
Python 爬虫:Spring Boot 反爬虫的成功案例
前言在当今数字化时代,网络数据成为了信息获取和分析的重要来源之一。然而,随着网络数据的广泛应用,爬虫技术也逐渐成为了互联网行业的热门话题。爬虫技术的应用不仅可以帮助企业获取有价值的信息,还可以用于数据分析、市场研究等领域。然而,随着爬虫技术的普及,越来越多的网站开始采取反爬虫措施,以保护其数据的安全...
使用Python打造爬虫程序之破茧而出:Python爬虫遭遇反爬虫机制及应对策略
引言 随着网络爬虫技术的广泛应用,越来越多的网站开始实施反爬虫机制,以维护网站的正常运行和数据安全。对于爬虫开发者而言,如何有效应对这些反爬虫机制,确保爬虫的稳定运行,成为了一个亟待解决的问题。本文将介绍常见的反爬虫机制以及相应的应对策略,帮助你在Python爬虫开发中轻松应对挑战。 一、常见的反爬虫机制 Use...
Python爬虫中的数据存储和反爬虫策略
在Python爬虫开发中,我们经常面临两个关键问题:如何有效地存储爬虫获取到的数据,以及如何应对网站的反爬虫策略。本文将通过问答方式,为您详细阐述这两个问题,并提供相应的解决方案。问题一:如何有效地存储爬取到的数据?数据存储是爬虫开发中数据库的一环。我们可以选择将数据存储到数据库中,或...
Python 反爬虫与反反爬虫
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。个人主页:小嗷犬的博客个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。本文内容:Python 反爬虫与反反爬虫1.什么是爬虫网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引....

【Python3爬虫】常见反爬虫措施及解决办法(三)
【Python3爬虫】常见反爬虫措施及解决办法(三) 上一篇博客的末尾说到全网代理IP的端口号是经过加密混淆的,而这一篇博客就将告诉你如何破解!如果觉得有用的话,不妨点个推荐哦~ 一、全网代理IP的JS混淆 首先进入全网代理IP,打开开发者工具,点击查看端口号,看起来貌似没有什么问题: 如果你已经爬取过这个网站的代理,你就会知道事情并非这么简单。如果没爬过呢?也很简单,点击鼠标右键然...
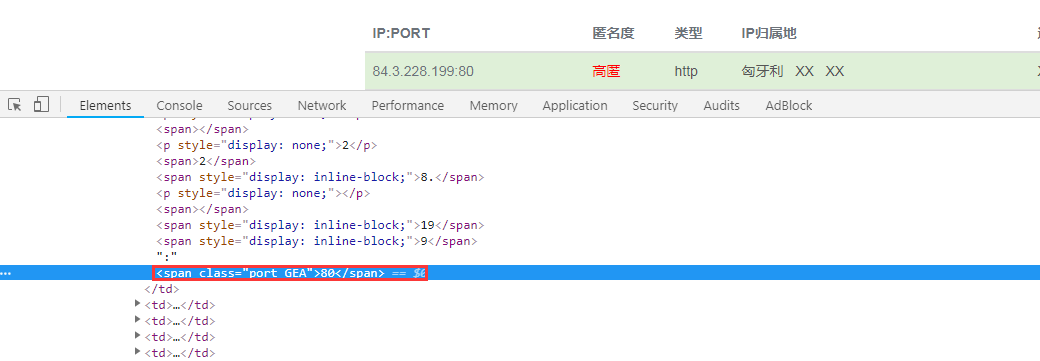
【Python3爬虫】常见反爬虫措施及解决办法(二)
【Python3爬虫】常见反爬虫措施及解决办法(二) 这一篇博客,还是接着说那些常见的反爬虫措施以及我们的解决办法。同样的,如果对你有帮助的话,麻烦点一下推荐啦。 一、防盗链 这次我遇到的防盗链,除了前面说的Referer防盗链,还有Cookie防盗链和时间戳防盗链。Cookie防盗链常见于论坛、社区。当访客请求一个资源的时候,他会检查这个访客的Cookie,如果不是他自己的用户的C...
python selenium chrome 只要打开 就被反爬虫?报错
有个网站 只要我用 chrome 驱动开打网址 就被检测到, 拖动滑块验证 一直 是失败。 换回 手动打开 浏览器 就能 正常拖动滑块验证。 IP 每次我都是更换的。 浏览器和 驱动 都从新下载的别的版本 还是不行。 求大神 指点已下 谢谢了。以前没遇到过这个情况。近期才出现这个问题。 我是WINDOWS 版本 PYTHON3.6 。还有个问题 &n...
Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用户识别为爬虫,这种情况多出现在封ip中,例如学校网络、小区网络再或者网络网络都是共享一个公共ip,这个时候如果是封ip就会导致很多正常访问的用户也无法获取到数据。所以相对来说封ip的策略不是特别好,....
python网络爬虫 - 如何伪装逃过反爬虫程序
有的时候,我们本来写得好好的爬虫代码,之前还运行得Ok, 一下子突然报错了。 报错信息如下: Http 800 Internal internet error 这是因为你的对象网站设置了反爬虫程序,如果用现有的爬虫代码,会被拒绝。 之前正常的爬虫代码如下: from urllib.request import urlopen ... html = urlopen(scrapeUrl)...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。