
【云计算与大数据计算】Hadoop MapReduce实战之统计每个单词出现次数、单词平均长度、Grep(附源码 )
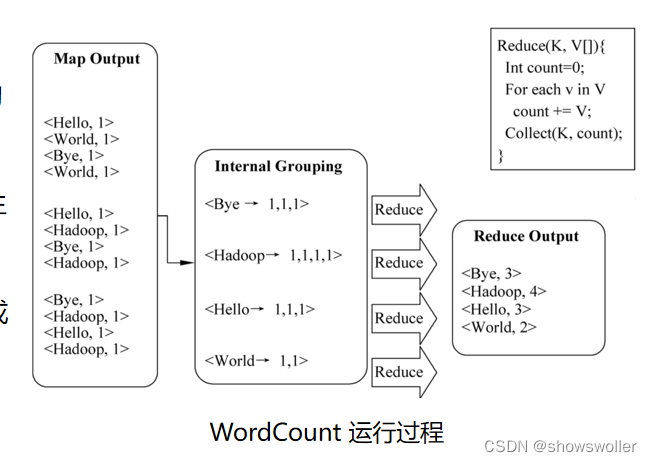
需要全部代码请点赞关注收藏后评论区留言私信~~~下面通过WordCount,WordMean等几个例子讲解MapReduce的实际应用,编程环境都是以Hadoop MapReduce为基础一、WordCountWordCount用于计算文件中每个单词出现的次数,非常适合采用MapReduce进行处理,处理单词计数问题的思路很简单,在 Map阶段处理每个文本split中的数据,产生<word....
【云计算与大数据技术】Hadoop MapReduce的讲解(图文解释,超详细必看)
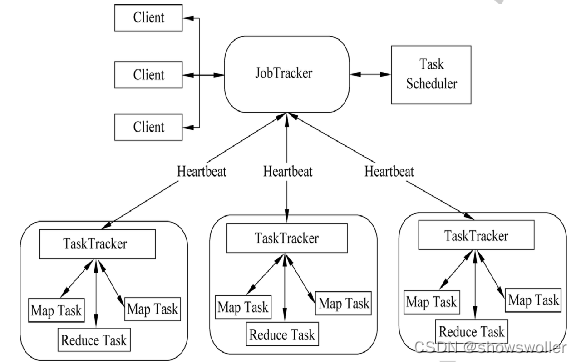
一、Hadoop MapReduce架构MapReduce 是一种分布式计算框架,能够处理大量数据 ,并提供容错 、可靠等功能 , 运行部署在大规模计算集群中,MapReduce计算框架采用主从架构,由 Client、JobTracker、TaskTracker组成Client的作用用户编写 MapReduce程序,通过Client提交到JobTrackerJobTracker的作用JobTra....
【云计算与大数据计算】分布式处理CPU多核、MPI并行计算、Hadoop、Spark的简介(超详细)
一、CPU多核和POISX Thread为了提高任务的计算处理能力,下面分别从硬件和软件层面研究新的计算处理能力在硬件设备上,CPU 技术不断发展,出现了SMP(对称多处理器)和 NUMA(非一致 性内存访问)两种高速处理的 CPU 结构 在软件层面出现了多进程和多线程编程。进程是内存资源管理单元,线程是任务调度单元总的来说,线程所占用的资源更少,运行一个线程所需要的资源包括寄存器,栈,程序计数....

【云计算与大数据技术】大数据系统总体架构概述(Hadoop+MapReduce )
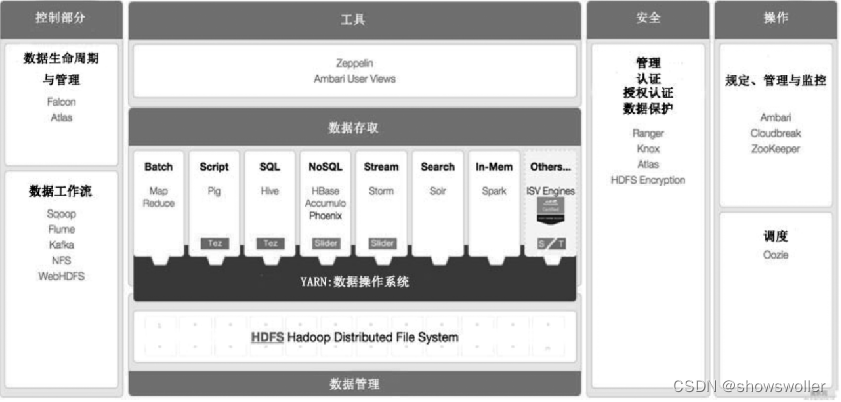
一、总体架构设计原则企业级大数据应用框架需要满足业务的需求,一是要求能够满足基于数据容量大,数据类型多,数据流通快的大数据基本处理需求,能够支持大数据的采集,存储,处理和分析,二是要能够满足企业级应用在可用性,可靠性,可扩展性,容错性,安全性和隐私性等方面的基本准则,三是要能够满足用原始技术和格式来实现数据分析的基本要求满足大数据的V3要求 大数据容量的加载、处理和分析 - 要求大数....
(超详细)0基础利用python调用Hadoop,云计算3
3.5 配置历史服务器为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:1)配置mapred-site.xml[atguigu@hadoop102 hadoop]$ vim mapred-site.xml在该文件里面增加如下配置。<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhisto...
(超详细)0基础利用python调用Hadoop,云计算2
Hadoop运行模式1)Hadoop官方网站:http://hadoop.apache.org/2)Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。**伪分布式模式:**也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。**完全分布式模式:**多台....
(超详细)0基础利用python调用Hadoop,云计算1
第一章配置Hadoop前言本次我们python+大数据的作业我选择附加一利用hadoop+python实现,最近考完试有时间来完成。这次我们用到的是Hadoop,利用python进行操作首先我们要配置我们的虚拟机简介: MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:(1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastru....

Hadoop生态系统中的云计算与容器化技术:Apache Mesos和Docker的应用
Hadoop生态系统中的云计算与容器化技术:Apache Mesos和Docker的应用 引言:在当今大数据时代,Hadoop生态系统已经成为处理大规模数据的标准工具。然而,传统的Hadoop集群管理方式存在一些问题,例如资源利用率低、维护困难等。为了解决这些问题,云计算和容器化技术成为了Hadoop生态系统中的...
云计算与大数据实验二 Hadoop的安装和集群的搭建
一、实验目的理解Hadoop集群架构和工作原理掌握Hadoop安装环境和步骤掌握Hadoop安装过程的配置,集群的搭建和启动二、实验内容Hadoop安装和JDK环境准备集群的搭建和启动三、实验步骤配置JavaJDK首先在右侧命令行中创建一个/app文件夹,我们之后的软件都将安装在该目录下。 命令:mkdir /app然后,切换到/opt目录下,来查看一下提供的压缩包。现在我们解压JDK并将其移动....

Hadoop集群搭建记录 | 云计算[CentOS7] | 伪分布式集群 Master运行WordCount
写在前面本系列文章索引以及一些默认好的条件在传送门step1 eclipse访问hadoop首先需要明确eclipse安装目录,然后将hadoop-eclipse-plugin_版本号.jar插件放在安装目录的dropins下关于插件,可以通过博主上传到csdn的免费资源获取,链接具体版本可以自己选择:step2 重启并配置eclipse在eclipse界面中依次选择:Window→show v....
![Hadoop集群搭建记录 | 云计算[CentOS7] | 伪分布式集群 Master运行WordCount](https://ucc.alicdn.com/pic/developer-ecology/8db086b3d68c4d61a1e9ece1cabd856e.png)
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

云计算
时时分享云计算技术内容,助您降低 IT 成本,提升运维效率,使您更专注于核心业务创新。
+关注