
如何让Python爬虫在遇到异常时继续运行
概述 在数据收集和数据挖掘中,爬虫技术是一项关键技能。然而,爬虫在运行过程中不可避免地会遇到各种异常情况,如网络超时、目标网站变化、数据格式不一致等。如果不加以处理,这些异常可能会导致爬虫程序中断,影响数据采集效率和完整性。本文将概述如何使用Python编写一个健壮的爬虫,确保其在遇到异常时能够继续运行。我们将通过使用try/except语句处理异常,结合代理IP技术和多线程技术,以提高爬虫的.....

Lua vs. Python:哪个更适合构建稳定可靠的长期运行爬虫?
网络爬虫在当今信息时代扮演着至关重要的角色,它们能够自动化地抓取互联网上的信息,并且为各种应用提供数据支持。Lua和Python是两种常见的编程语言,它们都被广泛应用于爬虫的开发中。然而,在选择构建长期运行爬虫时,开发者往往会面临一个重要的问题:Lua还是Python更适合?本文将对Lua和Pyth...
运行爬虫时报错AttributeError—— 'str' object has no attribute 'capabilities'
使用webdriver报错AttributeError: 'str' object has no attribute 'capabilities' 出现上述问题时,请注意你的selenium版本,目前selenium高版本(我的是4.15.0版本)可不设置chromedriver的路径,会自己找到。 driver =...
Python爬虫:scrapy从项目创建到部署可视化定时任务运行
目录前言第一节 基本功能1、使用 pyenv创建虚拟环境2、创建 scrapy项目3、创建爬虫第二节 部署爬虫4、启动 scrapyd5、使用 scrapyd-client 部署爬虫项目6、使用 spider-admin-pro管理爬虫第三节 部署优化7、使用 Gunicorn管理应用8、使用 supervisor管理进程9、使用 Nginx转发请求前言前面1-3小节就是基本功能实现,完成了sc....

Python爬虫:Scrapy调试运行单个爬虫
一般运行Scrapy项目的爬虫是在命令行输入指令运行的:$ scrapy crawl spider每次都输入还是比较麻烦的,偶尔还会敲错,毕竟能少动就少动Scrapy提供了一个命令行工具,可以在单个spider文件中加入以下代码:from scrapy import Spider, cmdline class SpiderName(Spider): name = "spider_name...
Python爬虫:PyExecJS在python中运行javascript代码
安装$ pip install PyExecJS示例import execjs execjs.eval("new Date()") # u'2018-09-08T09:11:35.248Z' js = """ function add(x, y){ return x + y; } """ ctx = execjs.compile(js) ctx.call("add", 3, 4) # 等...
Python爬虫:scrapy定时运行的脚本
原理:1个进程 -> 多个子进程 -> scrapy进程代码示例将以下代码文件放入scrapy项目中任意位置即可# -*- coding: utf-8 -*- # @File : run_spider.py # @Date : 2018-08-06 # @Author : Peng Shiyu from multiprocessing import Process fr...
Python爬虫:scrapy直接运行爬虫
一般教程中教大在命令行运行爬虫:# 方式一 $ scrapy crawl spider_name这样,每次都要切换到命令行,虽然可以按向上键得到上次运行的指令,不过至少还要敲一次运行命令还有一种方式是单独配置一个文件,spider_name是具体爬虫名称,通过pycharm运行设置,不过每次都要改爬虫名称,而且不利于git提交# 方式二 from scrapy import cmdline ar....
python爬虫:scrapy命令失效,直接运行爬虫
scrapy命令失效,直接运行爬虫,无论是什么命令,都直接运行单个爬虫出现这个错误,很意外原因是这样的:一开始,我写了个脚本单独配置爬虫启动项:# begin.py from scrapy import cmdline cmdline.execute("scrapy crawl myspider")这样一来会比较方便,不用每次都去命令行敲命令然而当我想运行其他爬虫的时候,直接就运行 myspid....
关于Scrapy爬虫项目运行和调试的小技巧(下篇)
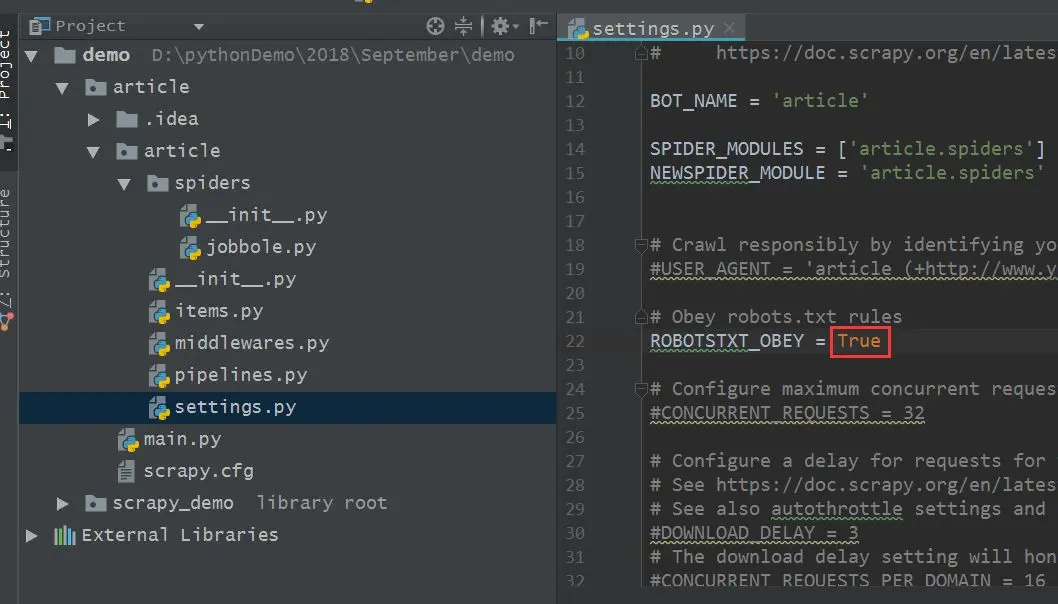
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下。今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧。 三、设置网站robots.txt规则为False 一般的,我们在运用Scrapy框架抓取数据之前,需要提前到settings.py文件中,将“ROBOTSTXT_OBEY = True”改为ROBOTSTXT....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注