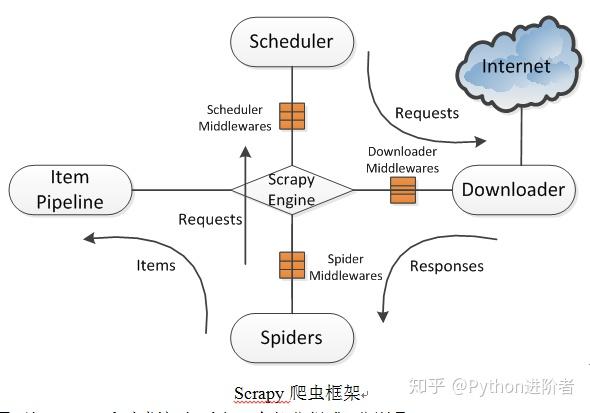
一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助。 1、Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且使用起来非常的方便。它可以应用在数据采集、数据挖掘、网络异常用户检测、存储数据等方面。 Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下图所示。 Scrapy爬虫框架2、由....
Scrapy进阶-命令行的工作原理(以runspider为例)
官方教程说当你写好自己的spiders如douban之后,你可以通过scrapy runspider/crawl douban启动你的爬虫。于是一开始的时候你就知道通过这个命令行来启动爬虫,但是你有没有想过当你敲下这行命令后,scrapy到底做了什么呢? 命令入口:cmdline.py 当你运行 scrapy command arg 这样的命令时,这里的 scrapy 实质是一个 python ....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注