
【JAVA】基于Guava实现本地缓存
使用Guava实现本地缓存 1、首先,导入pom依赖 <dependency> <groupId>com.google.guava</groupId> <artifactId>gua...
Caffeine Cache~高性能 Java 本地缓存之王
为什么要用Caffeine缓存: 高性能:Caffeine 提供了极快的读取和写入性能,特别是在高并发场景下表现出色。 API设计:它的API设计受到了Google Guava缓存的启发,并在此基础上进行改进与优化。 回收策略:Caffeine 支持基于大小的回收策略、基于时间的回收策略以及基于引用的回收策略,这些策略可以帮助用户根据不同的应用场景选择最合...
Java本地缓存
Java本地缓存Java实现本地缓存的方式有很多,其中比较常见的有HashMap、Guava Cache、Caffeine和Encahche等。这些缓存技术各有优缺点,你可以根据自己的需求选择适合自己的缓存技术。以下是一些详细介绍:HashMap:通过Map的底层方式,直接将需要缓存的对象放在内存中。优点是简单粗暴,不需要引入第三方包,比较适合一些比较简单的场景。缺点是没有缓存淘汰策略,定制化开....
Java设计本地缓存
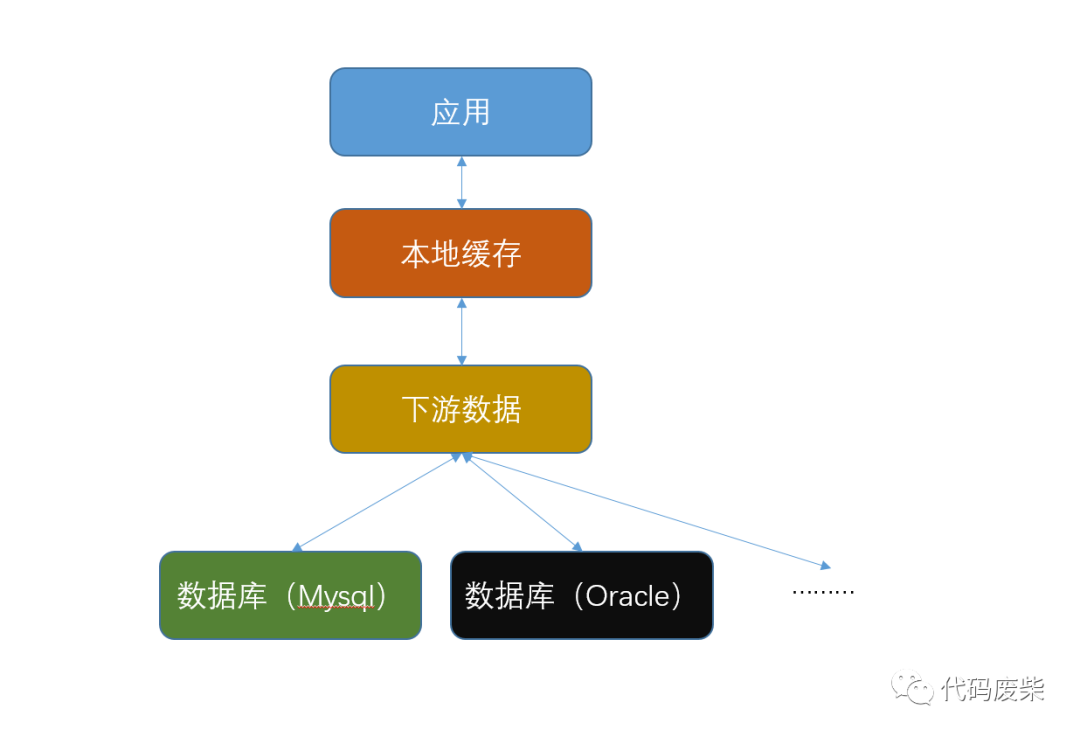
正文本地缓存实际上就是将数据存储在自己的应用中,没有存储到其他的位置,例如:Redis等等。本地缓存的一大好处是处理速递极快而且不需要访问下游的数据,但是,它也存在缺点。当一个应用是集群的方式部署的时候,由于本地缓存信息缺乏信息共享的能力,所以,同一个数据会存在多个应用中,有可能造成结果的不一致性。但是,我们也是离不开本地缓存的,我们可以设计成下面这样,可以有效地解决网络延时问题。今天给大家介绍....
Java本地缓存框架系列-Caffeine-1. 简介与使用
Caffeine 是一个基于Java 8的高性能本地缓存框架,其结构和 Guava Cache 基本一样,api也一样,基本上很容易就能替换。 Caffeine 实际上就是在 Guava Cache 的基础上,利用了一些 Java 8 的新特性,提高了某些场景下的性能效率。这一章节我们会从 Caffeine 的使用引入,并提出一些问题,之后分析其源代码解决这些问题来让我们更好的去了解 Caffe....
我从mysql读出来一个stream,想给他放到一个类似java的本地缓存里,让所有的线程都能读写,
能直接放caffeine里吗?我看flink介绍,可能会启动多个jvm,我在想放入caffeine会不会不行?要是不行,放哪里呢?就是一些基础数据,来数据时候,会根据来的id,去基础数据找name,想放本地缓存,这样不用每次读mysql了。就是程序加载时,我先从mysql直接读出来数据列表,按您说的放入算子状态,然后启动后,mysql数据有变化了,比如id对应的name改掉了,这时候同步工具会把....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

Java开发者
Java开发者成长课堂,课程资料学习,实战案例解析,Java工程师必备词汇等你来~
+关注