
如何实现通用爬虫并检测可用性?
一、实现运行爬虫模块我们的目标:根据配置文件信息, 加载爬虫,抓取HTTP代理,进行校验,如果可用,写入到数据库中根据以下思路:1.在run_spider.py中,创建RunSpider类2.提供一个运行爬虫的run方法,作为运行爬虫的入口,实现核心的处理逻辑● 根据配置信息,获取爬虫对象列表● 遍历爬虫对象列表,获取爬虫对象,遍历爬虫对象的get_proxies方法,获取HTTP代理● 检测H....
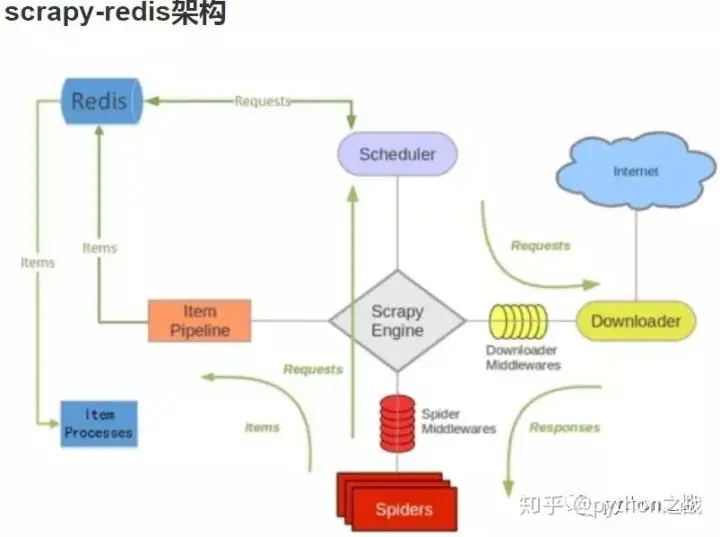
scrapy框架通用爬虫、深度爬虫、分布式爬虫、分布式深度爬虫,源码解析及应用
scrapy框架是爬虫界最为强大的框架,没有之一,它的强大在于它的高可扩展性和低耦合,使使用者能够轻松的实现更改和补充。 其中内置三种爬虫主程序模板,scrapy.Spider、RedisSpider、CrawlSpider、RedisCrawlSpider(深度分布式爬虫)分别为别为一般爬虫、分布式爬虫、深度爬虫提供内部逻辑;下面将从源码和应用来学习, scrapy.Spider 源码: ""....
Scrapy框架--通用爬虫Broad Crawls(下,具体代码实现)
通过前面两章的熟悉,这里开始实现具体的爬虫代码 广西人才网 以广西人才网为例,演示基础爬虫代码实现,逻辑: 配置Rule规则:设置allow的正则-->设置回调函数 通过回调函数获取想要的信息 具体的代码实现: import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders impor...
Scrapy笔框架--通用爬虫Broad Crawls(中)
rules = ( Rule(LinkExtractor(allow=r'WebPage/Company.*'),follow=True,callback='parse_company'), Rule(LinkExtractor(allow=r'WebPage/JobDetail.*'), callback='parse_item', follow=True), ...
Scrapy框架--通用爬虫Broad Crawls(上)
通用爬虫(Broad Crawls)介绍 [传送:中文文档介绍],里面除了介绍还有很多配置选项。 通用爬虫一般有以下通用特性: 其爬取大量(一般来说是无限)的网站而不是特定的一些网站。 其不会将整个网站都爬取完毕,因为这十分不实际(或者说是不可能)完成的。相反,其会限制爬取的时间及数量。 其在逻辑上十分简单(相较于具有很多提取规则的复杂的spider),数据会在另外的阶段进行后处理(pos...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注