
开启并使用Fluid JindoRuntime FUSE客户端监控
Fluid支持对ACK集群中的各个JindoRuntime(JindoCache分布式缓存引擎)的监控指标进行采集,并提供开箱即用的JindoRuntime监控大盘。可被采集的监控指标包括缓存引擎服务端指标和FUSE客户端指标。出于性能考虑,默认配置下JindoRuntime FUSE客户端指标不对外暴露,因此无法在JindoRuntime监控大盘中查看到FUSE客户端的实时指标数据。本文介绍如何...
如何安装和升级Fluid数据加速组件
ack-fluid是云原生AI套件提供的Kubernetes环境下的分布式数据集编排和数据访问加速组件。本文介绍如何升级Fluid数据加速组件以及常见问题。
Fluid监控大盘中的各个参数的含义
本文介绍Fluid控制面监控大盘和JindoRuntime缓存系统监控大盘中变量和Panel的详细说明。大盘变量为Fluid可观测性指标提供了不同的维度(例如:监控周期长短、数据集命名空间与名称等);大盘Panel可以帮助您了解Fluid环境中组件的健康状况和性能表现。通过监控大盘,您可以及时发现并解决可能出现的问题,定位特定业务场景下缓存系统中潜在的优化项。
Fluid数据缓存优化策略最佳实践
在计算与存储分离的架构下,使用Fluid数据缓存技术,能够有效解决在Kubernetes集群中访问存储系统数据时容易出现的高延迟及带宽受限问题,从而提升数据处理效率。本文从性能维度、稳定性维度、读写一致性维度介绍如何使用Fluid数据缓存策略。
基于KServe使用Fluid实现模型加速
随着技术的发展,AI应用的模型数据越来越大,但是通过存储服务(如OSS、NAS等)拉取这些大文件时可能会出现长时间的延迟和冷启动问题。您可以利用Fluid显著提升模型加载速度,从而优化推理服务的性能,特别是对于基于KServe的推理服务而言。本文以Qwen-7B-Chat-Int8模型、GPU类型为V100卡为例,演示如何在KServe中使用Fluid实现模型加速。
Fluid 1.0版发布,打通云原生高效数据使用的“最后一公里”
【阅读原文】戳:Fluid 1.0版发布,打通云原生高效数据使用的“最后一公里” 前言 得益于云原生技术在资源成本集约、部署运维便捷、算力弹性灵活方面的优势,越来越多企业和开发者将数据密集型应用,特别是AI和大数据领域应用,运行于云原生环境中。然而,云原生计算与存储分离架构虽然带来了资源经济性与扩容灵活性方面的优势,但也引入了数据访问延迟和带宽开销...
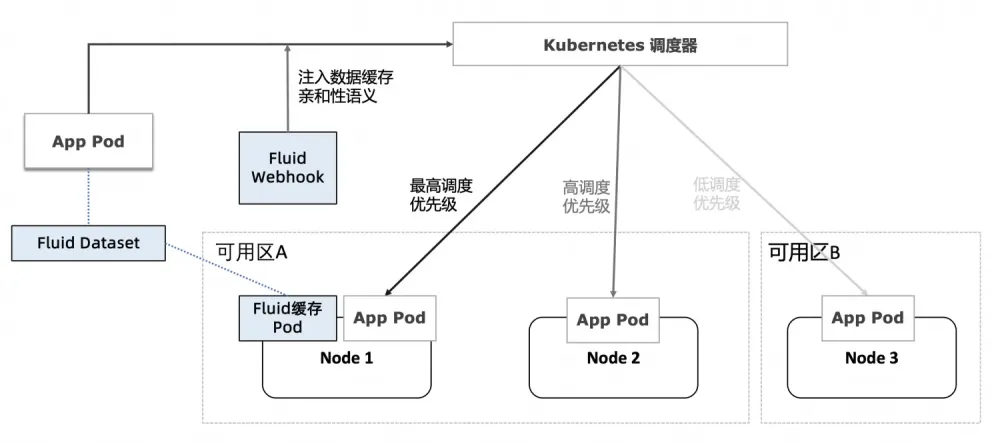
云原生的核心技术中,大数据与 AI 里的 Fluid 的目标是要达到什么目的?
云原生的核心技术中,大数据与 AI 里的 Fluid 的目标是要达到什么目的?
毫末智行 Fluid 实践:云原生 AI 让汽车变得“更聪明”
作者介绍:李范:毫末智行 服务端开发工程师,负责 AI 自动训练平台的研发与算法优化陈铁文:毫末智行 服务端开发工程师,负责 AI 自动训练平台的上层研发引言:Fluid 是云原生基金会 CNCF 下的云原生数据编排和加速项目,由南京大学、阿里云及 Alluxio 社区联合发起并开源。本文主要介绍毫末智行机器学习平台在自动驾驶场景的使用,以及如何基于 Fluid +JindoFS 突破原有存储与....
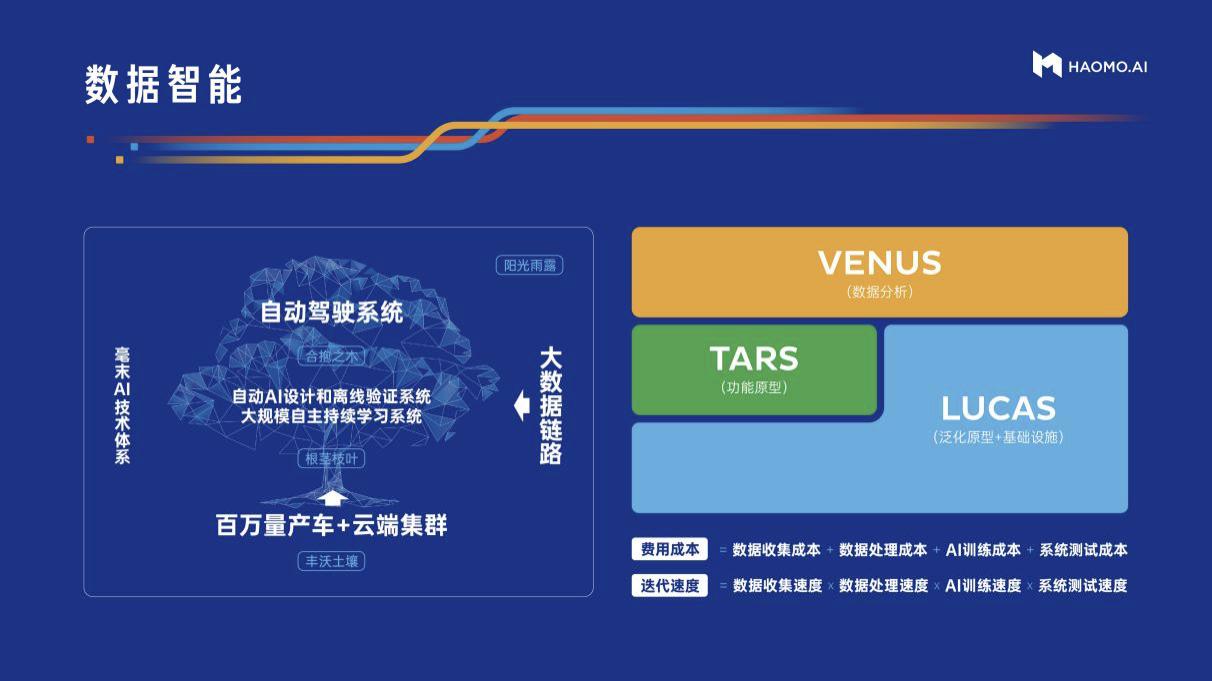
【云原生AI】Fluid + JindoFS 助力微博海量小文件模型训练速度提升 18 倍
作者 |吴彤 微博深度学习平台工程师郝丽 微博深度学习平台工程师导读:深度学习平台在微博社交业务扮演着重要的角色。计算存储分离架构下,微博深度学习平台在数据访问与调度方面存在性能低效的问题。本文将介绍微博内部设计实现的一套全新的基于 Fluid(内含 JindoRuntime)的新架构方案,显著提升了海量小文件场景模型训练的性能和稳定性,多机多卡分布式训练场景可将模型训练的速度提升 18 倍...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

阿里云云原生
关注云原生中间件、微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生技术趋势、云原生大规模的落地实践
+关注