
基于scrapy的腾讯社会招聘爬虫
2018年6月9日复习scrapy爬虫框架 1.本人操作系统为Win10,python版本为3.6,使用的命令行工具为powershell,所起作用和cmd的作用相差不大。 2.进入powershell:在你的爬虫程序文件夹中,在按住shift键的情况下,单击鼠标右键,显示如下图。 1.png 点击“在”此处打开Powershell窗口",可以实现基于当前目录打开powershell...
scrapy爬虫抓到的网页内容有时为空的
环境说明所抓取网址为https://www.weixinqun.com/,针对该网址大量抓取,有很多页面刚开始抓取时,设置下载延时2s,一切正常一天过后,还没抓完,这时发现开始出现报错,响应为200但是response.body却为空,即response.text=='',基本上正常一个失败一个采用scrapy shell 对失败的网址进行测试发现可以正常抓取到内容本来想通过wireshark抓....
如何租到靠谱的房子?Scrapy爬虫帮你一网打尽各平台租房信息!
又是一年n度的找房高峰期,各种租赁信息眼花缭乱,如何快速、高效的找到靠谱的房子呢? 不堪忍受各个租房网站缭乱的信息,一位技术咖小哥哥最近开发了一个基于 Scrapy 的爬虫项目,聚合了来自豆瓣,链家,58 同城等上百个城市的租房信息,统一集中搜索感兴趣的租房信息,还突破了部分网站鸡肋的搜索功能。 通过这个“秘密武器”,这位技术咖已经使用该爬虫找到合适的住所。 不仅如此,还很无私地整理了项目代码,....
Scrapy爬虫(8)scrapy-splash的入门
scrapy-splash的介绍 在前面的博客中,我们已经见识到了Scrapy的强大之处。但是,Scrapy也有其不足之处,即Scrapy没有JS engine, 因此它无法爬取JavaScript生成的动态网页,只能爬取静态网页,而在现代的网络世界中,大部分网页都会采用JavaScript来丰富网页的功能。所以,这无疑Scrapy的遗憾之处。 那么,我们还能愉快地使用Scrapy来...

Scrapy爬虫(7)在Windows中安装及使用Scrapy
本次分享将介绍Scrapy在Windows系统中的安装以及使用,主要解决的问题有: 在Windows中安装Scrapy模块 在IDE(PyCharm)中使用Scrapy Scrapy导出的csv文件乱码 首先介绍如何在Windows中安装Scrapy模块。 在https://www.lfd.uci.edu/~gohlke/pythonlibs/网站中下载适合自己Python版...
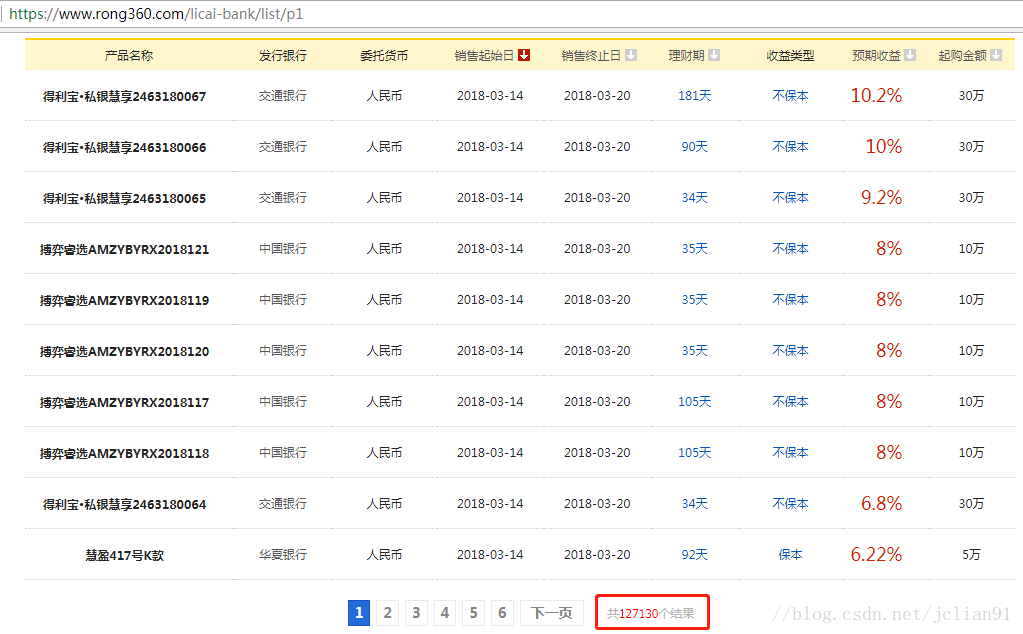
Scrapy爬虫(6)爬取银行理财产品并存入MongoDB(共12w+数据)
本次Scrapy爬虫的目标是爬取“融360”网站上所有银行理财产品的信息,并存入MongoDB中。网页的截图如下,全部数据共12多万条。 我们不再过多介绍Scrapy的创建和运行,只给出相关的代码。关于Scrapy的创建和运行,有兴趣的读者可以参考:Scrapy爬虫(4)爬取豆瓣电影Top250图片。 修改items.py,代码如下,用来储存每个理财产品的相关信息,如产品...
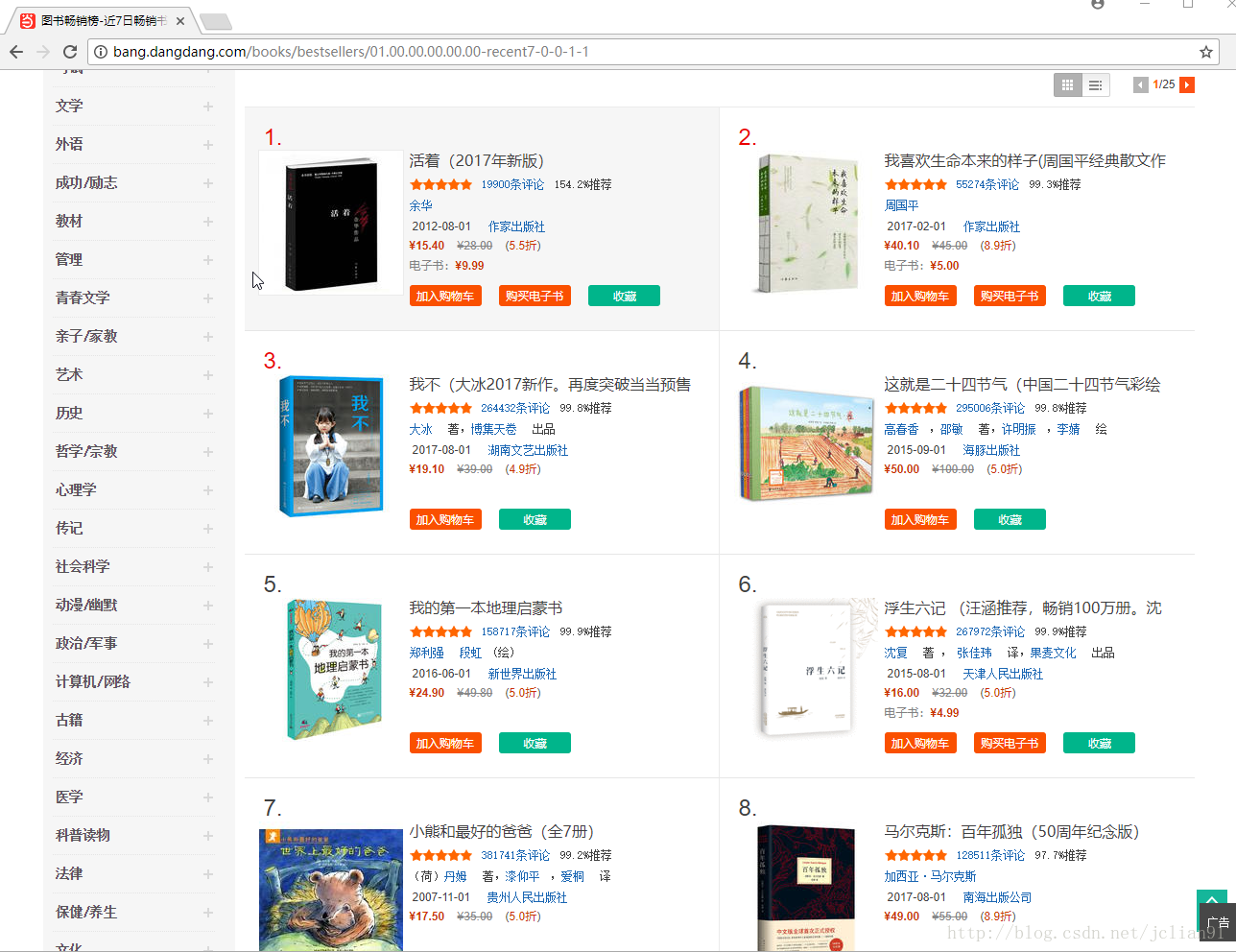
Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件。项目的具体创建就不再多讲,可以参考上一篇博客,我们只需要修改items.py文件,以及新建一个爬虫文件BookSpider.py. items.py文件的代码如下,用来储存每本书的排名,书名,作者,出版社,价格...
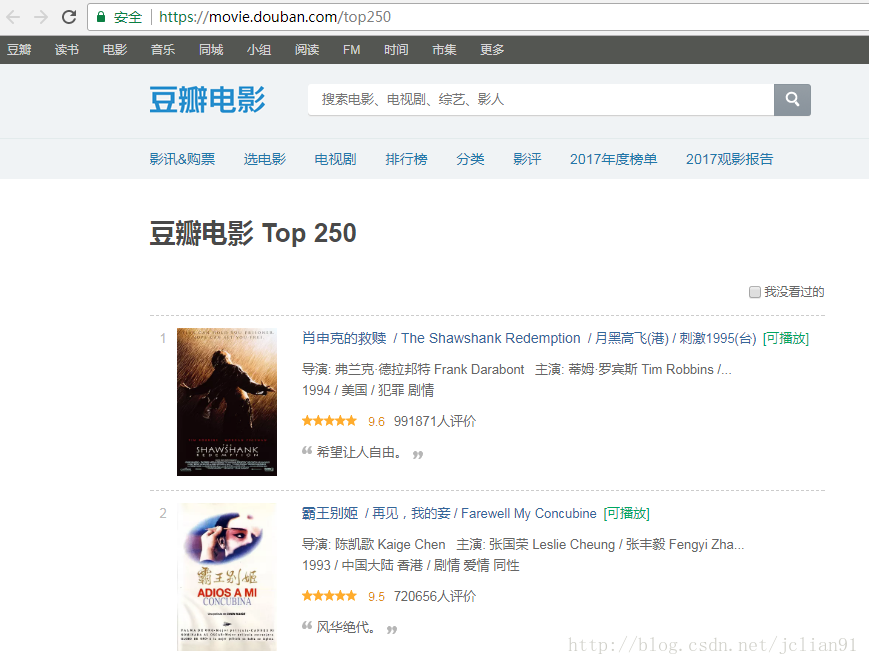
Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架——Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影Top250, 主要解决的问题有: 如何利用ImagesPipeline来下载图片 如何对下载后的图片重命名,这是因为Scrapy默认用Hash值来保存文件,这并不是我们想要的 首先我们要爬...
精通Python爬虫从Scrapy到移动应用(文末福利)
我能够听到人们的尖叫声:“Appery.io是什么,一个手机应用的专用平台,它和Scrapy有什么关系?”那么,眼见为实吧。你可能还会对几年前在Excel电子表格上给某个人(朋友、管理者或者客户)展示数据时的场景印象深刻。不过现如今,除非你的听众都十分老练,否则他们的期望很可能会有所不同。在接下来的几页里,你将看到一个简单的手机应用,这是一个只需几次单击就能够创建出来的最小可视化产品,其目的是向....
初识Scrapy,在充满爬虫的世界里做一个好公民
欢迎来到你的Scrapy之旅。通过本文,我们旨在将你从一个只有很少经验甚至没有经验的Scrapy初学者,打造成拥有信心使用这个强大的框架从网络或者其他源爬取大数据集的Scrapy专家。本文将介绍Scrapy,并且告诉你一些可以用它实现的很棒的事情。 1.1 初识Scrapy Scrapy是一个健壮的网络框架,它可以从各种数据源中抓取数据。作为一个普通的网络用户,你会发现自己经常需要从网站上获取数....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注