
Scrapy爬虫(3)爬取中国高校前100名并写入MongoDB
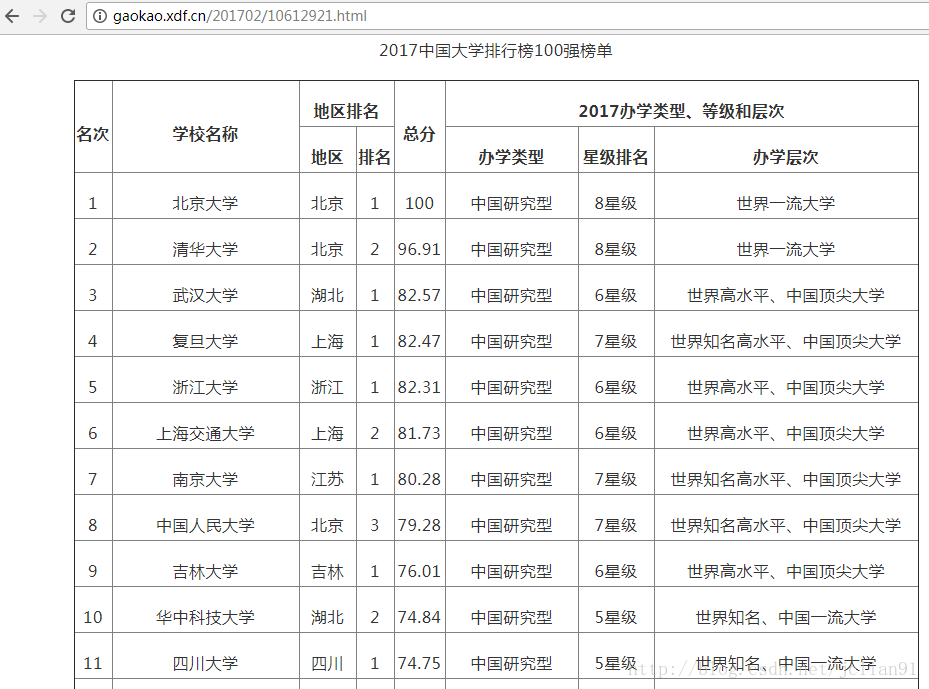
在以前 的分享中,我们利用urllib和BeautifulSoup模块爬取中国高校排名前100名并将其写入MySQL.在本次分享中,我们将会用到Scrapy和BeautifulSoup模块,来爬取中国高校排名前100名并将其写入MongoDB数据库。爬取的网页为:http://gaokao.xdf.cn/201702/10612921.html, 截图如下(部分): 首先登陆MongoDB数据.....
Scrapy 爬虫实例 抓取豆瓣小组信息并保存到mongodb中
这个框架关注了很久,但是直到最近空了才仔细的看了下 这里我用的是scrapy0.24版本 先来个成品好感受这个框架带来的便捷性,等这段时间慢慢整理下思绪再把最近学到的关于此框架的知识一一更新到博客来。 最近想学git 于是把代码放到 git-osc上了: https://git.oschina.net/1992mrwang/doubangroupspider 先说明下这个玩具爬虫的目的...
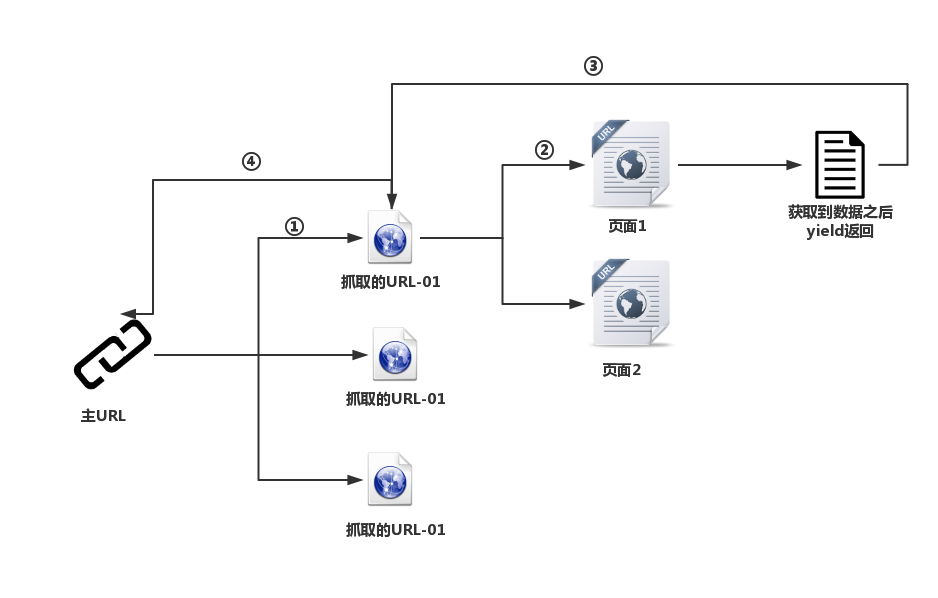
Scrapy爬虫 (1)爬取菜鸟Git教程目录
Scrapy作为爬虫利器,是一个很好的Pyhon爬虫框架,现在也已经支持Python3了。具体的安装过程可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 。关于srapy的具体介绍,可以参考网址:https://docs.scrapy.org/en/latest/ 。 本文将介绍一个极为简单的例子,通过该例子来帮读者快速.....

scrapy爬虫实例
一、爬取电影信息 http://www.imdb.cn/nowplaying/{num} #页面规则 http://www.imdb.cn/title/tt{num} #某部电影信息 获取电影url和title 新建项目 scrapy startproject imdb 修改items.py 1 2 3 4 5 6 7 8 9 10 11 12 ...
scrapy定制爬虫-爬取javascript
很多网站都使用javascript...网页内容由js动态生成,一些js事件触发的页面内容变化,链接打开.甚至有些网站在没有js的情况下根本不工作,取而代之返回你一条类似"请打开浏览器js"之类的内容. 对javascript的支持有四种解决方案: 1,写代码模拟相关js逻辑. 2,调用一个有界面的浏览器,类似各种广泛用于测试的,selenium这类. 3,使用一个无界面的浏览器,各种基于web....
4python全栈之路系列之scrapy爬虫s
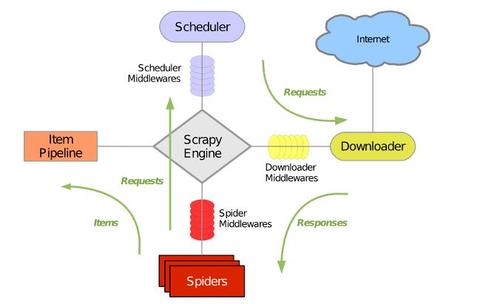
python全栈之路系列之scrapy爬虫 An open source and collaborative framework for extracting the data you need from websites. 官网:https://scrapy.org GITHUB地址:https://github.com/scrapy/scrapy Scrapy运行流程大概如下: 引...
安装python爬虫scrapy踩过的那些坑和编程外的思考
这些天应朋友的要求抓取某个论坛帖子的信息,网上搜索了一下开源的爬虫资料,看了许多对于开源爬虫的比较发现开源爬虫scrapy比较好用。但是以前一直用的java和php,对python不熟悉,于是花一天时间粗略了解了一遍python的基础知识。然后就开干了,没想到的配置一个运行环境就花了我一天时间。下面记录下安装和配置scrapy踩过的那些坑吧。 运行环境:CentOS 6.0 虚拟机 开始....
同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider。然而,现实的开发的爬虫肯定不止一个。既然这样,那么就会有如下几个问题:1、在同一个项目中怎么创建多个爬虫的呢?2、多个爬虫的时候是怎么将他们运行起来呢? 说明:本文章是基于前面几篇文章和实验的基础上完成的。如果您错过了,或者有疑惑的地方可以在此查看: 安装python爬虫scrapy踩过的那些坑和编程外的思考 scrapy爬虫成长....
scrapy爬虫流程
1 2 3 4 5 6 7 一、scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处 理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也 可以应用在获取API所返回的数据(例如 Amazon Associates ...
scrapy爬虫成长日记之将抓取内容写入mysql数据库
前面小试了一下scrapy抓取博客园的博客(您可在此查看scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据),但是前面抓取的数据时保存为json格式的文本文件中的。这很显然不满足我们日常的实际应用,接下来看下如何将抓取的内容保存在常见的mysql数据库中吧。 说明:所有的操作都是在“scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据”的基础上完成,如果....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注