
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(二)
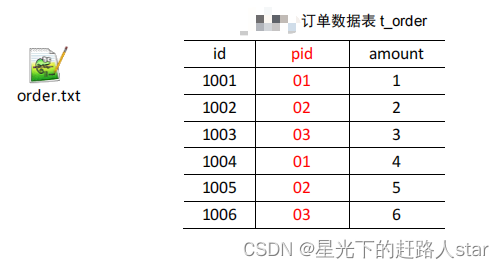
3、Join应用3.1 Reduce Join(1)Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。(2)Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并....
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(一)
1、OutputFormat数据输出1.1 OutputFormat接口实现类OutputFormat是MapReduce输出的基类,所以实现MapReduce输出都实现了OutputFormat接口。1、MapReduce默认的输出格式是TextOutputFormat2、也可以自定义OutputFormat类,只要继承就行。1.2 自定义OutputFormat案例实操1、需求过滤输入的 l....
Hadoop生态系统中的数据处理技术:MapReduce的原理与应用
Hadoop生态系统是大数据处理的核心框架之一。在Hadoop生态系统中,MapReduce是一种常用的数据处理技术。本文将介绍MapReduce的原理和应用,并提供代码示例。 一、MapReduce的原理 MapReduce是一种分布式计算模型,用于处理大规模数据集。它的原理可以简单概括为“分而治之”。具体来说,MapReduce将数据分...
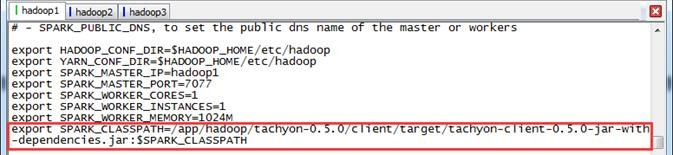
Spark Tachyon实战应用(配置启动环境、运行spark和运行mapreduce)
Tachyon实战应用 配置及启动环境 修改spark-env.sh 启动HDFS 启动Tachyon Tachyon上运行Spark 添加core-site.xml 启动Spark集群 读取文件并保存 Tachyon运行MapReduce 修改core-site.xml 启动YARN 运行MapReduce例子 ...
MapReduce 编程模型在日志分析方面的应用
简介 日志分析往往是商业智能的基础,而日益增长的日志信息条目使得大规模数据处理平台的出现成为必然。MapReduce 处理数据的有效性为日志分析提供了可靠的后盾。 本文将以对访问网页用户的日志进行分析,进而挖掘出用户兴趣点这一完整流程为例,详细解释 MapReduce 模型的对应实现,涵盖在 MapReduce 编程中对于特殊问题的处理技巧,比如机器学习算法、排序算法、索引机制、连接机制等。文.....
Hadoop专业解决方案-第5章 开发可靠的MapReduce应用
本章主要内容: 1、利用MRUnit创建MapReduce的单元测试。 2、MapReduce应用的本地实例。 3、理解MapReduce的调试。 4、利用MapReduce防御式程序设计。 在WOX.COM下载本章源代码 本章在wox.com网站的源码可以在www.wiley.com/go/prohadoopsolutions的源码下载标签找到。第五章的源码根据本章的内容各自分别命名放在了第五....
《云计算》学习笔记2——Google的云计算原理与应用(GFS和MapReduce)
Google 云计算平台技术架构 ¢文件存储,Google Distributed File System,GFS ¢并行数据处理MapReduce ¢分布式锁Chubby ¢分布式结构化数据表BigTable ¢分布式存储系统Megastore ¢分布式监控系统Dapper 一、Google文件系统GFS 分三大块来讲的, 系统架构、容错机制、系统管理技术 1、 系统架构 ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注