
爬虫策略规避:Python爬虫的浏览器自动化
网络爬虫作为一种自动化获取网页数据的技术,被广泛应用于数据挖掘、市场分析、竞争情报等领域。然而,随着反爬虫技术的不断进步,简单的爬虫程序往往难以突破网站的反爬虫策略。因此,采用更高级的爬虫策略,如浏览器自动化,成为了爬虫开发者的必然选择。浏览器自动化概述浏览器自动化是指通过编程方式控制浏览器执行一系列操作的技术。...
使用Python爬虫获取Firefox浏览器的用户评价和反馈
在当今数字化的世界中,浏览器是我们日常生活中必备的工具之一。Firefox浏览器作为首批备受欢迎的开源浏览器,拥有庞大的用户群体。了解Firefox的用户浏览器的评价和反馈,对于改进和优化浏览器功能具有重要意义。所以今天我们重点分享下如何利用Python爬虫来获取Firefox浏览器的用户评价和反馈。作为一个技术爱好者,我相信你一定对这个话...
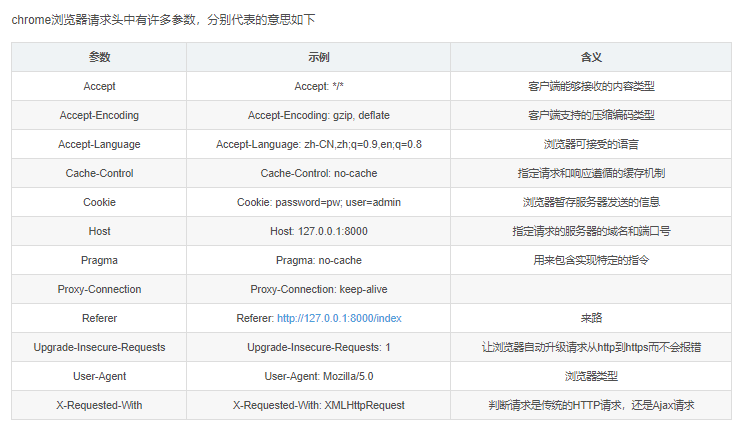
Python爬虫:fake_useragent库模拟浏览器请求头
简单示例# -*- coding: utf-8 -*- # @File : fake_useragent_demo.py # @Date : 2018-05-28 from fake_useragent import UserAgent ua = UserAgent() print(ua.ie) print(ua.opera) print(ua.chrome) print(ua.go...
Python爬虫:常用的浏览器请求头User-Agent
user_agent = [ "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) Ap...
通过爬虫中的selenium控制chrome,Firefox等浏览器自动操作获取相关信息
1.首先将我们需要的selenium的包导入fromselenium.webdriverimportChrome(如果使用chrome浏览器就导入chrome,如果使用别的浏览器则将名称换掉即可) 2.创建浏览器对象web=Chrome() 3.打开浏览器web.get("http://www.baidu.com")(此处以百度举例) 4.找到某个元素. 点击它el=web.find_elem.....

Python3网络爬虫——(2)设置User Agent模拟浏览器访问
设置User Agent模拟浏览器访问 方法一、使用build_opener()修改报头 # -*- coding: UTF-8 -*- #使用build_opener()修改报头 from urllib import request if __name__ == "__main__": url="https://blog.csdn.net/asialee_bird/article/d...

Python爬虫:fake_useragent库模拟浏览器请求头
参考网站pypi网站:https://pypi.org/project/fake-useragent/User Agent String.Com :http://www.useragentstring.com/简单示例# -*- coding: utf-8 -*- # @File : fake_useragent_demo.py # @Date : 2018-05-28 from f...
Python爬虫:browsercookie库获取浏览器cookie
第三方库:browsercookie可以很轻易的获取浏览器cookie,访问需要需要登录才能查看的页面pipy主页: https://pypi.org/project/browsercookie/代码示例# 获取浏览器cookie import browsercookie import requests from bs4 import BeautifulSoup # 消除 warning I...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注