
技术好文:Spark机器学习笔记一
Spark机器学习库现支持两种接口的API:RDD-based和DataFrame-based,Spark官方网站上说,RDD-based APIs在2.0后进入维护//代码效果参考:http://hnjlyzjd.com/xl/wz_25104.html 模式,主要的机器学习API是spark-ml包中的DataFrame-based A...
pyspark笔记(RDD,DataFrame和Spark SQL)2
23.pyspark.sql.functions.date_format(date, format)将日期/时间戳/字符串转换为由第二个参数给定日期格式指定格式的字符串值。一个模式可能是例如dd.MM.yyyy,可能会返回一个字符串,如“18 .03.1993”。可以使用Java类java.text.SimpleDateFormat的所有模式字母。注意:尽可能使用像年份这样的专业功能。这些受益于....
pyspark笔记(RDD,DataFrame和Spark SQL)1
RDD和DataFrame1.SparkSession 介绍SparkSession 本质上是SparkConf、SparkContext、SQLContext、HiveContext和StreamingContext这些环境的集合,避免使用这些来分别执行配置、Spark环境、SQL环境、Hive环境和Streaming环境。SparkSession现在是读取数据、处理元数据、配置会话和管理集群....
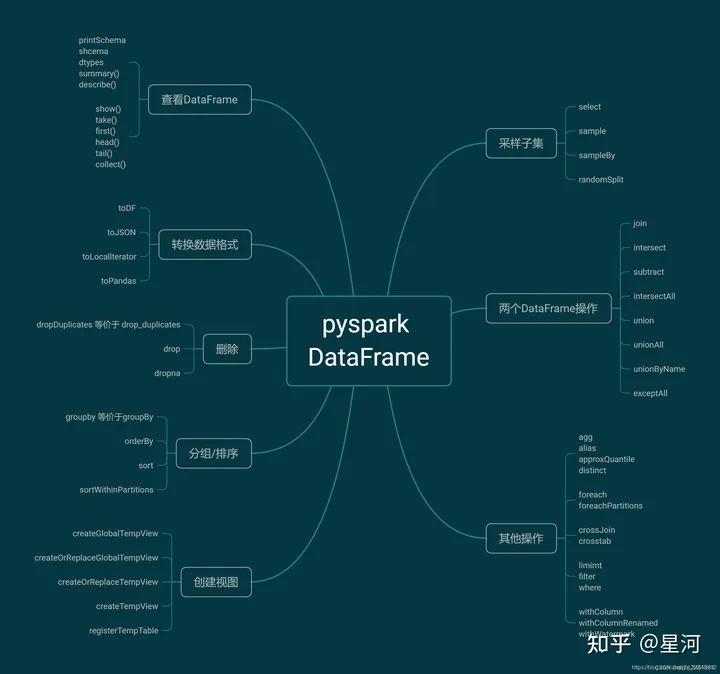
Spark笔记(pyspark)2
6.SparkSQL 数据清洗API1.去重方法 dropDuplicates功能:对DF的数据进行去重,如果重复数据有多条,取第一条2.删除有缺失值的行方法 dropna功能:如果数据中包含null,通过dropna来进行判断,符合条件就删除这一行数据3.填充缺失值数据 fillna功能:根据参数的规则,来进行null的替换7.DataFrame数据写出spark.read.format()和....

Spark笔记(pyspark)1
Spark是什么:Spark是基于内存的迭代式计算引擎1、基本概念RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系Executor:是运行在工作节点(WorkerNode)的一个进程,负责....

Scala写Spark笔记
学习感悟(1)配置环境最费劲(2)动手写,动手写,动手写WordCountpackage wordcount import org.apache.spark.{SparkConf, SparkContext} /** * @author CBeann * @create 2019-08-10 18:02 */ object WordCount { def main(args: A...
Spark Shell笔记
学习感悟(1)学习一定要敲,感觉很简单,但是也要敲一敲,不要眼高手低(2)一定要懂函数式编程,一定,一定(3)shell中的方法在scala写的项目中也会有对应的方法(4)sc和spark是程序的入口,直接用SparkShell启动SparkShell./bin/spark-shellWordCount案例sc.textFile("hdfs://iZm5ea99qngm2v98asii1aZ:9....
五、【计算】Spark原理与实践(下) | 青训营笔记
引言学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。 热爱写作,愿意让自己成为更好的人............铭记于心✨我唯一知道的,便是我一无所知✨三、SparkSQL:1 名词解析DataFrame: 是一种以RDD为基础的分布式数据集, 被称为SchemaRDDCatalyst:SparkSQL核心模块,主要是对执行过程中的执行计划进行处理和优化DataS....

Spark Streaming实时流处理项目实战笔记——使用KafkaSInk将Flume收集到的数据输出到Kafka
Flume配置文件a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = hadoop a1.sources.r1.port = 44444 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.si....
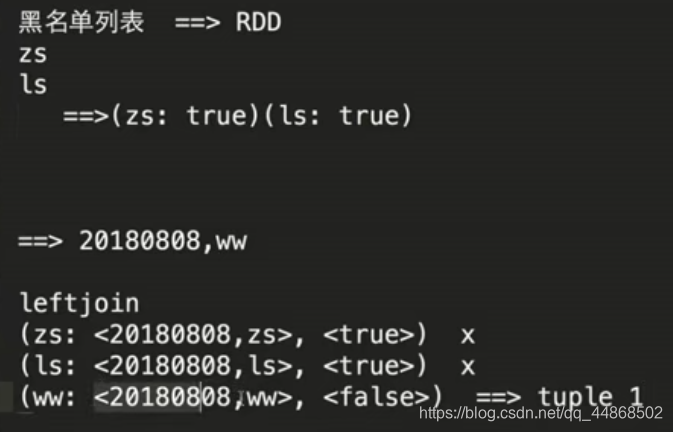
Spark Streaming实时流处理项目实战笔记——实战之黑名单过滤
思路源代码窗口函数 代码实现object Black extends App { import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} val sparkConf = new SparkConf().setMaster("local[2]")....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark笔记相关内容
apache spark您可能感兴趣
- apache spark任务管理
- apache spark训练
- apache spark特征
- apache spark实战
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark yarn
- apache spark技术
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注