
Apache Hudi典型应用场景知多少?
1.近实时摄取 将数据从外部源如事件日志、数据库提取到Hadoop数据湖 中是一个很常见的问题。在大多数Hadoop部署中,一般使用混合提取工具并以零散的方式解决该问题,尽管这些数据对组织是非常有价值的。 对于RDBMS摄取,Hudi通过Upserts提供了更快的负载,而非昂贵且低效的批量负载。例如你可以读取MySQL binlog日志或Sqoop增量导入,并将它们应用在DFS上...
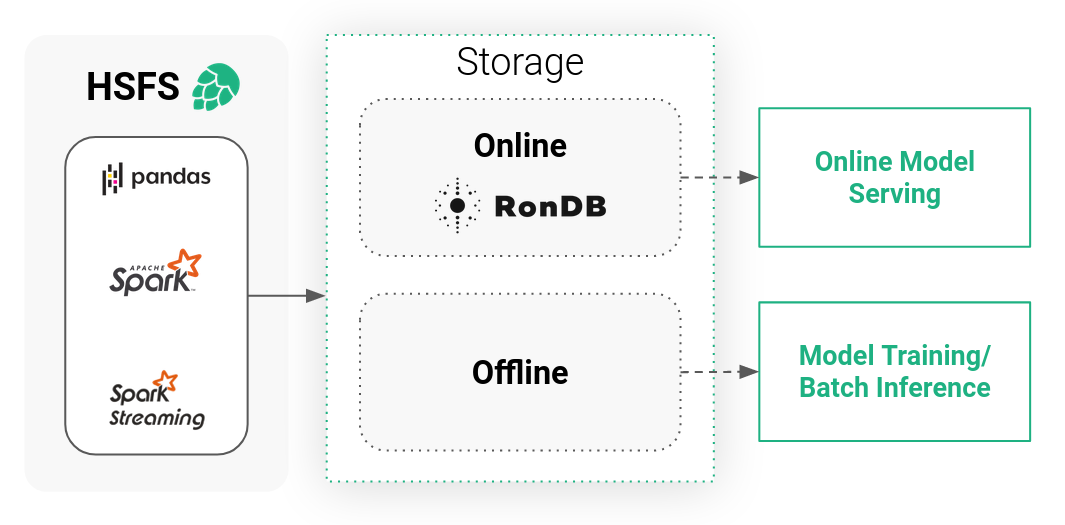
如何将Apache Hudi应用于机器学习
1. 引入 如果要将AI嵌入到企业计算系统中,企业必须重新调整其机器学习(ML)开发流程以使得数据工程师、数据科学家和ML工程师可以在管道中自动化开发,集成,测试和部署。本博客介绍了与机器学习平台进行持续集成(CI),持续交付(CD)和持续培训(CT)的平台和方法,并详细介绍了如何通过特征存储(Feature Store)执行CI / CD机器学习操作(MLOps)。以及特征存储如何将整...

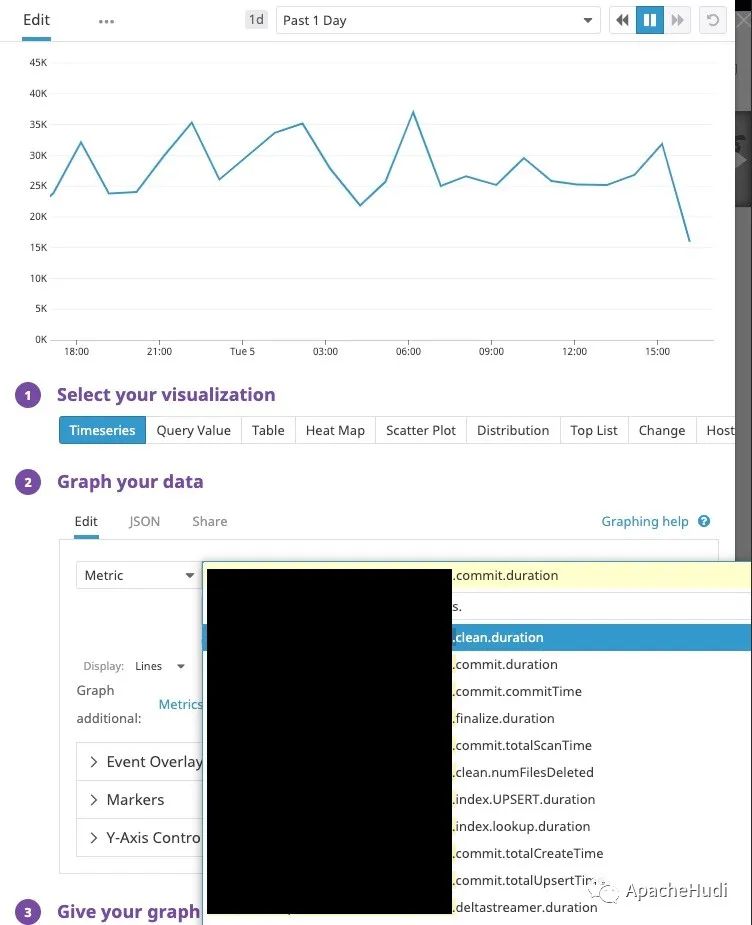
实战!配置DataDog监控Apache Hudi应用指标
1. 可用性 在Hudi最新master分支,由Hudi活跃贡献者Raymond Xu贡献了DataDog监控Hudi应用指标,该功能将在0.6.0 版本发布,也感谢Raymond的投稿。 2. 简介 Datadog是一个流行的监控服务。在即将发布的Apache Hudi 0.6.0版本中,除已有的报告者类型(Graphite和JMX)之外,我们将引入通过Datadog ...
Apache Hudi在Hopsworks机器学习的应用
Hopsworks特征存储库统一了在线和批处理应用程序的特征访问而屏蔽了双数据库系统的复杂性。我们构建了一个可靠且高性能的服务,以将特征物化到在线特征存储库,不仅仅保证低延迟访问,而且还保证在服务时间可以访问最新鲜的特征值。 ...
硬核!Apache Hudi Schema演变深度分析与应用
1.场景需求 在医疗场景下,涉及到的业务库有几十个,可能有上万张表要做实时入湖,其中还有某些库的表结构修改操作是通过业务人员在网页手工实现,自由度较高,导致整体上存在非常多的新增列,删除列,改列名的情况。由于Apache Hudi 0.9.0 版本到 0.11.0 版本之间只支持有限的schema变更,即新增列到尾部的情况,且用户对数据质量要求较高,导致了非常高的维护成本。每次删除列和改...

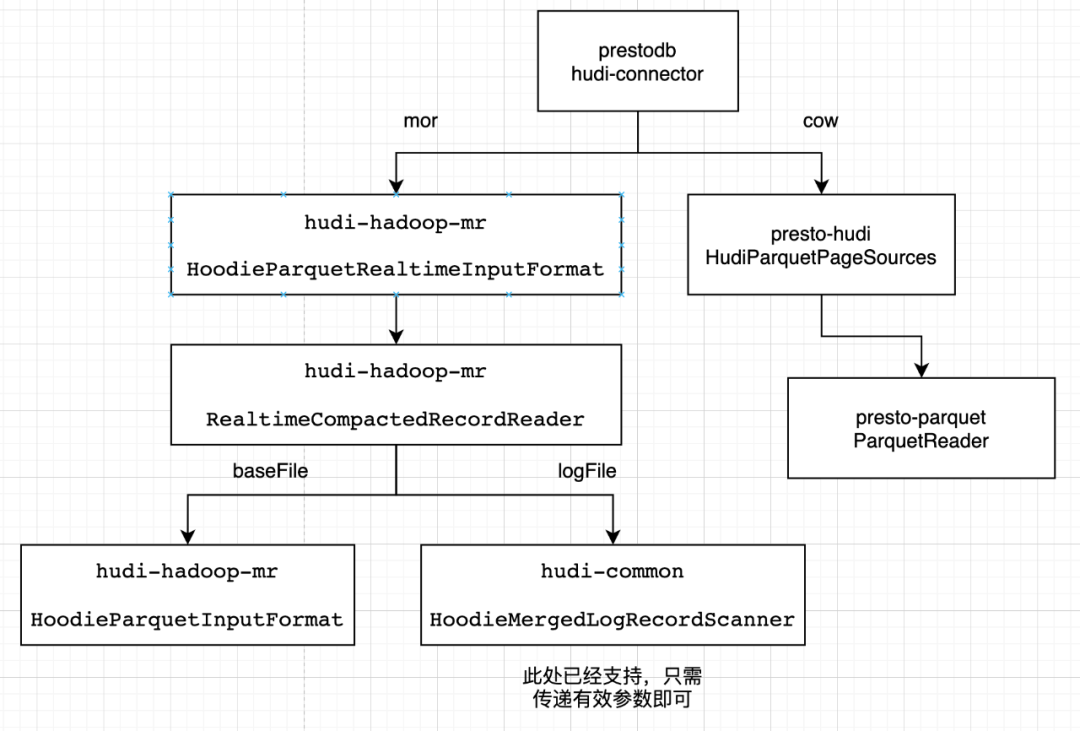
医疗在线OLAP场景下基于Apache Hudi 模式演变的改造与应用
背景 在 Apache Hudi支持完整的Schema演变的方案中 硬核!Apache Hudi Schema演变深度分析与应用 读取方面,只完成了SQL on Spark的支持(Spark3以上,用于离线分析场景),Presto(用于在线OLAP场景)及Apache Hive(Hudi的bundle包)的支持,在正式发布版本中(Hudi 0.12.1, PrestoDB 0.277)还...
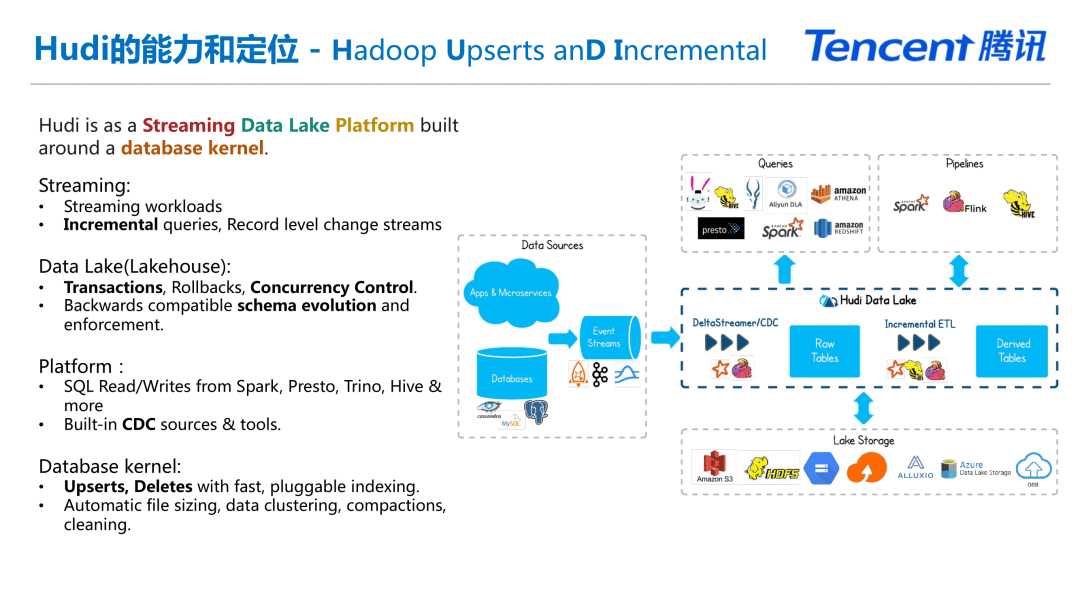
Apache Hudi在腾讯的落地与应用
Apache Hudi核心概念 Apache Hudi是一个基于数据库内核的流式数据湖平台,支持流式工作负载,事务,并发控制,Schema演进与约束;同时支持Spark/Presto/Trino/HIve等生态对接,在数据库...
一文聊透Apache Hudi的索引设计与应用
Apache Hudi索引在数据读和写的过程中都有应用。读的过程主要是查询引擎利用MetaDataTable使用索引进行Data Skipping以提高查找速度;写的过程主要应用在upsert写上,即利用索引查找该纪录是新增(I)还是更新(U),以提高写入过程中纪录的打标(tag)速度。 MetaDataTable 目前使能了"hoodie.metadata.enable"后,会...
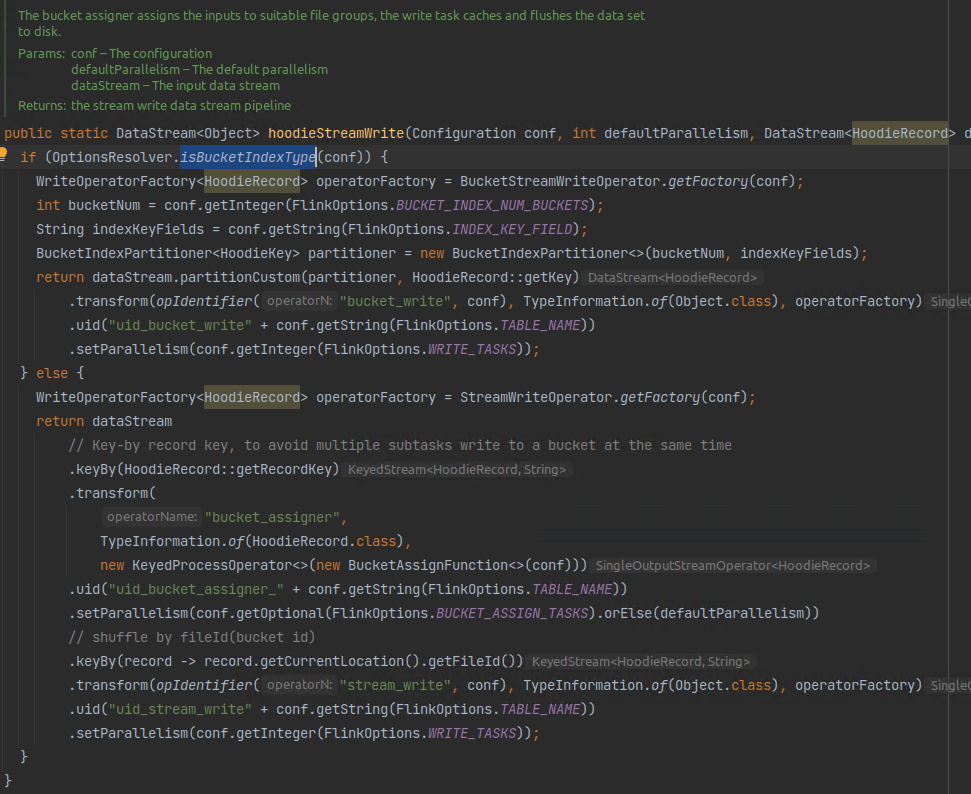
万字长文 | 泰康人寿基于 Apache Hudi 构建湖仓一体平台的应用实践
文章贡献者 Authors • 技术指导: 泰康人寿 数据架构资深专家工程师 王可 • 文章作者: 泰康人寿 数据研发工程师 田昕峣 摘要 Abstract 本文详细介绍了泰康人寿基于 Apache Hudi 构建湖仓一体分布式数据处理平台的技术选型方法、整体架构设计与实施、以及针对大健康领域的领域特征和公司战略对 Apache Hudi 进行的功能扩展与实施的详...
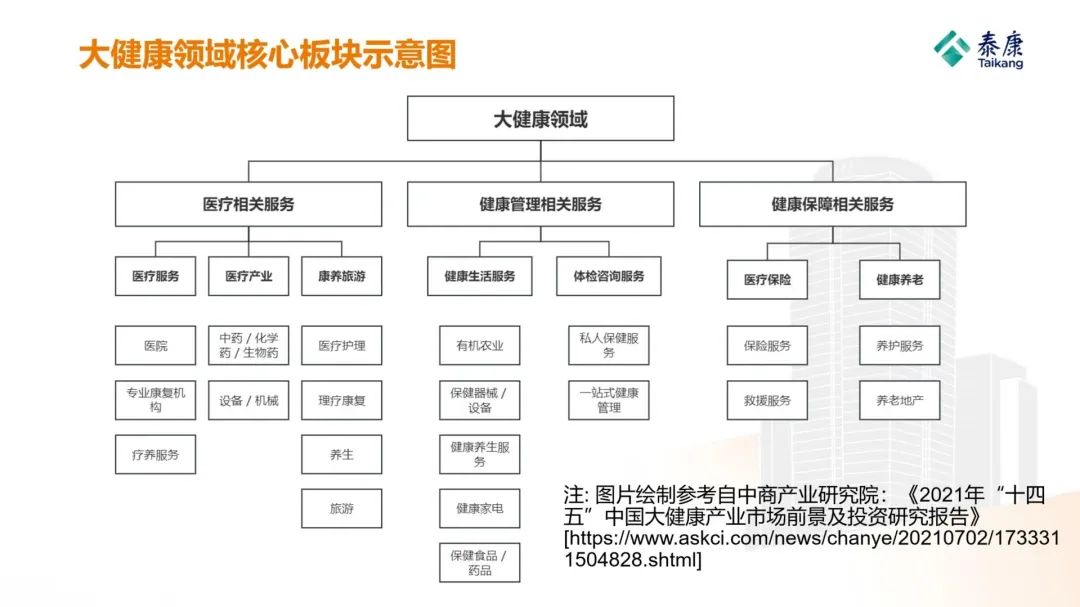
基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化。虽然能够在海量批处理场景中取得不错的效果,但依然存在如下现状问题:问题一:不支持事务由于传统大数据方案不支持事务,有可能会读到未写完成的数据,造成数据统计错误。为了规避该问题,通常控制读写任务顺序调用,在保....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache应用相关内容
- 应用Apache
- Apache构建应用
- Apache流处理应用
- Apache数据分析应用
- Apache技术应用
- 实战Apache应用
- Apache paimon应用
- Apache大数据处理应用
- Apache大数据应用
- Apache机器学习应用
- Apache hudi机器学习应用
- Apache分析应用
- 场景Apache应用
- Apache平台应用
- Apache flink应用
- 系统技术Apache应用
- 技术Apache应用
- Apache storm应用
- apacheflink案例集(2022版)Apache应用
- apacheflink案例集(2022版)数字化转型Apache场景应用
- Apache maven高级应用part
- Apache部署应用
- Apache shiro应用
- Apache架构应用
- Apache应用部署
- Apache工具应用
- Apache性能测试工具ab应用
- Apache密码工具htpasswd应用
Apache您可能感兴趣
- Apache iceberg
- Apache数据湖
- Apache性能
- Apache调优
- Apache孵化器
- Apache meetup
- Apache阿里云
- Apache doris
- Apache日志
- Apache技术
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache实践

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注