
Scrapy,作为一款强大的Python网络爬虫框架,凭借其高效、灵活、易扩展的特性,深受开发者的喜爱
一、引言 在当今信息化时代,网络爬虫作为数据收集与处理的得力工具,发挥着越来越重要的作用。Scrapy,作为一款强大的Python网络爬虫框架,凭借其高效、灵活、易扩展的特性,深受开发者的喜爱。本文将带领读者走进Scrapy的世界,探索其如何解锁网络爬虫新境界。 二、Scrapy框架的核心特性与优势 高效性Scr...
Scrapy:高效的网络爬虫框架
在大数据时代,信息的获取和处理变得至关重要。网络爬虫作为获取互联网信息的有效工具,已经广泛应用于数据挖掘、信息监测、搜索引擎等多个领域。而Scrapy,作为一款高效、可扩展的网络爬虫框架,以其独特的优势和广泛的应用场景,赢得了众多开发者的青睐。本文将从Scrapy的基本概念、工作原理、核心组件、应用场景以及使用技巧等方面,对其进行全面介绍。 一、Scr...
Python高效爬虫——scrapy介绍与使用
介绍 Scrapy是一个快速且高效的网页抓取框架,用于抓取网站并从中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。 相比于自己通过requests等模块开发爬虫,scrapy能极大的提高开发效率,包括且不限于以下原因: 它是一个异步框架,并且能通过配置调节并发量,还可以针对域名或ip进行精准控制 内置了xpath等提取器,...
Scrapy爬虫:利用代理服务器爬取热门网站数据
在当今数字化时代,互联网上充斥着大量宝贵的数据资源,而爬虫技术作为一种高效获取网络数据的方式,受到了广泛的关注和应用。本文将介绍如何使用Scrapy爬虫框架,结合代理服务器,实现对热门网站数据的高效爬取,以抖音为案例进行说明。 简介Scrapy是一个强大的Python爬虫框架,具有高效的数据提取功能...
【专栏】随着技术发展,Scrapy将在网络爬虫领域持续发挥关键作用
一、引言 在当今信息化时代,网络爬虫作为数据收集与处理的得力工具,发挥着越来越重要的作用。Scrapy,作为一款强大的Python网络爬虫框架,凭借其高效、灵活、易扩展的特性,深受开发者的喜爱。本文将带领读者走进Scrapy的世界,探索其如何解锁网络爬虫新境界。 二、Scrapy框架的核心特性与优势 高效性Scr...
Python爬虫面试:requests、BeautifulSoup与Scrapy详解
在Python爬虫开发的面试过程中,对requests、BeautifulSoup与Scrapy这三个核心库的理解和应用能力是面试官重点考察的内容。本篇文章将深入浅出地解析这三个工具,探讨面试中常见的问题、易错点及应对策略,并通过代码示例进一步加深理解。 1. requests:网络请求库 常见问题: 如何处理HTTP状态码异常? 如何处理代理设置、cookies管理及session...

项目配置之道:优化Scrapy参数提升爬虫效率
前言在当今信息时代,数据是无处不在且无比重要的资源。为了获取有效数据,网络爬虫成为了一项至关重要的技术。Scrapy作为Python中最强大的网络爬虫框架之一,提供了丰富的功能和灵活的操作,让数据采集变得高效而简单。本文将以爬取豆瓣网站数据为例,分享Scrapy的实际应用和技术探索。Scrapy简介Scrapy是一个基于Pyt...
深度剖析Selenium与Scrapy的黄金组合:实现动态网页爬虫
在当今互联网时代,大量网站采用动态网页技术呈现信息,这给爬虫技术提出了新的挑战。本文将带您深入探讨如何应对动态网页的爬取难题,结合Python爬虫框架Scrapy和自动化测试工具Selenium进行实战,为您揭示动态网页爬取的技术奥秘。动态网页与传统爬虫的对比传统爬虫主要通过直接请求页面获取静态源代码,但动态网页通过JavaS...
Scrapy:解锁网络爬虫新境界
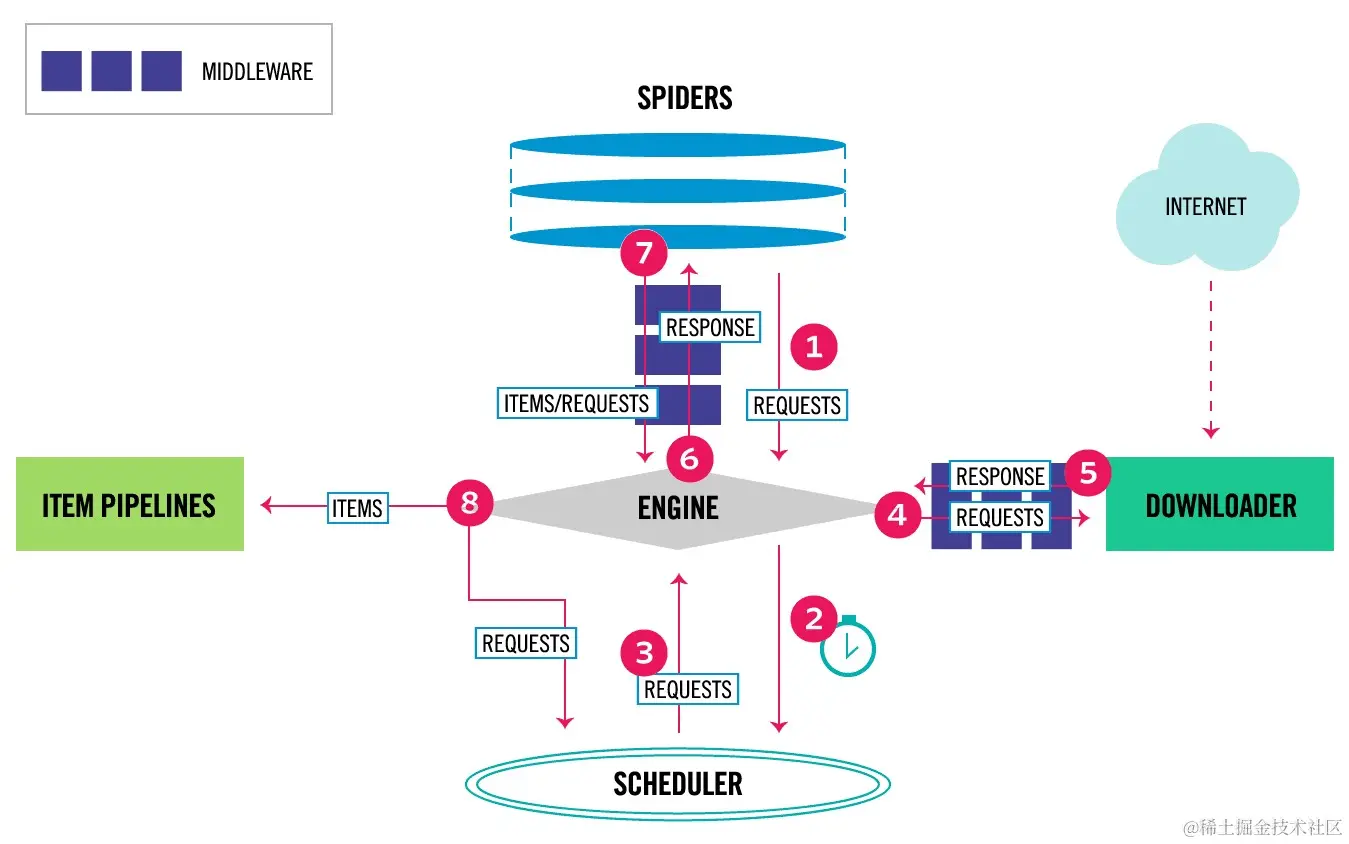
一、Scrapy的概念与背景Scrapy是一个基于Python的开源网络爬虫框架,它旨在简化开发者对网页数据的抓取过程。Scrapy的诞生源于对传统爬虫工具的不足,它采用了异步非阻塞的设计理念,通过多线程和事件驱动机制提高了爬取效率。同时,Scrapy还提供了一套完善的架构,包括调度器、下载器、解析器等组件,使得...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注