
关于Scrapy爬虫项目运行和调试的小技巧(下篇)
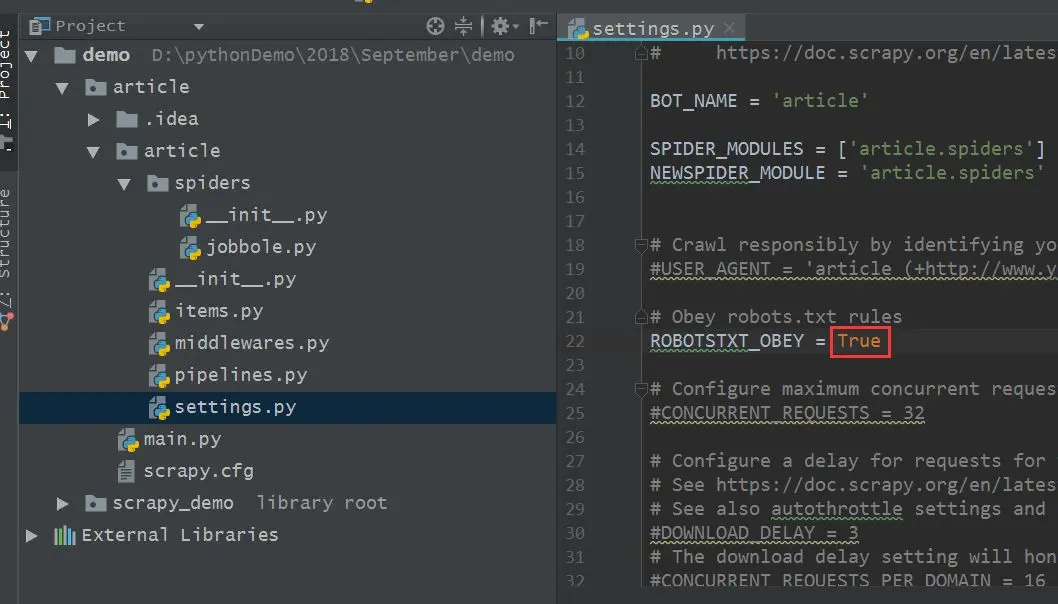
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下。今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧。 三、设置网站robots.txt规则为False 一般的,我们在运用Scrapy框架抓取数据之前,需要提前到settings.py文件中,将“ROBOTSTXT_OBEY = True”改为ROBOTSTXT....
关于Scrapy爬虫项目运行和调试的小技巧(上篇)
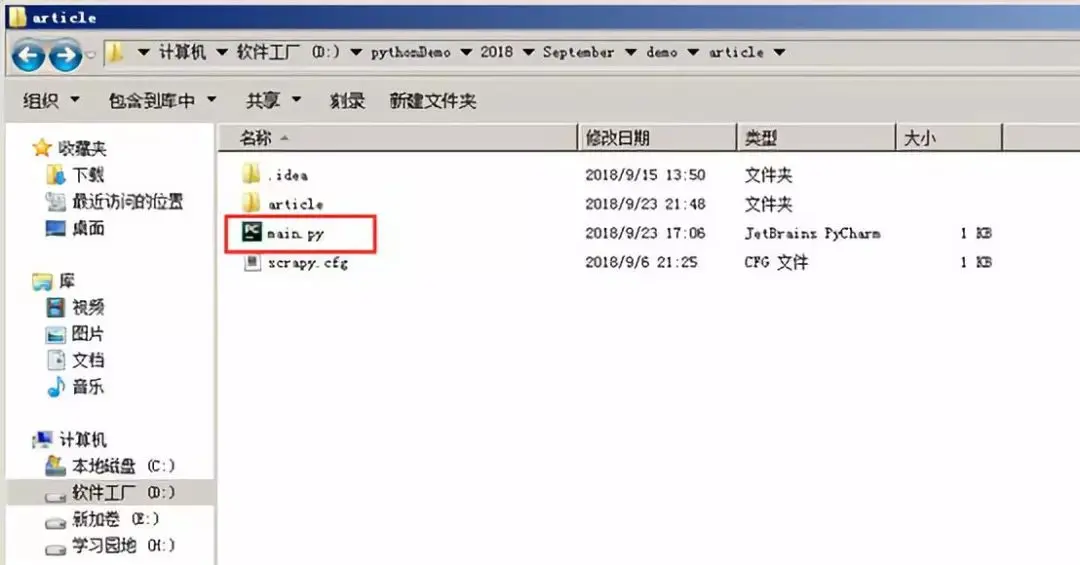
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了。在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫。 一、建立main.py文件,直接在Pycharm下进行调试 很多时候我们在使用Scrapy爬虫框架的时候,如果想运行Scrapy爬虫项目的话,一般都会想着去命令行中直接执行命令“scrapy craw...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注