
通过Spark SQL读DLF管理的数据
数据湖构建 DLF(Data Lake Formation)提供了统一的元数据管理、统一的权限与安全管理、便捷的数据入湖能力以及一键式数据探索能力,您可以在云原生数据仓库 AnalyticDB MySQL 版中通过Spark SQL访问DLF中的元数据。
Spark SQL交互式查询
如果您需要以交互式方式执行Spark SQL,可以指定Spark Interactive型资源组作为执行查询的资源组。资源组的资源量会在指定范围自动扩缩容,在满足您交互式查询需求的同时还可以降低使用成本。本文为您详细介绍如何通过控制台、Hive JDBC、PyHive、Beeline、DBeaver等客户端工具实现Spark SQL交互式查询。
ADB Spark SQL的使用
DataWorks的ADB Spark SQL节点可进行AnalyticDB Spark SQL任务的开发和周期性调度,以及与其他作业的集成操作。本文为您介绍使用ADB Spark SQL节点进行任务开发的主要流程。
通过Spark SQL读写Azure Blob Storage外表
本文主要介绍如何在云原生数据仓库 AnalyticDB MySQL 版中使用Spark SQL读写Azure Blob Storage中的数据。
Spark SQL诊断优化
云原生数据仓库 AnalyticDB MySQL 版推出Spark SQL诊断功能,若您提交的Spark SQL存在性能问题,您可以根据诊断信息快速定位、分析并解决性能瓶颈问题,优化Spark SQL。本文主要介绍如何进行Spark SQL性能诊断以及性能诊断的示例。
进入大数据 Spark SQL 的世界
1、什么是大数据? 大数据特征:4V 数据量(Volume) PB、EB、ZB 给予高度分析的新价值(Value) 巨额数据里面提取需要的高....
大数据进阶之路——Spark SQL小结
手写 WordCount使用flatMap、reduceByKey 来计算//sc是SparkContext对象,该对象是提交spark程序的入口 sc.textFile("file:///home/hadoop/data/hello.txt") // 读取文件, .flatMap(line => line.split(" ")) // 将文件中的每一行单词按照分隔符(这里是空格)分...
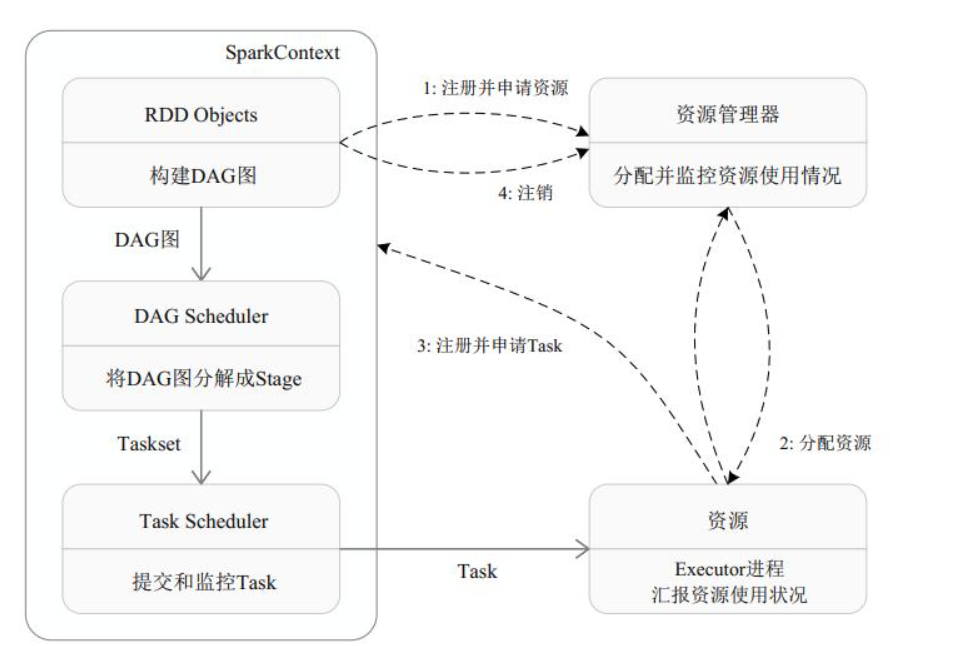
大数据进阶之路——Spark SQL基本配置
文章目录Spark安装编译失败环境搭建Standalone本地IDEHiveContextAPPSparkSessinonSpark ShellSpark Sqlthriftserver/beeline的使用jdbcMapReduce的局限性:1)代码繁琐;2)只能够支持map和reduce方法;3)执行效率低下;4)不适合迭代多次、交互式、流式的处理;框架多样化:1)批处理(离线):MapRe....
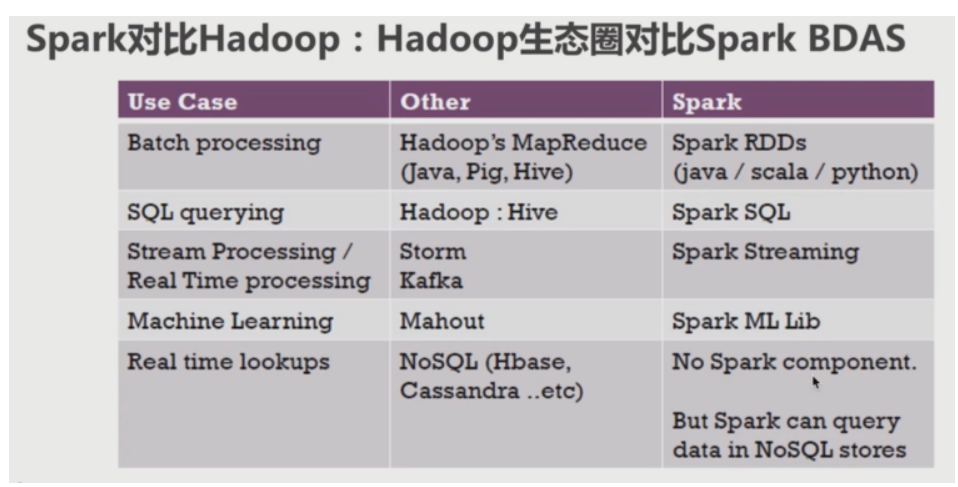
大数据为什么那么火?一文带你了解Spark与SQL结合的力量
Spark是一种大规模、快速计算的集群平台,本头条号试图通过学习Spark官网的实战演练笔记提升笔者实操能力以及展现Spark的精彩之处。有关框架介绍和环境配置可以参考以下内容: linux下Hadoop安装与环境配置(附详细步骤和安装包下载) linux下Spark安装与环境配置(附详细步骤和安装包下载) 本文的参考配置为:Deepin 15.11、Java 1.8.0_241、Ha....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
SQL spark相关内容
- spark原理SQL
- 大数据spark SQL hive
- spark集群SQL
- spark sparksql SQL
- spark SQL json
- spark SQL jdbc
- spark SQL rdd
- 仓库spark SQL访问
- spark SQL简介
- spark SQL开发
- spark SQL打包
- spark SQL oss
- dms spark SQL任务
- spark SQL任务
- e-mapreduce spark SQL
- spark SQL权限控制
- mapreduce spark SQL
- spark SQL节点
- dms spark SQL
- spark SQL访问
- spark SQL mapreduce
- spark SQL组件
- 跨库spark SQL库
- spark编程SQL
- 大数据SQL spark
- SQL引擎spark
- hive SQL引擎spark
- 数据计算SQL spark
- spark SQL原理
- odps spark SQL
SQL更多spark相关
- spark SQL分区
- spark SQL聚合
- spark SQL数据分析
- spark SQL案例
- spark SQL dataset
- spark SQL引擎
- spark SQL数据源
- 大数据技术spark SQL
- 技术spark SQL
- 大数据spark SQL dataframe dataset
- spark SQL编程
- spark SQL学习
- spark SQL解析
- spark SQL schema
- spark SQL格式
- spark SQL概念学习
- hadoop spark SQL
- hudi spark SQL源码学习
- 跨库spark SQL
- spark SQL功能
- spark SQL实战
- spark入门SQL
- spark程序SQL
- 大数据进阶spark SQL
- spark SQL parquet
- spark源码SQL
- hudi spark SQL源码学习ctas
- spark SQL构建
- spark SQL表格存储
- spark SQL源码

数据库
分享数据库前沿,解构实战干货,推动数据库技术变革
+关注