
构建高效的Python爬虫系统
在当今这个信息爆炸的时代,互联网成为了一个巨大的数据源。对于研究人员、开发者和企业来说,能够有效地从网上搜集和处理信息变得尤为重要。Python作为一门强大的编程语言,其简单易学的特性使它成为编写爬虫程序的首选语言之一。下面,我们将一步步探讨如何使用Python构建一个高效的爬虫系统。 首先,让我们理解什么是网络爬虫。简单来说...
爬虫系统学习
详细了解一下爬虫 #1爬虫究竟是合法还是违法的? # 在法律上不被禁止 算是中立性 # 2爬虫所带来风险主要体现在以下2个方面: # 爬虫干扰了被访问网站的正常运营; # 爬虫抓取了受到法律保护的特定类型的数据或信息。 # 爬虫的分类 # 通用爬虫:通用爬虫...
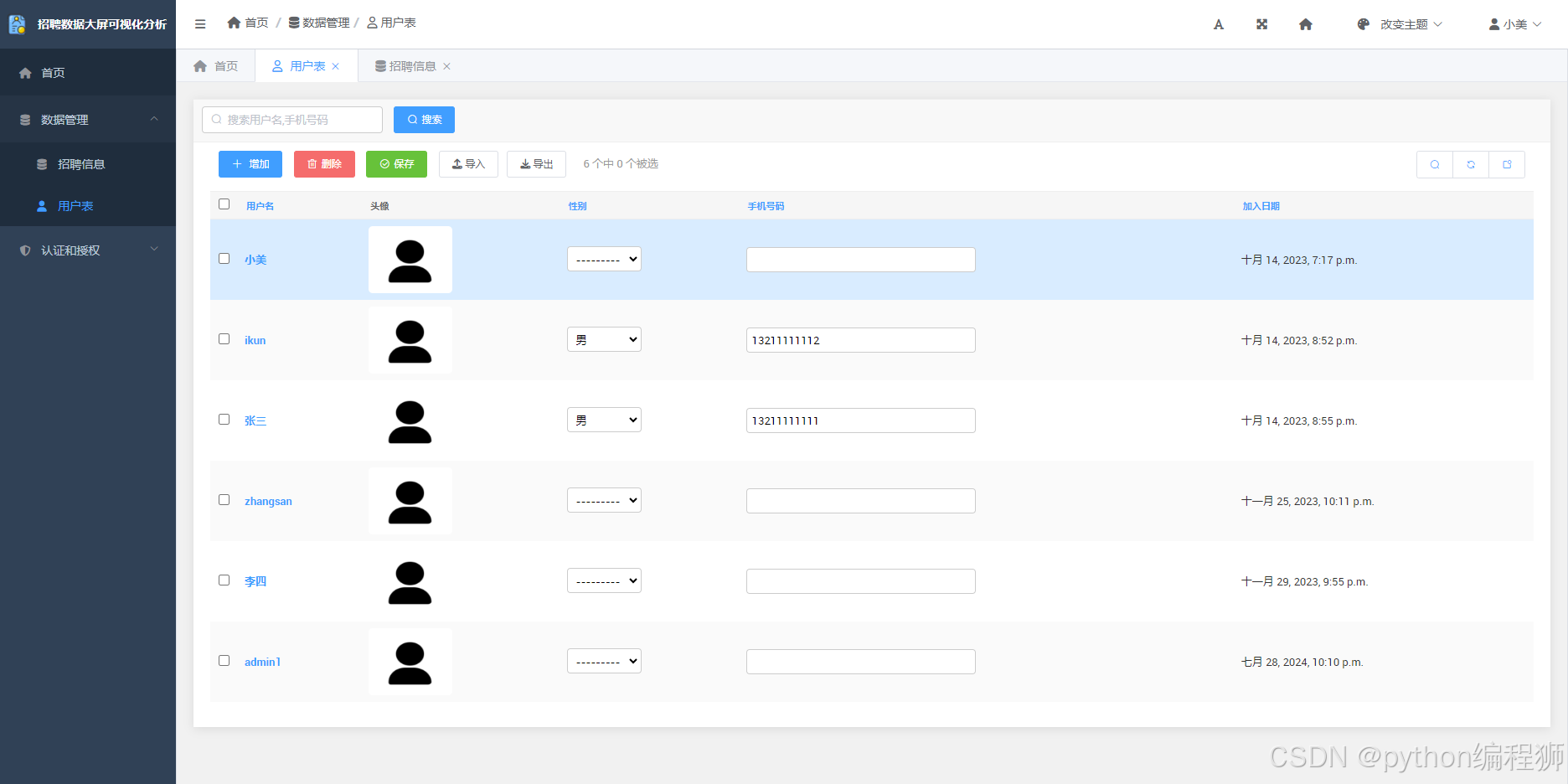
基于爬虫和机器学习的招聘数据分析与可视化系统,python django框架,前端bootstrap,机器学习有八种带有可视化大屏和后台
在现代招聘领域,数据驱动的决策已成为提升招聘效率和质量的关键因素。基于爬虫技术和机器学习算法,结合Django框架和Bootstrap前端技术,我们开发了一套完整的招聘数据分析与可视化系统。该系统旨在帮助企业从海量招聘信息中提取有价值的数据,进行深入的分析和预测,从而优化招聘策略。 系统架构与技术栈 数据获取与处理 系统使用Python编写的爬虫程序,定期从主流招聘网站(如前程无忧等)自动...
使用多进程和 Scrapy 实现高效的 Amazon 爬虫系统
在这篇博客中,将展示如何使用多进程和 Scrapy 来构建一个高效的 Amazon 爬虫系统。通过多进程处理,提高爬虫的效率和稳定性,同时利用 Redis 进行请求调度和去重。 项目结构 Scrapy 爬虫:负责从 Amazon 抓取数据。 MongoDB:存储待爬取的链接。 Redis:用于请求调度和去重。 多进程管理:通过 Pytho...
构建高效爬虫系统:设计思路与案例分析
构建高效爬虫系统:设计思路与案例分析 引言 在信息爆炸的数字时代,爬虫技术成为获取网络数据的重要手段。一个优秀的爬虫系统不仅要高效稳定,还需具备良好的扩展性和健壮性。本文将探讨爬虫系统的常见模块结构,评估项目复杂性的维度,并结合案例分析如何设计一个适应复杂场景的爬虫系统。 爬虫系统的关键模块 1. 爬虫引擎(Cr...
在 Django 中设计爬虫系统的数据模型与多对多关系
在构建爬虫系统时,设计合理的数据模型和多对多关系对系统的性能和可维护性至关重要。本文将探讨如何使用 Django 来设计爬虫系统的数据模型。 1. 数据模型设计 在设计爬虫系统的数据模型时,我们需要考虑以下关键因素: 用户信息:包括用户的基本信息和角色。 爬虫任务:描述爬虫任务的相关信息,如任务名称、起始 URL、采集状态等。 爬虫结果:爬...
爬虫系统的核心:如何创建高质量的HTML文件?
在网页抓取或爬虫系统中,HTML文件的创建是一项重要的任务。HTML文件是网页的基础,包含了网页的所有内容和结构。在爬虫系统中,我们需要生成一个HTML文件,以便于保存和处理网页的内容。在这种情况下,可以使用Java函数来实现将爬取到的网页内容保存为HTML文件的功能。具体来说,当爬虫系统获取到需要保存的网页内容时,它可以通过调用以下Java函数,将网页内容作为参数传递给函数。函数会根据给定的文....

使用多线程爬虫提高商品秒杀系统的吞吐量处理能力
在当今电商行业中,商品秒杀活动已经成为四大电商平台争相推出的一种促销方式。然而,随着用户数量的增加和秒杀活动的火爆,商品秒杀系统面临着巨大的为了提高系统的并发处理能力,我们需要寻找一种高效的解决方案。为了提高商品秒杀系统的并发处理能力,我们决定采用多线程爬虫的解决方案。通过使用多线程技术,我们可以同时处理多个请求...
构建可扩展的分布式爬虫系统
在大规模数据采集和爬虫任务中,构建可扩展的分布式爬虫系统是至关重要的。本文将介绍分布式爬虫系统的概念、优势以及构建过程中的关键技术,同时通过实际爬取示例为大家提供参考。分布式爬虫系统概述: 分布式爬虫系统是指将爬虫任务分解为多个子任务,并在多台机器上同时执行,以提高爬取效率和处理能力。它具有以下优势:● 高效的数据采集:通过并行处理和分布式架构,可以同时爬取多个网页,提高数据采集速度。● 高可扩....
基于springboot+vue+爬虫实现电影推荐系统
一,项目简介 这是一个前后端分离的电影管理和推荐系统,采用Vue.js + Spring Boot技术栈开发,电影数据来源于豆瓣,采用Python爬虫进行爬取相关电影的数据,将数据插入MYSQL数据库,然后在前端进行数据展示。后台主要进行电影相关基本数据的管理功能。给用户推荐的电影数据写入到REDIS数据库中进行存储。推荐算法采用协同过滤算法,采用于ItemCF和UserCF相结合的方式来进行.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注