
大数据-83 Spark 集群 RDD编程简介 RDD特点 Spark编程模型介绍
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...


Spark【基础知识 01】【简介】(部分图片来源于网络)
Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目。相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架。 1.特点 Apache Spark 具有以下特点: 使用先进的 DA...

Spark MLlib简介与机器学习流程
在大数据领域,机器学习是一个关键的应用领域,可以用于从海量数据中提取有价值的信息和模式。Apache Spark MLlib是一个强大的机器学习库,可以在分布式大数据处理环境中进行机器学习任务。本文将深入介绍Spark MLlib的基本概念、机器学习流程以及提供详细的示例代码。 什么是Spark MLlib? Spark MLlib是Apache Spark的机器学习库,旨在简化大规模数据的...
实时数据处理概述与Spark Streaming简介
实时数据处理已经成为当今大数据时代的一个重要领域,它使组织能够及时分析和采取行动,以应对不断变化的数据。Spark Streaming是Apache Spark生态系统中的一个模块,专门用于实时数据处理。本文将深入探讨实时数据处理的概念,并介绍如何使用Spark Streaming来处理实时数据流。 什么是实时数据处理? 实时数据处理是一种处理流式数据的方法,它使组织能够在数据产生后立即对其...
Spark SQL简介与基本用法
Apache Spark是一个强大的分布式计算框架,Spark SQL是其组件之一,用于处理结构化数据。Spark SQL可以使用SQL查询语言来查询和分析数据,同时还提供了与Spark核心API的无缝集成。本文将深入探讨Spark SQL的基本概念和用法,包括数据加载、SQL查询、数据源和UDF等内容。 Spark SQL简介 Spark SQL是Apache Spark的一个模块,用于处...

Apache Spark简介与历史发展
在当今信息爆炸的时代,大数据处理已成为了现实。企业和组织需要处理海量数据来获得有用的信息和见解。Apache Spark作为一个开源的大数据处理框架,已经在大数据领域占据了重要地位。 Apache Spark简介 Apache Spark是一个用于大规模数据处理的快速、通用的计算引擎。与传统的大数据处理框架相比,Spark具有很多优势,其中包括: 高性能 Spark通过内存计算来提高性能...

[AIGC] Apache Spark 简介
Apache Spark是一个开源的大数据处理框架,它提供了高效的分布式数据处理和分析能力。Spark通过将数据加载到内存中进行计算,可以大幅提高数据处理速度。以下是Apache Spark的几个基本概念:弹性分布式数据集(RDD):RDD是Spark的核心抽象,它是一个被划分成多个分区的不可变的分布式对象集合。RDD可以并行处理,同时具有容错性和恢复能力。转换操作:Spark提供了一系列的转换....
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。2)Cha....
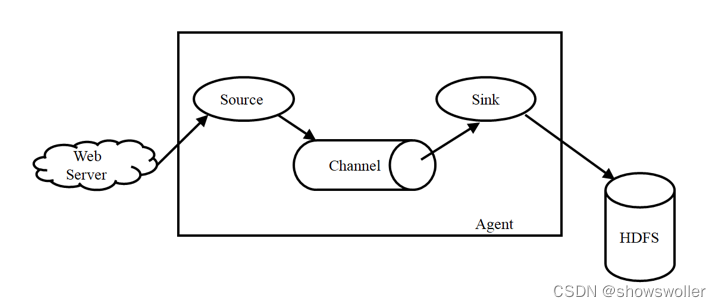
【云计算与大数据计算】分布式处理CPU多核、MPI并行计算、Hadoop、Spark的简介(超详细)
一、CPU多核和POISX Thread为了提高任务的计算处理能力,下面分别从硬件和软件层面研究新的计算处理能力在硬件设备上,CPU 技术不断发展,出现了SMP(对称多处理器)和 NUMA(非一致 性内存访问)两种高速处理的 CPU 结构 在软件层面出现了多进程和多线程编程。进程是内存资源管理单元,线程是任务调度单元总的来说,线程所占用的资源更少,运行一个线程所需要的资源包括寄存器,栈,程序计数....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark简介相关内容
apache spark您可能感兴趣
- apache spark检查
- apache spark场景
- apache spark应用
- apache spark机器学习
- apache spark依赖
- apache spark任务
- apache spark rdd
- apache spark ha
- apache spark master
- apache spark运行
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark实战
- apache spark操作
- apache spark技术
- apache spark yarn
- apache spark程序
- apache spark报错
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注