
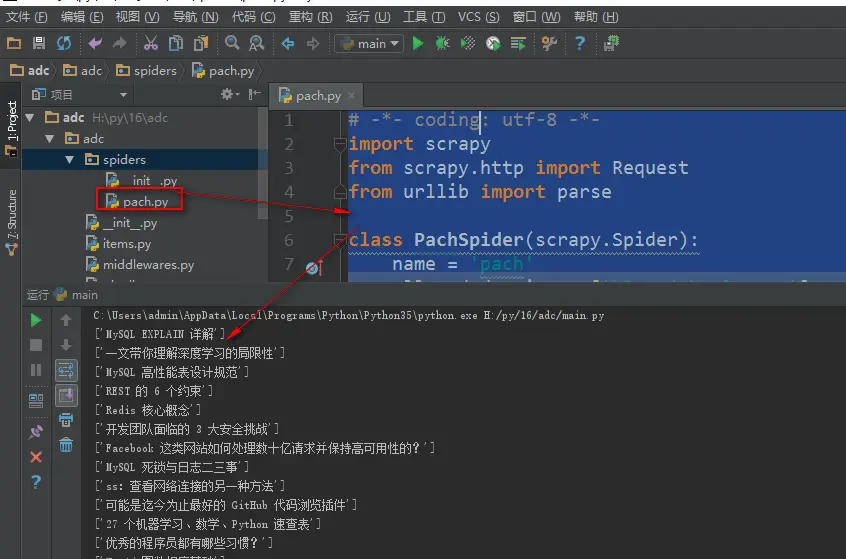
20、 Python快速开发分布式搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield Request() parse.urljoin()方法,是urllib库下的方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接 # -*- ...
14、web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
打码接口文件 # -*- coding: cp936 -*- import sys import os from ctypes import * # 下载接口放目录 http://www.yundama.com/apidoc/YDM_SDK.html # 错误代码请查询 http://www.yundama.com/apidoc/YDM_ErrorCode.html # 所有函数请查询 ht...
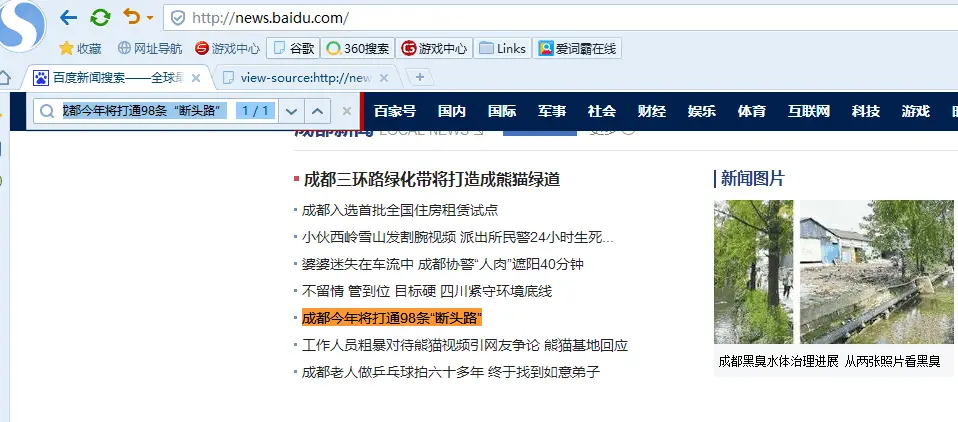
13、web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息,那么这种一般都是 js 的 Ajax 动态请求生成的信息 我们以百度新闻为列: 1、分析网站 首先我们浏览器打开百度新闻,在网页中间部分找一条新闻信息 然后查看源码,看看在源码里是否有这条新...
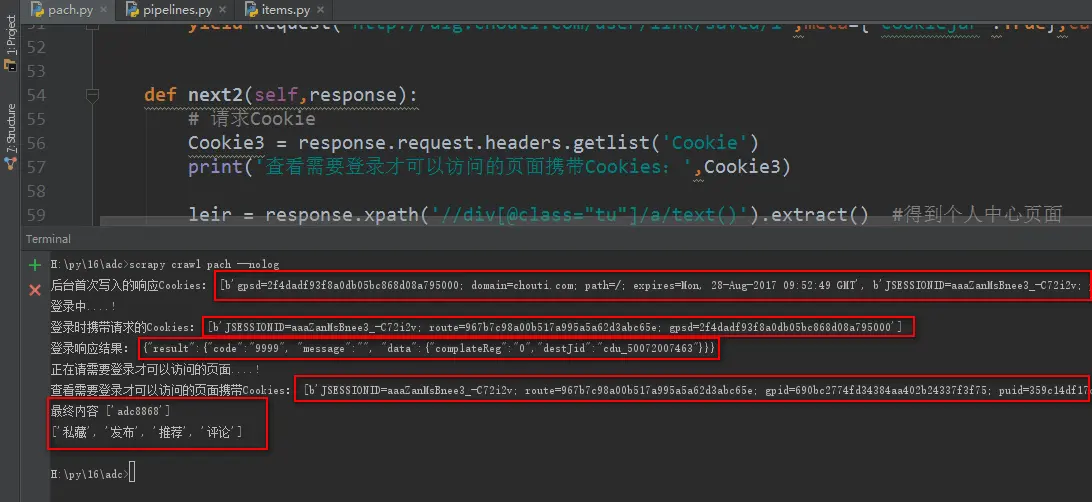
12、web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里的请求 Request()get请求,可以设置,url、cookie、回调函数 FormRequest.from_response()表单post提交,第一个必须参数,上一次响应cookie的res....
11、web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 /@x 表示查找指定属性的值,可以连缀如:@id @src [@属性名称="属性值"]表示查找指定属性等于指定值的标签,可以连缀 ,如查找class名称等于指定名称的标签 /text() 获取标签文本类容 [x...
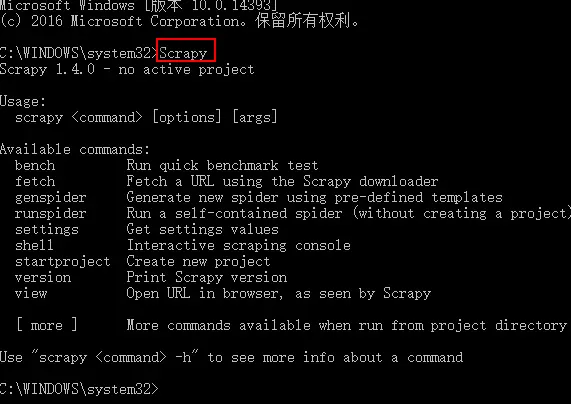
10、web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1、首先,终端执行命令升级pip: python -m pip install --upgrade pip2、安装,wheel(建议网络安装) pip install wheel3、安装,lxml(建议下载安装)4、安装,Twisted(建议下载安装)5、安装,Scrapy(建议网络安装) pip install Scrapy 测试Scrapy是否安装成功 Scrapy框.....
5、web爬虫,scrapy模块,解决重复ur——自动递归url
【百度云搜索:http://www.lqkweb.com】【搜网盘:http://www.swpan.cn】 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 记录url可以是缓存,或者数据库,如果保存数据库按照以下方式: id URL加密(建索引以便查询) 原始URL 保存URL表里应该至少有以上3个字段1、URL加....

4、web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
转载自:https://www.jianshu.com/p/8f22cace85c7 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需要导入模块:from scrapy.selector import HtmlXPathSelector select()标签选择器方法,是HtmlXPathSelector里的一个方法,参数接收....
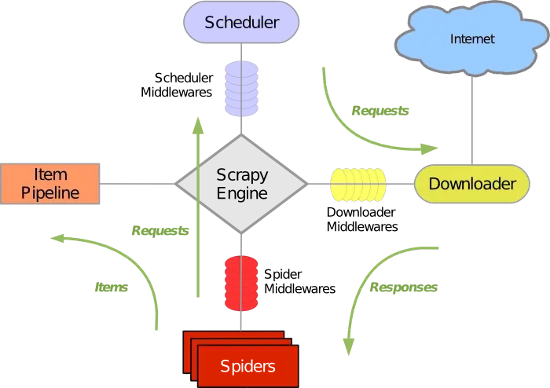
3、web爬虫,scrapy模块介绍与使用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。 Scrapy 使....
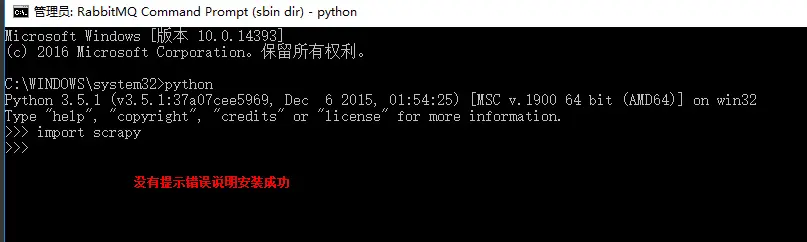
2、web爬虫,scrapy模块以及相关依赖模块安装
当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip install Scrapy 手动源码安装,比较麻烦要自己手动安装scrapy模块以及依赖模块 安装以下模块 1、lxml-3.8.0.tar.gz (XML处理库) 2、Twisted-17.5.0.tar.bz2 (用Python编写的异步...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注