
经验大分享:scrapy框架爬取糗妹妹网站qiumeimei.com图片
1. 创建项目 scrapy startproject qiumeimei2. 建蜘蛛文件qiumei.py cd qiumeimei scrapy genspider qiumei 3. 考虑到只需要下载图片,先在items.py定义字段?123456import scrapy class QiumeimeiItem(scrapy.Item): # define th...
Scrapy爬虫:利用代理服务器爬取热门网站数据
在当今数字化时代,互联网上充斥着大量宝贵的数据资源,而爬虫技术作为一种高效获取网络数据的方式,受到了广泛的关注和应用。本文将介绍如何使用Scrapy爬虫框架,结合代理服务器,实现对热门网站数据的高效爬取,以抖音为案例进行说明。 简介Scrapy是一个强大的Python爬虫框架,具有高效的数据提取功能...
构建一个简单的电影信息爬虫项目:使用Scrapy从豆瓣电影网站爬取数据
Scrapy 是一个用 Python 编写的开源框架,它可以帮助你快速地创建和运行爬虫项目,从网页中提取结构化的数据。Scrapy 有以下几个特点: 高性能:Scrapy 使用了异步网络库 Twisted,可以处理大量的并发请求,提高爬取效率。 灵活:Scrapy 提供了丰富的组件和中间件,可以让你定制和扩展爬虫的功能,例如设置代理、更换 User-Agent、处理重定向、过滤重复请求等...

Scrapy和Django实现蚌埠医学院手机新闻网站制作
最终效果(不看效果就讲过程都是耍流氓): 实现过程如下: 框架: Scrapy:数据采集 Django:数据呈现 目标网站:蚌埠医学院 学院新闻列表:http://www.bbmc.edu.cn/index.php/view/viewcate/0/ 第一步:数据抓取 新建爬虫项目 在终端中执行命令 srapy startproject bynews 执行完毕,自动新建好项目文件 编写爬虫代...

使用 Scrapy 建立一个网站抓取器
Scrapy 是一个用于爬行网站以及在数据挖掘、信息处理和历史档案等大量应用范围内抽取结构化数据的应用程序框架,广泛用于工业。在本文中我们将建立一个从 Hacker News 爬取数据的爬虫,并将数据按我们的要求存储在数据库中。安装我们将需要 Scrapy以及 BeautifulSoup用于屏幕抓取,SQLAlchemy用于存储数据.如果你使用ubuntu已经其他发行版的 unix 可以通过 p....

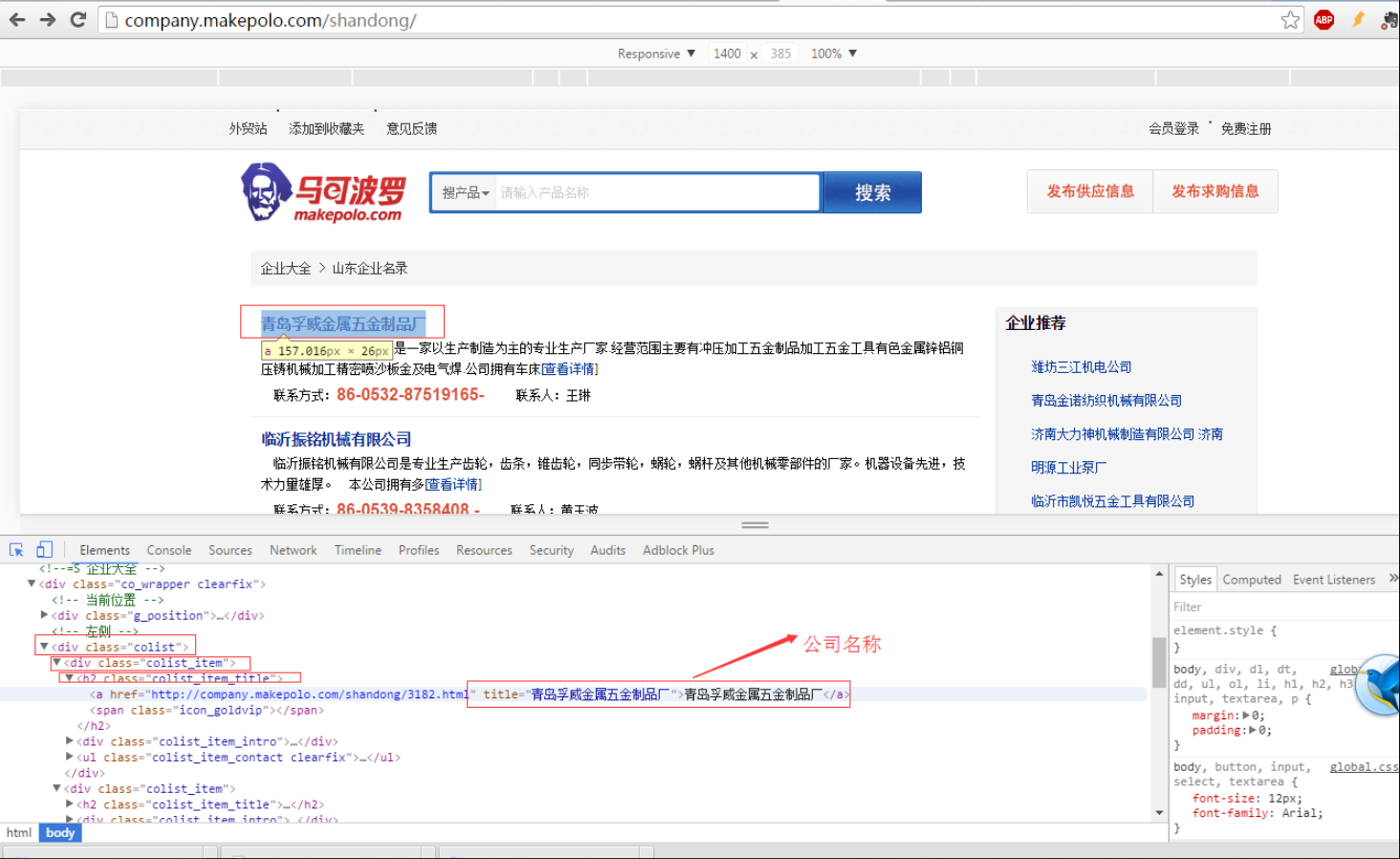
Scrapy爬取makepolo网站数据深入详解
题记之前对爬虫只是概念了解多,实战少。知道网上流行的有号称免费的八爪鱼等(实际导出数据收费)。大致知道,所有爬虫要实现爬取网页信息,需要定义正则匹配规则。这次,项目紧急,才知道“书到用时方恨少”,有限的理论知识是远远不够的。首先,Google搜索了不同语言实现的开源爬虫,C++、Java、Python、Ruby等。由于C++写的过于庞大,Java代码不太熟。Python虽也不熟悉,但看起来不费劲....
我用scrapy爬boss网站,一直给我重定向到一个security-check的一个网址怎么回事?
已经加了IP代理了,这个怎么回事 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
Scrapy爬取makepolo网站数据深入详解
题记 之前对爬虫只是概念了解多,实战少。知道网上流行的有号称免费的八爪鱼等(实际导出数据收费)。 大致知道,所有爬虫要实现爬取网页信息,需要定义正则匹配规则。 这次,项目紧急,才知道“书到用时方恨少”,有限的理论知识是远远不够的。 首先,Google搜索了不同语言实现的开源爬虫,C++、Java、Python、Ruby等。由于C++写的过于庞大,Java代码不太熟。 Python虽也不熟悉,但看....
Python干货:用Scrapy爬电商网站
电商老板,经理都可能需要爬自己经营的网站,目的是监控网页,追踪网站流量,寻找优化机会等。 对于其中的每一项,均可以通过离散工具,网络抓取工具和服务来帮助监控网站。只需相对较少的开发工作,就可以创建自己的站点爬网程序和站点监视系统。 构建自定义的爬虫站点和监控程序, 第一步是简单地获取网站上所有页面的列表。本文将介绍如何使用Python编程语言和一个名为Scrapy的整洁的Web爬网框架来轻松生成....

Scrapy使用随机User-Agent爬取网站
小哈.jpg 在爬虫爬取过程中,我们常常会使用各种各样的伪装来降低被目标网站反爬的概率,其中随机更换User-Agent就是一种手段。 在scrapy中,其实已经内置了User-Agent中间件, class UserAgentMiddleware(object): """This middleware allows spiders to override the user_agen...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注