
Python爬虫:Scrapy链接解析器LinkExtractor返回Link对象
LinkExtractorfrom scrapy.linkextractors import LinkExtractor Linkfrom scrapy.link import LinkLink四个属性url text fragment nofollow 如果需要解析出文本,需要在 LinkExtractor 的参数中添加参数:attrslink_extractor = LinkExtracto....
Python爬虫:scrapy框架log日志设置
Scrapy提供5层logging级别:1. CRITICAL - 严重错误 2. ERROR - 一般错误 3. WARNING - 警告信息 4. INFO - 一般信息 5. DEBUG - 调试信息logging设置通过在setting.py中进行以下设置可以被用来配置logging以下配置均未默认值# 是否启用日志 LOG_ENABLED=True # 日志使用的编码 LOG_ENCO....
python爬虫:scrapy框架xpath和css选择器语法
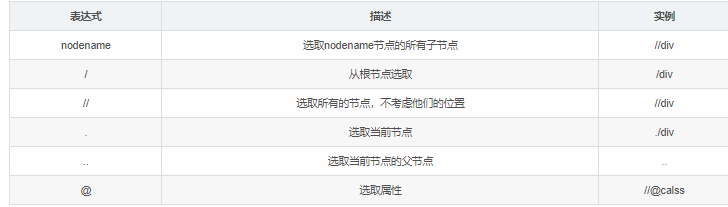
Xpath基本语法一、常用的路径表达式:举例元素标签为artical标签二、谓语谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点三、通配符Xpath通过通配符来选取未知的XML元素四、取多个路径使用“|”运算符可以选取多个路径五、Xpath轴轴可以定义相对于当前节点的节点集六、功能函数使用功能函数能够更好的进行模糊搜索注意事项:1) 按照审查元素的写法不一定正确,要按照网页源码....
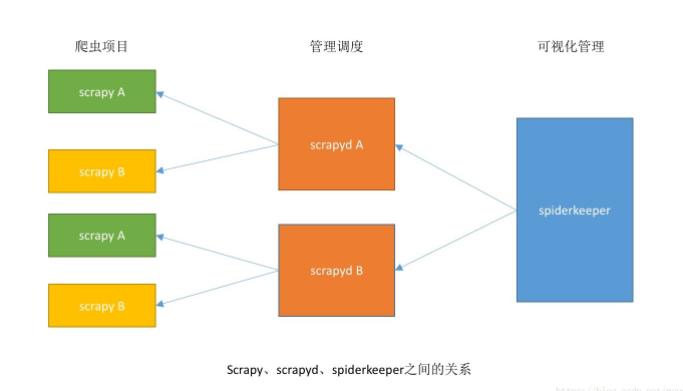
python爬虫:scrapy可视化管理工具spiderkeeper部署
需要安装的库比较多,可以按照步骤,参看上图理解环境准备scrapy: https://github.com/scrapy/scrapyscrapyd: https://github.com/scrapy/scrapydscrapyd-client: https://github.com/scrapy/scrapyd-clientSpiderKeeper: https://github.com/D....
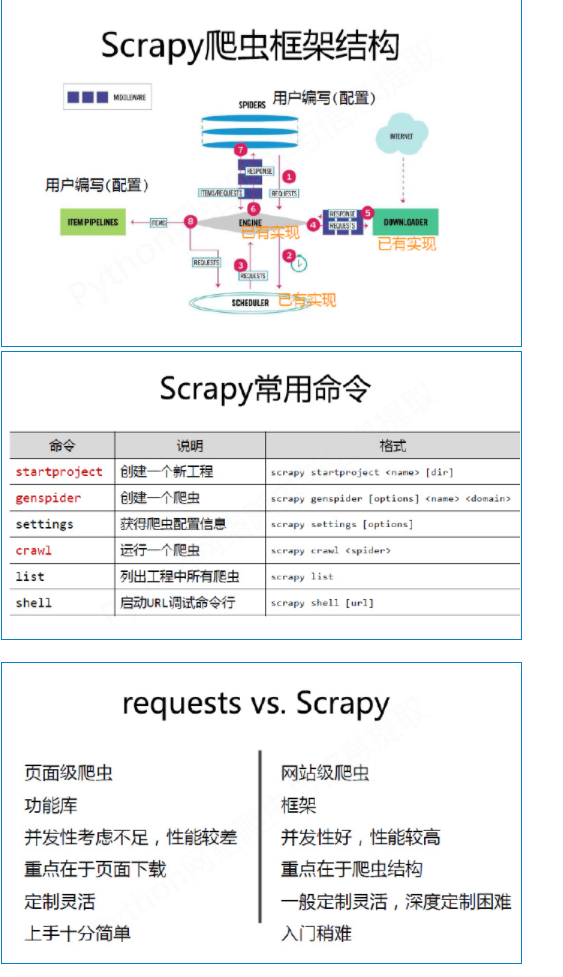
python爬虫:scrapy框架Scrapy类与子类CrawlSpider
Scrapy类name 字符串,爬虫名称,必须唯一,代码会通过它来定位spiderallowed_domains 列表,允许域名没定义 或 空: 不过滤,url不在其中: url不会被处理,域名过滤功能: settings中OffsiteMiddlewarestart_urls:列表或者元组,任务的种子custom_settings:字典,覆盖项目中的settings.pycrawler:Cra....
python爬虫:scrapy命令失效,直接运行爬虫
scrapy命令失效,直接运行爬虫,无论是什么命令,都直接运行单个爬虫出现这个错误,很意外原因是这样的:一开始,我写了个脚本单独配置爬虫启动项:# begin.py from scrapy import cmdline cmdline.execute("scrapy crawl myspider")这样一来会比较方便,不用每次都去命令行敲命令然而当我想运行其他爬虫的时候,直接就运行 myspid....
Python爬虫:scrapy爬取腾讯社招职位信息
三个文件代码如下:spdier.py# -*- coding: utf-8 -*- # author : pengshiyu # date : 2-18-4-19 import scrapy from scrapy.selector import Selector from tencent_position_item import TencentPositionItem import sys .....
【安全合规】python爬虫从0到1 - Scrapy框架的实战应用
文章目录前言(一)yield介绍(二)管道封装1 .创建项目和爬虫文件2.查找数据3.定义数据4.将数据传入管道(pipelines)5.通过管道下载数据(三)多条管道下载1.定义管道类2.在settings中开启管道3.下载数据前言在上文中我们学习了Scrapy框架的介绍,以及如何在scrapy框架中创建项目和创建/运行爬虫文件,那么接下来我们一起进入scrapy的实战应用吧!!(一)yiel....

Python爬虫:Scrapy与__file__引发的异常
报错问题项目代码中使用了__file__项目部署之后,想部署单个爬虫,读取spider-list出错查看 https://pypi.org/project/scrapyd-client/#id5作者说,要尽量避免使用__file__删除之后确实正常了。。。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注