
爬虫技术详解:从原理到实践
爬虫技术详解:从原理到实践 引言 在数字化时代,数据的价值日益凸显。爬虫技术作为获取网络数据的重要手段,被广泛应用于数据采集、市场分析、信息监控等多个领域。本文将深入探讨爬虫的工作原理,并以Python语言为例,展示如何实现一个基本的网页爬虫。 爬虫基础 爬虫定义 爬虫,又称为网络爬虫或网页蜘蛛,...

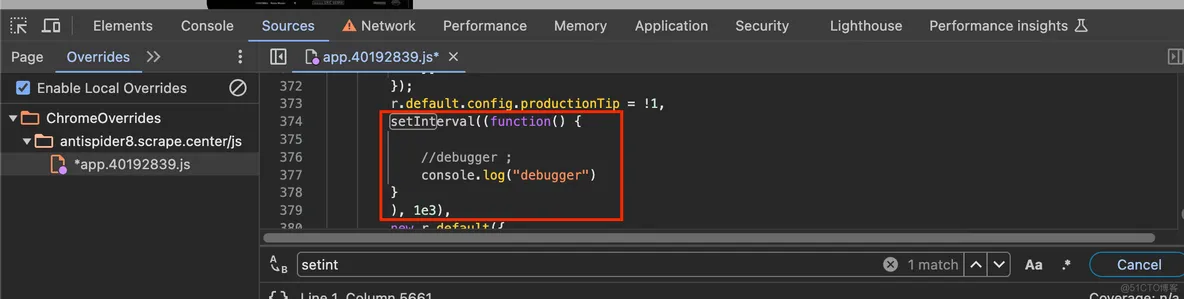
JavaScript逆向爬虫——无限debugger的原理与绕过
debugger 是 JavaScript 中定义的一个专门用于断点调试的关键字,只要遇到它,JavaScript 的执行便会在此处中断,进入调试模式。有了 debugger 这个关键字,就可以非常方便地对 JavaScript 代码进行调试,比如使用 JavaScript Hook 时,可以加入 debugge...
Python编程异步爬虫——协程的基本原理(一)
Python编程之异步爬虫协程的基本原理要实现异步机制的爬虫,自然和协程脱不了关系。 案例引入先看一个案例网站,地址为https://www.httpbin.org/delay/5,访问这个链接需要先等5秒钟才能得到结果,这是因为服务器强制等待5秒时间才返回响应。下面来测试一下,用requests写一个遍历程序,...
Python编程异步爬虫——协程的基本原理(二)
接上文 Python编程异步爬虫——协程的基本原理(一)https://developer.aliyun.com/article/1620696 多任务协程如果想执行多次请求,应该怎么办?可以定义一个task列表,然后使用asyncio包中的wait方法执行,如下所示: import asyncio...
心得经验总结:爬虫(爬虫原理与数据抓取)
通用爬虫和聚焦爬虫根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.通用爬虫通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。通用搜索引擎(Search Engine)工作原理通用网络爬虫 从互...
心得经验总结:爬虫(爬虫原理与数据抓取)
通用爬虫和聚焦爬虫根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.通用爬虫通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。通用搜索引擎(Search Engine)工作原理通用网络爬虫 从互...
【专栏】网络爬虫与数据抓取的基础知识,包括爬虫的工作原理、关键技术和不同类型
在网络信息爆炸的时代,数据成为驱动商业决策、科研进展乃至社会变革的宝贵资源。网络爬虫与数据抓取技术,作为获取网络数据的关键手段,如同一把开启数据宝库的钥匙,为我们揭示了互联网数据背后的秘密。本文将带你深入探索网络爬虫与数据抓取的奇妙世界,从基础原理到实践应用,再到伦理与法律的考量,全面解密这一技术的...
简单描述一下爬虫的工作原理。
爬虫的工作原理可以简单概括为以下几个步骤: 发送请求:爬虫程序会向目标网站发送 HTTP 请求,请求获取网页的内容。获取响应:目标网站接收到请求后,会返回相应的 HTTP 响应,其中包含了网页的源代码或其他数据。解析数据:爬虫程序会使用相应的库或工具,对返回的响应数据进行解析ÿ...
Python爬虫-代理池原理和搭建
代理池的维护 我们在上一节了解了利用代理可以解决目标网站封 IP 的问题。在网上有大量公开的免费代理,或者我们也可以购买付费的代理 IP,但是代理不论是免费的还是付费的,都不能保证都是可用的,因为可能此 IP 被其他人使用来爬取同样的目标站点而被封禁,或者代理服务器突然发生故障或网络繁忙。一旦我们选用了一个不可用的代理,这势必会影响爬虫的工作效率。 所以,我们需要提前做筛选,将不...

Python爬虫之Ajax数据爬取基本原理#6
前言 有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用 requests 得到的结果并没有。这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在 HTML 文...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注