
带你读《阿里云产品五月刊》——五、阿里云 EMR Serverless Spark 版开启免费公测
简介: EMR Serverless Spark 版免费公测已开启,预计于2024年06月25日结束。公测阶段面向所有用户开放,您可以免费试用。 阿里云 EMR Serverless Spark 版是一款云原生,专为大规模数据处理和分析而设计的全托管 Serverless 产品。它为企业提供了一站式的数据平台服务,包括任务开发、调试、调度和运维等,极大地简化了数据处...

实时计算 Flink版产品使用问题之使用Spark ThriftServer查询同步到Hudi的数据时,如何实时查看数据变化
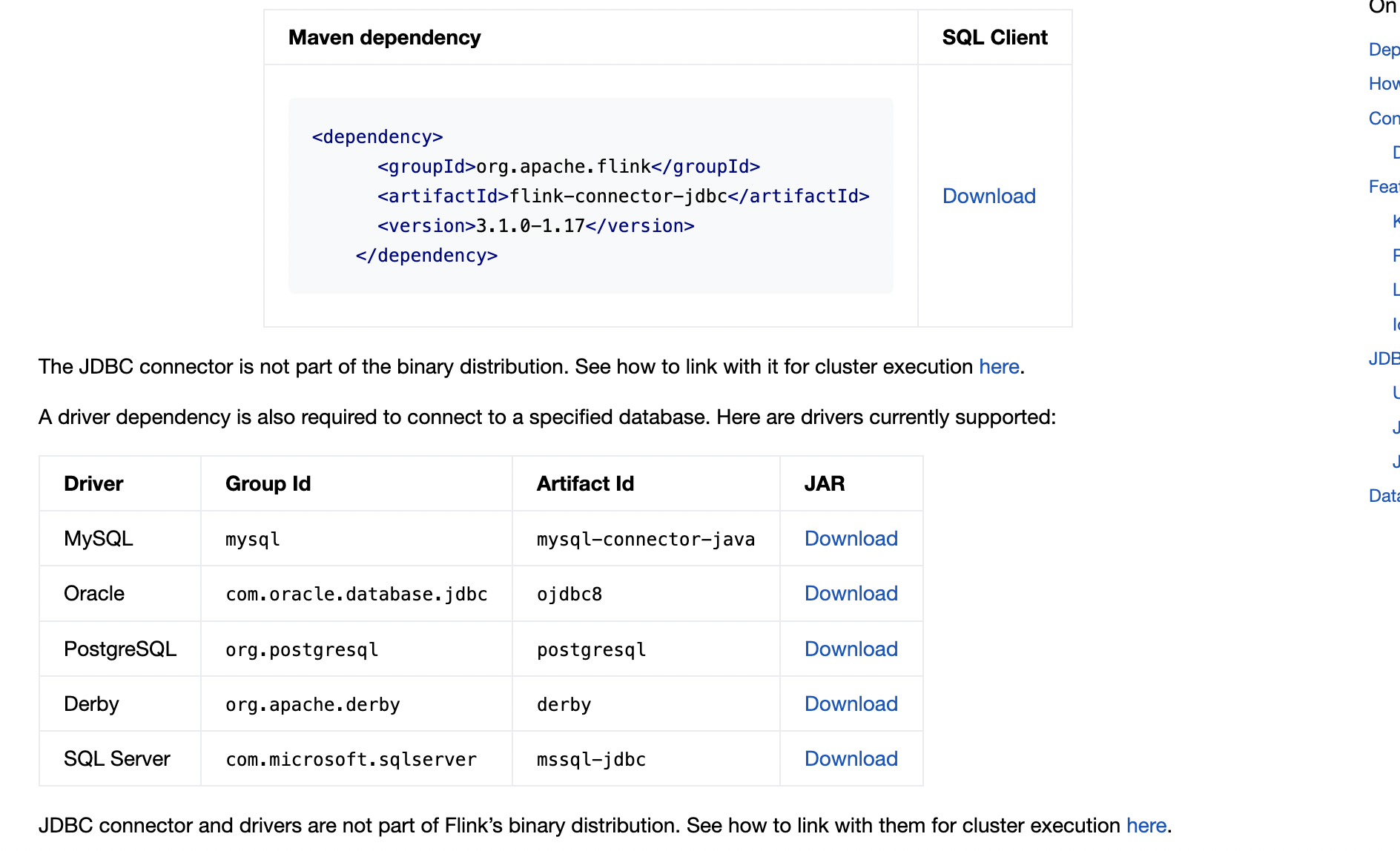
问题一:flink cdc哪个版本有sqlserverCatalog,能根据表名拿到对应的字段和字段类型? flink cdc哪个版本有sqlserverCatalog,能根据表名拿到对应的字段和字段类型? 参考答案: 你指的是flink-connector-jdbc吧,这个是连接器的特性,1.17的好像就支持了 ...
DataWorks产品使用合集之ODPS Spark找不到自己的stdout,该如何解决
问题一:dataworks支持循环嵌套吗? dataworks支持循环嵌套吗? 参考回答: 循环节点不支持嵌套循环 可以考虑用pyodps shell等节点 关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/603378 问题二:DataWorks小时调度依赖日调...

DataWorks产品使用合集之spark任务如何跨空间取表数据
问题一:DataWorks中spark任务是有办法跨空间取表数据吗? DataWorks中spark任务是有办法跨空间取表数据吗? 参考回答: odps spark吗 指定项目名.表名访问试试 https://help.aliyun.com/zh/maxcompute/user-guide/spark-2-x-examples?spm=a2c4g.1118662...
【评测有奖】参加 EMR Serverless Spark 产品评测,赢机械键盘、充电宝等礼品!
EMR Serverless Spark 是一款云原生、专为大规模数据处理与分析而设计的全托管 Serverless Spark 计算产品。为企业提供了围绕Spark 任务的一站式开发、调试、调度以及运维等产品化服务,极大的简化了数据处理全生命周期的工作流程,使企业更加专注于数据的分析与价值提炼。 现面向所有用户发出诚挚邀请,即日起至2024年7月18日,免费体验产品,并写下宝...

实时计算 Flink版产品使用问题之同步到Hudi的数据是否可以被Hive或Spark直接读取
问题一:Flink CDC这个应该在哪里配? Flink CDC这个应该在哪里配?mysql 的超时我已经改成30s了 参考答案: 要么找DBA改一下,要么自己去看有没有参数改,我们是10分钟,有的...
DataWorks产品使用合集之如何在DataWorks on EMR上创建Spark节点并指定DLF的catalog
问题一:DataWorks on emr 创建spark节点指定dlf的catalog? DataWorks on emr 创建spark节点指定dlf的catalog? 参考回答: 您可以按照以下步骤操作: 1、启动 EMR 集群:首先,您需要启动一个 EMR 集群。在 AWS Management Console 中,选择 "EMR" -&...
容器服务Kubernetes版产品使用合集之怎么实现把 spark 跑在k8s
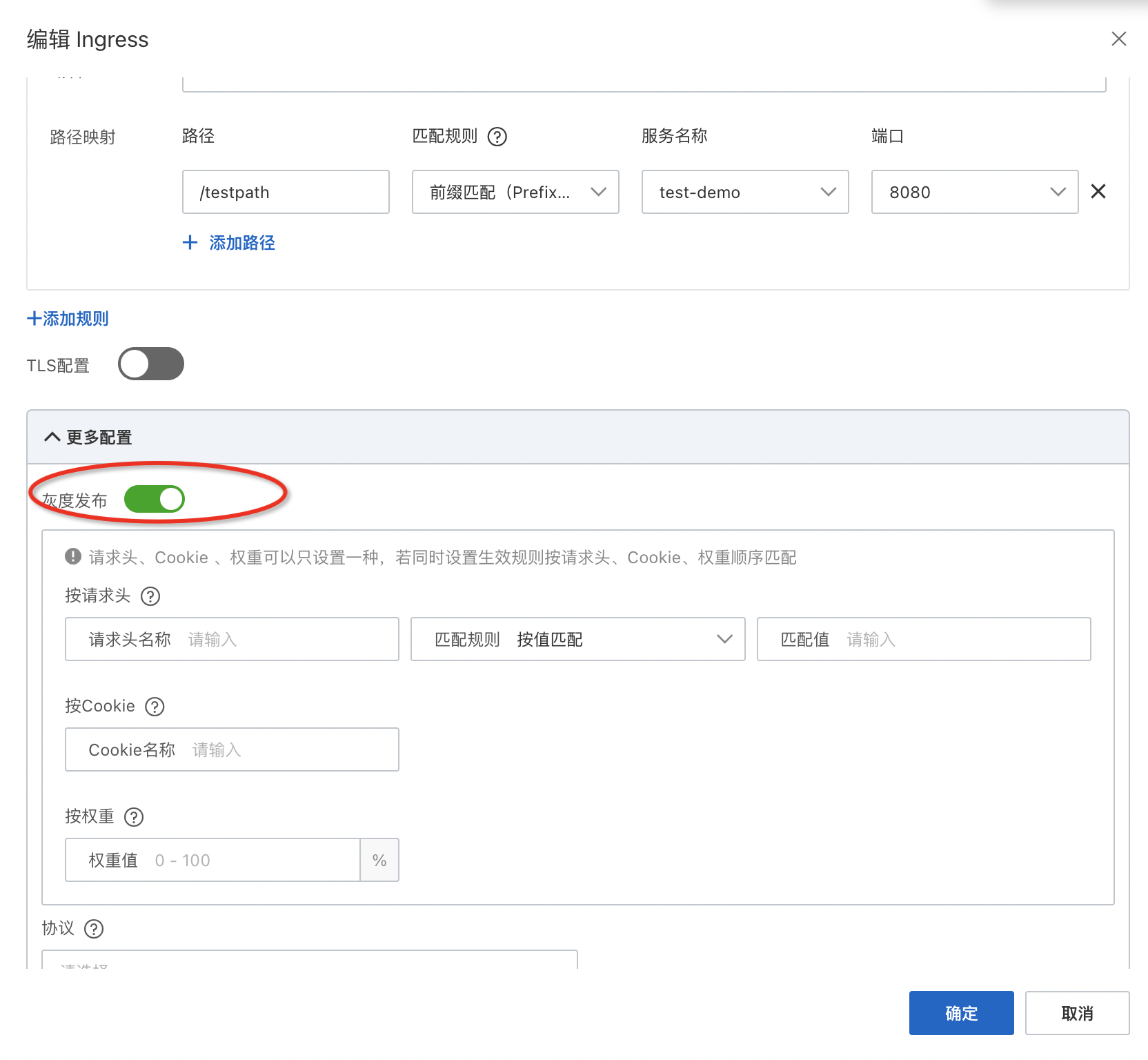
问题一:部署ingress,开启灰度后,mse网关没有注册路由,也无法访问ingress后段服务 不开启灰度 部署ingress,开启灰度后,mse网关没有注册路由,也无法访问ingress后段服务。 不开启灰度,是可以访问的 操作文档:参考https://help.aliyun.com/zh/mse/user-guide/use-mse-ingresses-t...
DataWorks产品使用合集之在DataWorks中,通过spark访问外网的步骤如何解决
问题一:DataWorks如何通过spark访问外网呢? DataWorks如何通过spark访问外网呢? 参考回答: 在DataWorks中创建一个支持外网访问的虚拟私有云(VPC),并将Spark作业所在的节点加入到该VPC中。这样,作业就可以通过VPC访问外部网络。 关于本问题的更多回答可点击原文查看:https://devel...
老哥 我们想在客户的内网部署我们的产品后,在maxcompute上提交spark离线任务,但是这个?
问题1:老哥 我们想在客户的内网部署我们的产品后,在maxcompute上提交spark离线任务,但是这个离线任务的数据来自客户他们的mysql 或者其他数据源 你知道怎么访问吗? 我在官网上找到maxcompute spark访问vpc, 但是客户他们自己的产品可能不是部署在阿里云上的 问题2:客户网络怎么跟阿里云打通啊?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark产品相关内容
apache spark您可能感兴趣
- apache spark安装
- apache spark日志
- apache spark分析
- apache spark应用
- apache spark OSS
- apache spark机制
- apache spark缓存
- apache spark rdd
- apache spark湖仓
- apache spark lakehouse
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark操作
- apache spark技术
- apache spark yarn
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注