
Scrapy结合Selenium实现搜索点击爬虫的最佳实践
一、动态网页爬取的挑战动态网页通过JavaScript等技术在客户端动态生成内容,这使得传统的爬虫技术(如requests和BeautifulSoup)无法直接获取完整的内容。具体挑战包括: 数据加载异步化:数据并非一次性加载,而是根据用户操作动态更新。请求复杂化:可能涉及多个AJAX请求ÿ...
在Scrapy爬虫中应用Crawlera进行反爬虫策略
在互联网时代,数据成为了企业竞争的关键资源。然而,许多网站为了保护自身数据,会采取各种反爬虫技术来阻止爬虫的访问。Scrapy作为一个强大的爬虫框架,虽然能够高效地抓取网页数据,但在面对复杂的反爬虫机制时,仍然需要额外的工具来增强其反爬能力。Crawlera就是这样一款能够协助Scrapy提升反爬能力的工具。什么...
Scrapy爬虫框架-通过Cookies模拟自动登录
Scrapy爬虫框架-通过Cookies模拟自动登录熟练使用Cookies在编写爬虫程序时是非常重要的,Cookies代表用户的信息,如果需要爬取登录后网页的信息,就可以将Cookies信息保存,然后在第二次获取登录后的信息时就不需要再次登录了,直接使用Cookies进行登录即可。 1.3.1 在Scrapy中,...
Scrapy爬虫框架-自定义中间件
Scrapy爬虫框架-自定义中间件Scrapy中内置了多个中间件,不过在多数情况下开发者都会选择创建一个属于自己的中间件,这样既可以满足自己的开发需求,还可以节省很多开发时间。在实现自定义中间件时需要重写部分方法,因为Scrapy引擎需要根据这些方法名来执行并处理,如果没有重写这些方法,Scrapy的引擎将会按照...

Scrapy 爬虫框架(一)
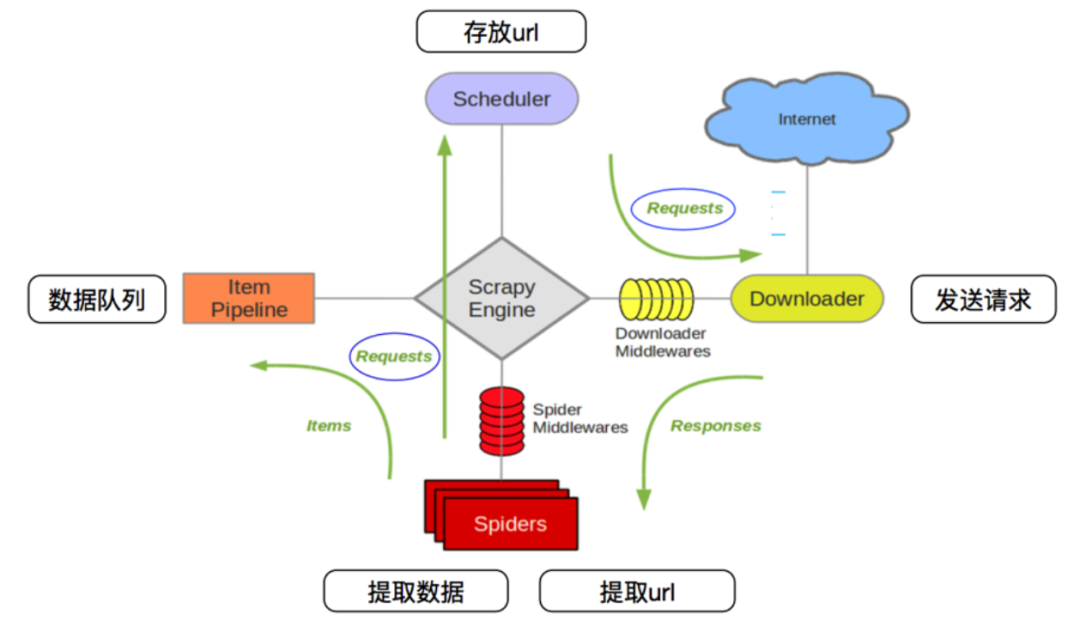
Scrapy 爬虫框架1. 概述Scrapy是一个可以爬取网站数据,为了提取结构性数据而编写的开源框架。Scrapy的用途非常广泛,不仅可以应用到网络爬虫中,还可以用于数据挖掘、数据监测以及自动化测试等。Scrapy是基于Twisted的异步处理框架,架构清晰、可扩展性强,可以灵活完成各种需求。 在Scrapy的工作流程中主要...
Scrapy 爬虫框架(二)
接上文 Scrapy 爬虫框架(一)https://developer.aliyun.com/article/1618014 2 创建爬虫在创建爬虫时,首先需要创建一个爬虫模块文件,该文件需要放置在spiders文件夹当中。爬虫模块是用于从一个网站或多个网站中爬取数据的类,它需要继承scrapy.Spider类,...

Scrapy 爬虫框架的基本使用
一、scrapy 爬虫框架介绍 在编写爬虫的时候,如果我们使用 requests、aiohttp 等库,需要从头至尾把爬虫完整地实现一遍,比如说异常处理、爬取调度等,如果写的多了,的确会比较麻烦。利用现有的爬虫框架,可以提高编写爬虫的效率,而说到 Python 的爬虫框架,Scrapy 当之无愧是最流行最强大的爬虫框架了。 scrapy 介绍 Scrapy 是一个基于 T...
Redis 与 Scrapy:无缝集成的分布式爬虫技术
分布式爬虫的概念分布式爬虫系统通过将任务分配给多个爬虫节点,利用集群的计算能力来提高数据抓取的效率。这种方式不仅可以提高爬取速度,还可以在单个节点发生故障时,通过其他节点继续完成任务,从而提高系统的稳定性和可靠性。Scrapy 简介Scrapy 是一个用于快速抓取 web 数据的 Python 框架。它提供了一个异步处理的架构,...
使用多进程和 Scrapy 实现高效的 Amazon 爬虫系统
在这篇博客中,将展示如何使用多进程和 Scrapy 来构建一个高效的 Amazon 爬虫系统。通过多进程处理,提高爬虫的效率和稳定性,同时利用 Redis 进行请求调度和去重。 项目结构 Scrapy 爬虫:负责从 Amazon 抓取数据。 MongoDB:存储待爬取的链接。 Redis:用于请求调度和去重。 多进程管理:通过 Pytho...
Scrapy,作为一款强大的Python网络爬虫框架,凭借其高效、灵活、易扩展的特性,深受开发者的喜爱
一、引言 在当今信息化时代,网络爬虫作为数据收集与处理的得力工具,发挥着越来越重要的作用。Scrapy,作为一款强大的Python网络爬虫框架,凭借其高效、灵活、易扩展的特性,深受开发者的喜爱。本文将带领读者走进Scrapy的世界,探索其如何解锁网络爬虫新境界。 二、Scrapy框架的核心特性与优势 高效性Scr...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy爬虫相关内容
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注