
Python爬虫入门教程 30-100 高考派大学数据抓取 scrapy
1. 高考派大学数据----写在前面 终于写到了scrapy爬虫框架了,这个框架可以说是python爬虫框架里面出镜率最高的一个了,我们接下来重点研究一下它的使用规则。 安装过程自己百度一下,就能找到3种以上的安装手法,哪一个都可以安装上可以参考 https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html 官方说明进行安装。 .....
关于Scrapy爬虫项目运行和调试的小技巧(下篇)
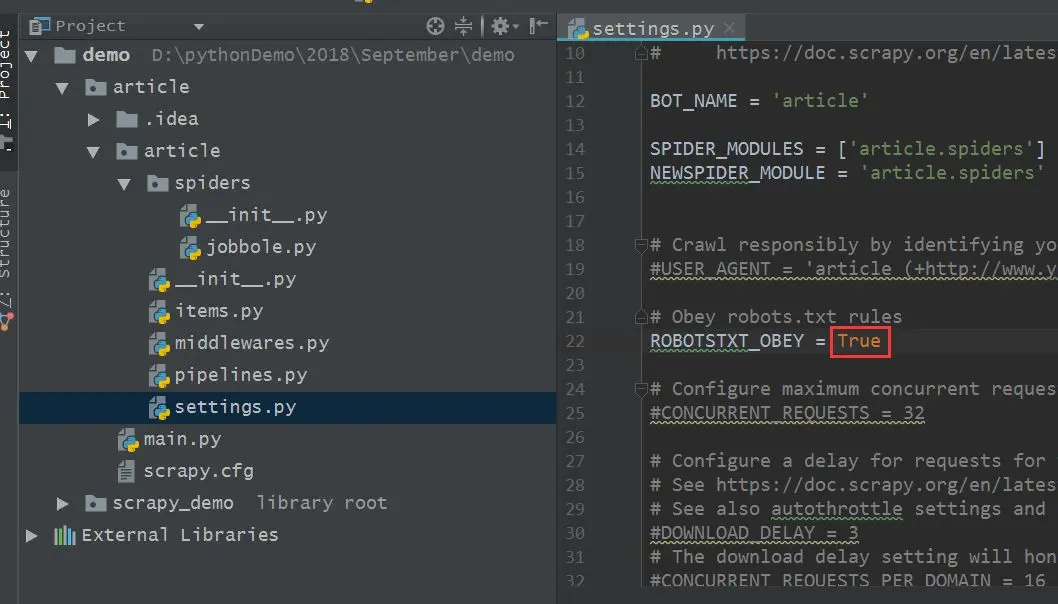
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下。今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧。 三、设置网站robots.txt规则为False 一般的,我们在运用Scrapy框架抓取数据之前,需要提前到settings.py文件中,将“ROBOTSTXT_OBEY = True”改为ROBOTSTXT....
关于Scrapy爬虫项目运行和调试的小技巧(上篇)
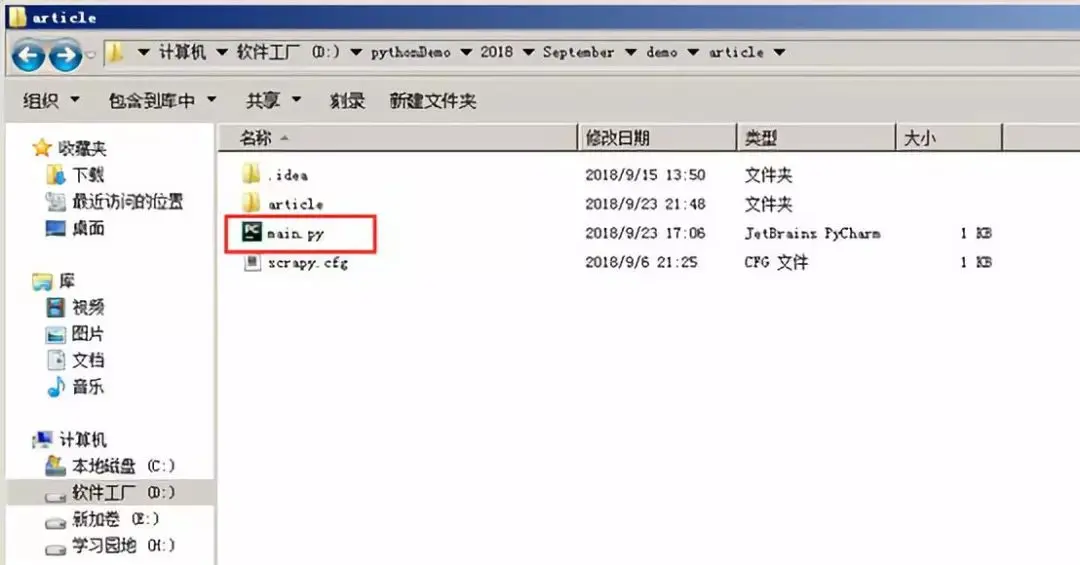
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了。在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫。 一、建立main.py文件,直接在Pycharm下进行调试 很多时候我们在使用Scrapy爬虫框架的时候,如果想运行Scrapy爬虫项目的话,一般都会想着去命令行中直接执行命令“scrapy craw...
scrapy爬虫加载API,配置自定义加载模块
当我们在scrapy中写了几个爬虫程序之后,他们是怎么被检索出来的,又是怎么被加载的?这就涉及到爬虫加载的API,今天我们就来分享爬虫加载过程及其自定义加载程序。 SpiderLoader API 该API是爬虫实例化API,主要实现一个类SpiderLoader class scrapy.loader.SpiderLoader 该类负责检索和处理项目中定义的spider类。 可以通过...
通过核心API启动单个或多个scrapy爬虫
可以使用API从脚本运行Scrapy,而不是运行Scrapy的典型方法scrapy crawl;Scrapy是基于Twisted异步网络库构建的,因此需要在Twisted容器内运行它,可以通过两个API来运行单个或多个爬虫scrapy.crawler.CrawlerProcess、scrapy.crawler.CrawlerRunner。 启动爬虫的的第一个实用程序是scrapy.crawler....
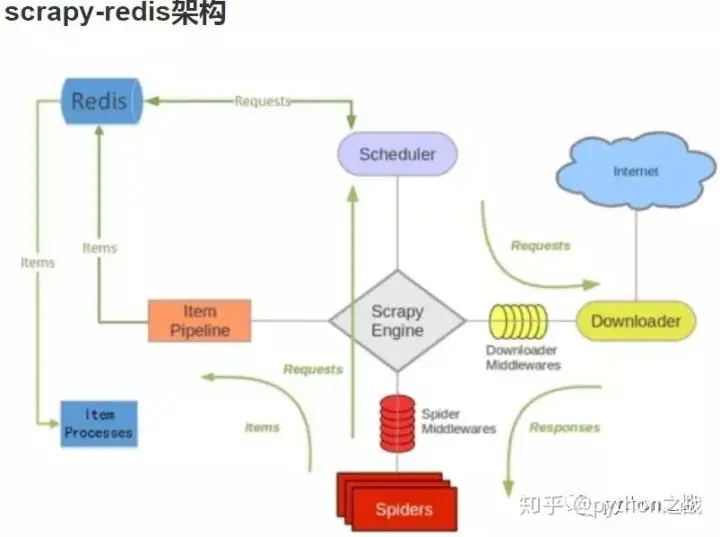
scrapy框架通用爬虫、深度爬虫、分布式爬虫、分布式深度爬虫,源码解析及应用
scrapy框架是爬虫界最为强大的框架,没有之一,它的强大在于它的高可扩展性和低耦合,使使用者能够轻松的实现更改和补充。 其中内置三种爬虫主程序模板,scrapy.Spider、RedisSpider、CrawlSpider、RedisCrawlSpider(深度分布式爬虫)分别为别为一般爬虫、分布式爬虫、深度爬虫提供内部逻辑;下面将从源码和应用来学习, scrapy.Spider 源码: ""....
Scrapy爬虫错误日志汇总
Scrapy爬虫错误日志汇总 1、数组越界问题(list index out of range) 原因:第1种可能情况:list[index]index超出范围,也就是常说的数组越界。 第2种可能情况:list是一个空的, 没有一个元素,进行list[0]就会出现该错误,这在爬虫问题中很常见,比如有个列表爬下来为空,统一处理就会报错。 解决办法:从你的网页内容解析提取的代码块中找找看啦(.....

手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何新建scrapy爬虫框架的第一个项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明。 在我们创建好Scrapy爬虫项目之后,会得到上图中的提示,大意是让我们直接根据模板进行创建Scrapy项目。根据提示,我们首先运行“cd article”命令,意思是打开或者进入到article文件夹下,尔后执行命令“sc...
手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy还有Scrapy安装过程中常见的问题总结及其对应的解决方法感兴趣的小伙伴可以戳链接进去查看。关于Scrapy的介绍之前也在文章中提及过今天小编带大家进入Scrapy爬虫框架创建Scrapy爬虫框架的第一个项目具体过程如下所示。 1、进入虚拟环境不知道进入的环境的小伙伴可以戳这篇文章在Windows下如何创...
在windows下如何新建爬虫虚拟环境和进行scrapy安装
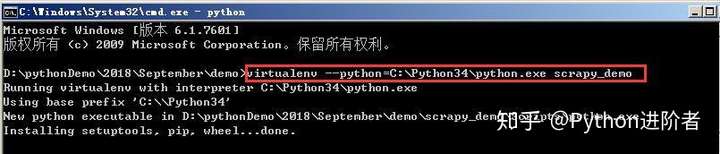
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。 1、关于虚拟环境的创建可以参考之前发布的两篇博文,在Windows下如何创建指定的虚拟环境和在Windows下如何创建虚拟环境(默认情况下)。....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注