
Python + Chrome 爬虫:如何抓取 AJAX 动态加载数据?
在现代 Web 开发中,AJAX(Asynchronous JavaScript and XML) 技术被广泛应用于动态加载数据,使得网页能够在不刷新的情况下更新内容。然而,这也给传统爬虫带来了挑战——使用 requests + BeautifulSoup 只能获取初始 HTML,而无法捕获 AJAX 返回的动态数据。 解决方案: Selenium + ChromeD...
爬虫进阶:Selenium与Ajax的无缝集成
爬虫与Ajax的挑战Ajax(Asynchronous JavaScript and XML)允许网页在不重新加载整个页面的情况下与服务器交换数据并更新部分内容。这为用户带来了更好的体验,但同时也使得爬虫在抓取数据时面临以下挑战: 动态内容加载:Ajax请求异步加载数据,爬虫需要等待数据加载完成才能抓取。Java...
Python爬虫之Ajax分析方法与结果提取#6
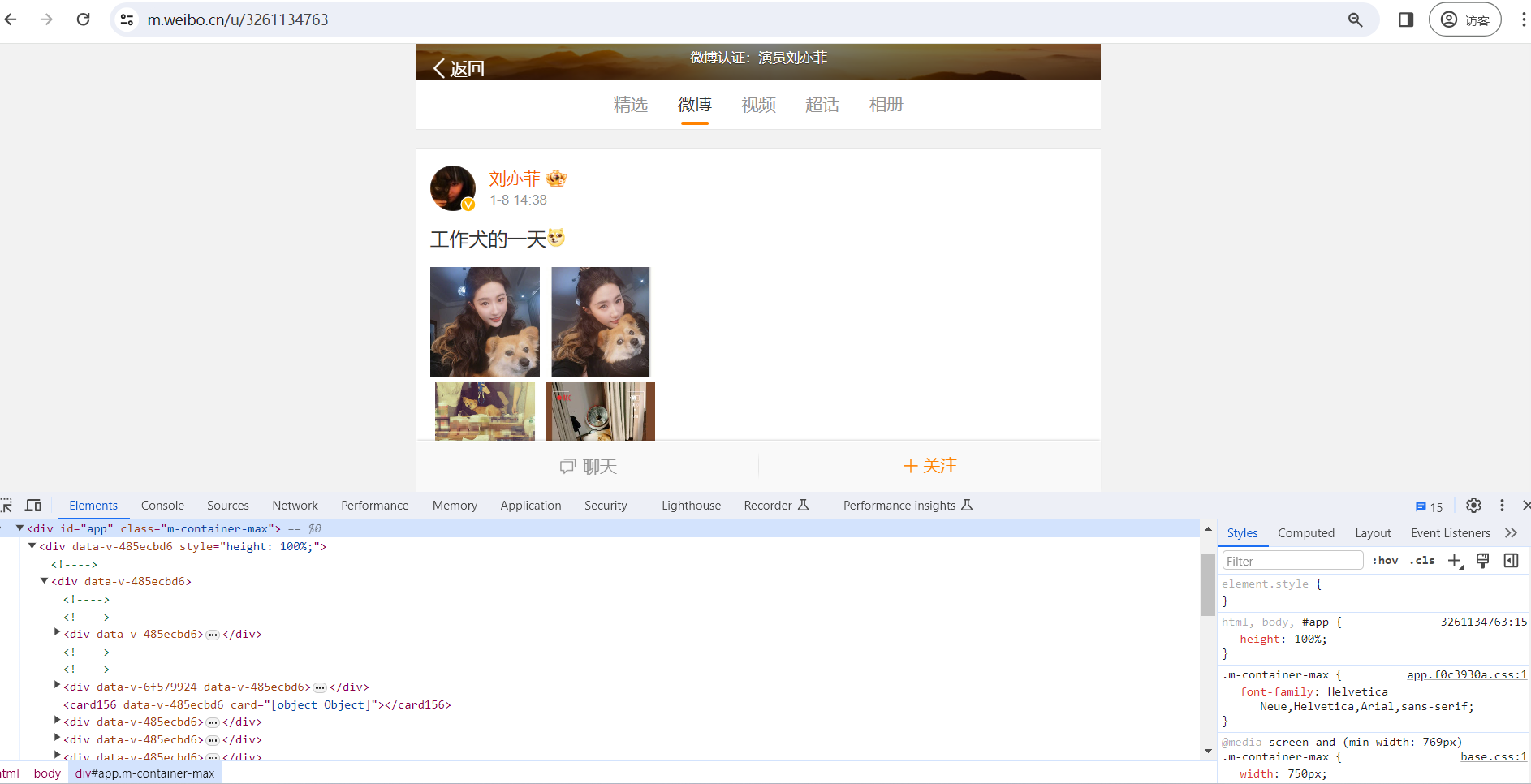
Ajax 分析方法 这里还以前面的微博为例,我们知道拖动刷新的内容由 Ajax 加载,而且页面的 URL 没有变化,那么应该到哪里去查看这些 Ajax 请求呢? 1. 查看请求 这里还需要借助浏览器的开发者工具,下面以 Chrome 浏览器为例来介绍。 首先,用 Chrome 浏览器打开微博的链接 https://m.weibo.cn/u/32611347...
Python爬虫之Ajax数据爬取基本原理#6
前言 有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用 requests 得到的结果并没有。这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在 HTML 文...
Python爬虫实战:抽象包含Ajax动态内容的网页数据
在爬虫获取网页数据时,我们经常会遇到一些网页使用Ajax技术加载动态内容的情况。这些动态内容可能包含了我们所需要的数据,但是传统的爬虫工具无法直接获取这些内容。因为传统的爬虫工具在获取网页数据时,只能获取到初始加载的静态内容,无法获取到通过Ajax技术加载动态内容。所以传统的爬虫工具只能模拟浏览器的基本行为,无法执行JavaS...
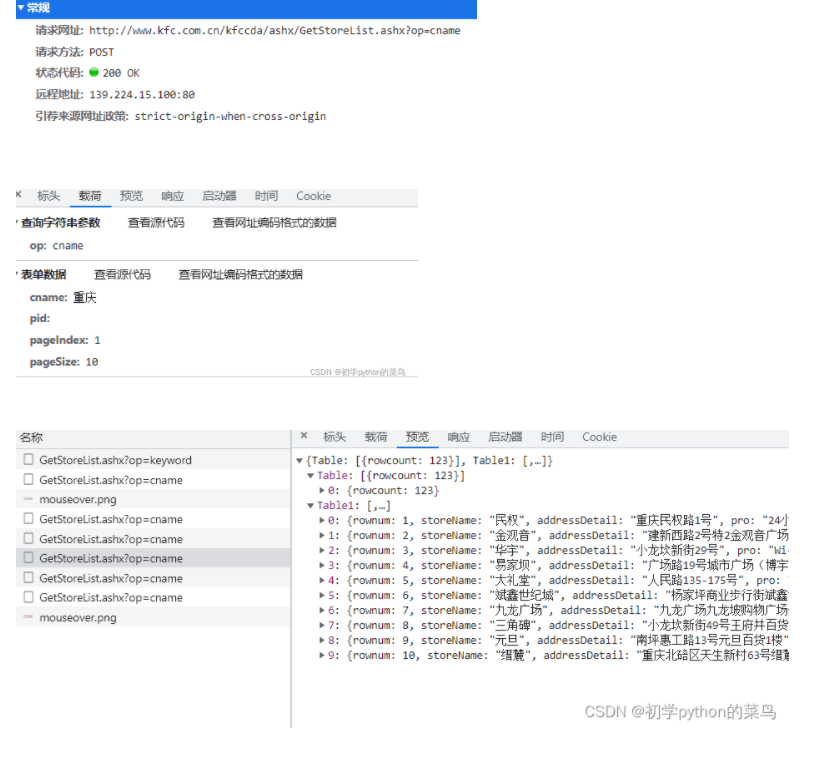
【安全合规】python爬虫从0到1 - ajax的post请求(肯德基餐厅位置查询)
先看浏览器中的网络请求:附上源码:# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname import urllib.request import urllib.parse def down_load(page): url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreLis...
【安全合规】python爬虫从0到1 -ajax的get请求进阶
前面说到获得了第一页的数据。而我们要获得后面的数据时,它们的url地址并不一样。详见下图:> 第一页网址https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%A7%91%E5%B9%BB&sort=time&> page_limit=20&page_start=0> > ....
【安全合规】python爬虫从0到1 -ajax的get请求
ajax的get请求下面让我们进阶get请求的另外的中方法!!!(一)Ajax简介Ajax,全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML。它不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了Aja....
Python 爬虫 AJAX 数据爬取和 HTTPS 访问| 学习笔记
开发者学堂课程【Python爬虫实战:Python 爬虫 AJAX 数据爬取和 HTTPS 访问】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/555/detail/7643Python 爬虫 AJAX 数据爬取和....
基于Apache Nutch和Htmlunit的扩展实现AJAX页面爬虫抓取解析插件 请求报错
基于Apache Nutch和Htmlunit的扩展实现AJAX页面爬虫抓取解析插件 ---------------------------------------------------------------------------------------------------------- 提示:当前版本项目停止更新,最新Apache Nutch 2.X版本实现请访问: http://g....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注