
配置Pycharm的Scrapy爬虫Spider子类通用模板
Scrapy爬虫的模板比较单一,每次新建爬虫程序要么重新手敲一遍,要么复制粘贴从头手敲:效率较低,容易出错,浪费时间复制粘贴:老代码需要改动的地方较多,容易漏掉,导致出错所以,pycharm中配置一个模板文件就很重要了# -*- encoding: utf-8 -*- """ @Date : ${YEAR}-${MONTH}-${DAY} @Author : Peng Shiyu """...
Python爬虫:Scrapy的Crawler对象及扩展Extensions和信号Signa
先了解Scrapy中的Crawler对象体系Crawler对象settings crawler的配置管理器set(name, value, priority=‘project’)setdict(values, priority=‘project’)setmodule(module, priority=‘project’)get(name, default=None)getbool(name, d....
Python爬虫:Scrapy中间件Middleware和Pipeline
1、Spiderbaidu_spider.pyfrom scrapy import Spider, cmdline class BaiduSpider(Spider): name = "baidu_spider" start_urls = [ "https://www.baidu.com/" ] custom_settings = { ...
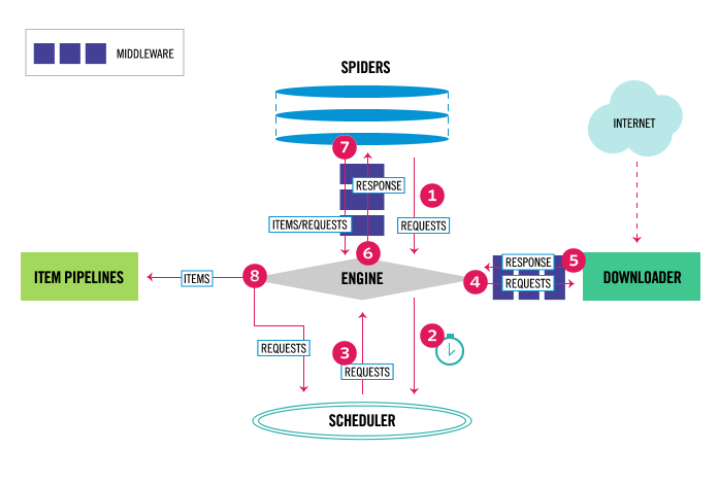
Python爬虫:Scrapy的get请求和post请求
scrapy 请求继承体系Request |-- FormRequest通过以下请求测试GET: https://httpbin.org/getPOST: https://httpbin.org/postget请求方式:通过Request 发送import jsonfrom scrapy import Spider, Request, cmdlineclass SpiderRequest(S...
Python爬虫:Scrapy调试运行单个爬虫
一般运行Scrapy项目的爬虫是在命令行输入指令运行的:$ scrapy crawl spider每次都输入还是比较麻烦的,偶尔还会敲错,毕竟能少动就少动Scrapy提供了一个命令行工具,可以在单个spider文件中加入以下代码:from scrapy import Spider, cmdline class SpiderName(Spider): name = "spider_name...
Python爬虫:scrapy辅助功能实用函数
scrapy辅助功能实用函数:get_response: 获得scrapy.HtmlResponse对象, 在不新建scrapy项目工程的情况下,使用scrapy的一些函数做测试extract_links: 解析出所有符合条件的链接代码示例以拉勾首页为例,获取拉勾首页所有职位链接,进一步可以单独解析这些链接,获取职位的详情信息import requests from scrapy.http im....
Python爬虫:python2使用scrapy输出unicode乱码
无力吐槽的python2,对中文太不友好了,不过在早期项目中还是需要用到没办法,还是需要解决我编写scrapy爬虫的一般思路:创建spider文件和类编写parse解析函数,抓取测试,将有用信息输出到控制台在数据库中创建数据表编写item编写model(配合pipline将item写入数据库)编写pipline运行爬虫项目,测试保存的数据正确性在第2步抓取测试的时候,我并没有创建数据库(因为我感....
Python爬虫:scrapy定时运行的脚本
原理:1个进程 -> 多个子进程 -> scrapy进程代码示例将以下代码文件放入scrapy项目中任意位置即可# -*- coding: utf-8 -*- # @File : run_spider.py # @Date : 2018-08-06 # @Author : Peng Shiyu from multiprocessing import Process fr...
Python爬虫:scrapy爬虫设置随机访问时间间隔
代码示例random_delay_middleware.py# -*- coding:utf-8 -*- import logging import random import time class RandomDelayMiddleware(object): def __init__(self, delay): self.delay = delay @class...
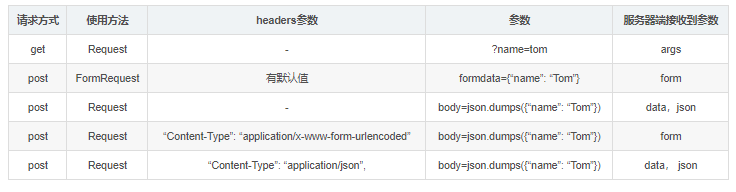
Python爬虫:scrapy利用html5lib解析不规范的html文本
问题当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,程序却解析不到在chrome、火狐测试都有这个情况。出现这种原因是因为浏览器会对html文本进行一定的规范化scrapy 使用的解析器是 lxml ,下面使用lxml解析,只是函数表达不一样,xpath和css选择器的语法一样安装解析器pip install beautifulsoup4 lxml html5li....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注