
PolarDB-X最佳实践系列(五):使用通义千问和存储过程快速生成测试数据
文章来源:PolarDB知乎号 作者:梦实 我们在测试数据库性能的过程中,通常需要生成一批测试数据。 以前,一般要写一段程序或者脚本来完成这项工作,但现在是2024年啦!时代变了! PolarDB-X目前是少有的支持存储过程的分布式数据库,结合大模型,我们可以非常简单的来制造测试数据: 存储过程的原理和使用方法 通义官网 例如,有这样...

PolarDB-X最佳实践:如何设计一张订单表
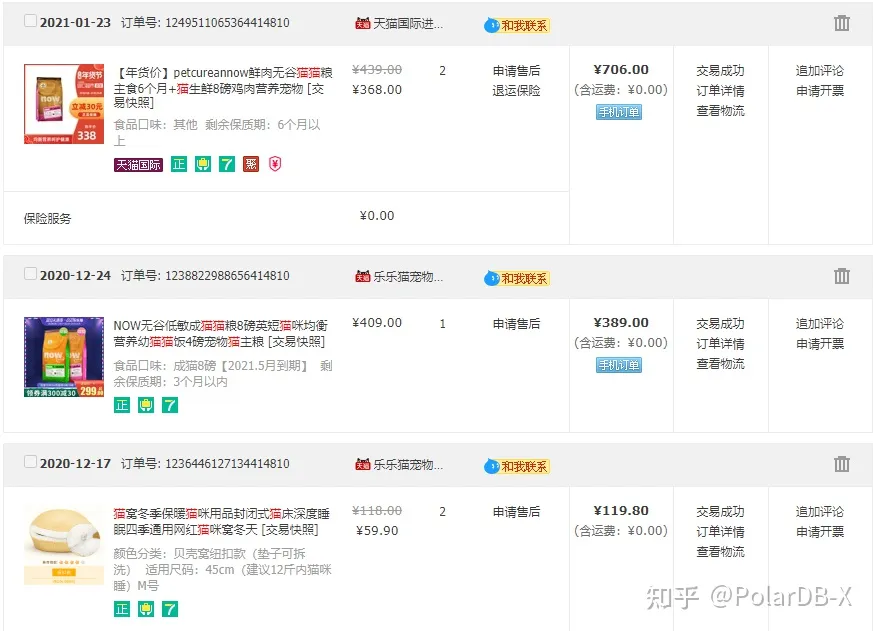
本文主要内容是如何使用全局索引与CO_HASH分区算法(CO_HASH),实现高效的多维度查询。1. 淘宝订单号中的秘密有一个很有趣的事情。打开你的淘宝客户端或者PC端的淘宝,点开订单列表,打开几个订单,查看他们的订单号,你会发现什么?比如这是我最近的3个订单,和10年前的3个订单。其订单号分别是:1249511065364414810123882298865641481012364461271....
PolarDB-X中最佳实践的表无法创建,pxc-4500语法错误,要怎么解决啊?
PolarDB-X中最佳实践的表无法创建,pxc-4500语法错误,要怎么解决啊?
PolarDB-X 1.0-SQL 手册-DDL任务管理-最佳实践
本文将介绍一些对PENDING任务进行合适处理的最佳实践。背景介绍新的DDL任务引擎启用时,当DDL执行失败或者被意外中断后,对应的DDL任务会处于PENDING待处理的状态,此时必须对该PENDING状态进行合适的任务处理,才能解除PENDING状态并恢复正常访问,否则后续的DDL将会被禁止执行并报错。处理原则您可以通过SHOW [FULL] DDL语句查看DDL任务的信息和失败原因(即REM....
PolarDB-X 1.0-最佳实践-如何选择实例规格
PolarDB-X 1.0计算资源实例与PolarDB-X 1.0存储资源实例按照CPU的处理能力、内存容量和磁盘空间等来划分实例的规格,并提供多种不同规格的实例供选择,规格越高代表实例的处理能力越强。本文介绍如何选择实例规格。PolarDB-X 1.0计算资源实例类型与规格的选择PolarDB-X 1.0计算资源实例均为专享实例,每个实例最少提供2个节点保证高可用。PolarDB-X 1.0计....
PolarDB-X 1.0-最佳实践-如何选择拆分键
背景信息拆分键即分库或分表字段,是水平拆分过程中用于生成拆分规则的数据表字段。PolarDB-X将拆分键值通过拆分函数计算得到一个计算结果,然后根据这个结果将数据分拆到私有定制RDS实例上。数据表拆分的首要原则是尽可能找到数据所归属的业务逻辑实体,并确定大部分(或核心的)SQL操作或者具备一定并发的SQL都是围绕这个实体进行,然后可使用该实体对应的字段作为拆分键。示例业务逻辑实体通常与应用场景相....
PolarDB-X 1.0-最佳实践-如何选择分片数
本文将介绍如何为PolarDB-X中选择分片数(即水平拆分时的物理分表数)。背景信息PolarDB-X中的水平拆分包含了分库和分表两个层次。若您在创建数据库时,选择拆分模式为水平拆分,则PolarDB-X为默认为每个私有定制RDS实例创建8个物理分库,每个物理分库上可以创建一个或多个物理分表,而分表数通常也被称为分片数。计算公式一般情况下,建议单个物理分表的总容量范围在500万~5000万行数据....
PolarDB-X 1.0-最佳实践-何时选择升配
背景信息数据库性能主要受响应时间(RT)和容量(QPS)两个指标的影响。响应时间(RT):RT指标反映的是单个SQL的性能,这类性能问题可以通过SQL调优方法等方法进行解决。容量(QPS):容量瓶颈问题可以通过PolarDB-X 1.0实例升配来解决,通过升配来扩充容量的方式适用于低延时高QPS类型的数据库访问业务场景。PolarDB-X 1.0性能同时受到计算层和存储层节点性能的影响,任一计算....
PolarDB-X 1.0-最佳实践-何时选择平滑扩容
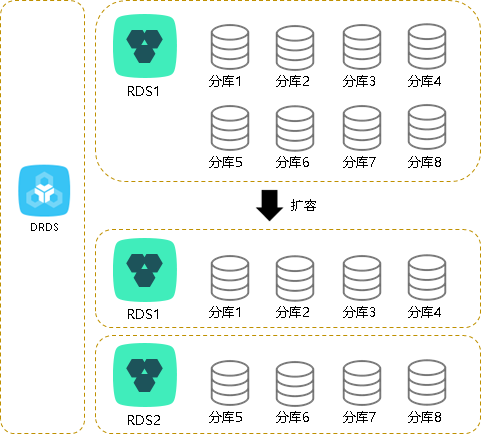
什么是平滑扩容PolarDB-X 平滑扩容是指通过增加 RDS 的数量以提升整体性能。当 RDS 的 IOPS、CPU、磁盘容量等指标到达瓶颈,并且 SQL 优化、RDS 升配已无法解决瓶颈(例如磁盘已升至顶配)时,可通过 PolarDB-X 水平扩容增加 RDS 数量,提升 PolarDB-X 数据库的容量。PolarDB-X 平滑扩容通过迁移分库到新 RDS 来降低原 RDS 的压力。例如,....
PolarDB-X 1.0-最佳实践-如何选择应用连接池
数据库连接池是对数据库连接进行统一管理的技术,主要目的是提高应用性能,减轻数据库负载。资源复用:连接可以重复利用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,同时增进了系统的平稳性。提高系统响应效率:连接的初始化工作完成后,所有请求可以直接利用现有连接,避免了连接初始化和释放的开销,提高了系统的响应效率。避免连接泄漏:连接池可根据预设的回收策略,强制回收连接,从而避免了连....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生分布式数据库 PolarDB-X最佳实践相关内容
云原生分布式数据库 PolarDB-X您可能感兴趣
- 云原生分布式数据库 PolarDB-X节点
- 云原生分布式数据库 PolarDB-X binlog
- 云原生分布式数据库 PolarDB-X日志
- 云原生分布式数据库 PolarDB-X内存
- 云原生分布式数据库 PolarDB-X端口
- 云原生分布式数据库 PolarDB-X安装
- 云原生分布式数据库 PolarDB-X设置
- 云原生分布式数据库 PolarDB-X企业版
- 云原生分布式数据库 PolarDB-X优化
- 云原生分布式数据库 PolarDB-X实践
- 云原生分布式数据库 PolarDB-X polardb
- 云原生分布式数据库 PolarDB-X版本
- 云原生分布式数据库 PolarDB-X mysql
- 云原生分布式数据库 PolarDB-X数据库
- 云原生分布式数据库 PolarDB-X同步
- 云原生分布式数据库 PolarDB-X sql
- 云原生分布式数据库 PolarDB-X说明
- 云原生分布式数据库 PolarDB-X rds
- 云原生分布式数据库 PolarDB-X数据
- 云原生分布式数据库 PolarDB-X参考
- 云原生分布式数据库 PolarDB-X api
- 云原生分布式数据库 PolarDB-X开源
- 云原生分布式数据库 PolarDB-X部署
- 云原生分布式数据库 PolarDB-X用户指南
- 云原生分布式数据库 PolarDB-X分布式数据库
- 云原生分布式数据库 PolarDB-X手册
- 云原生分布式数据库 PolarDB-X查询
- 云原生分布式数据库 PolarDB-X库
- 云原生分布式数据库 PolarDB-X报错
- 云原生分布式数据库 PolarDB-X实例
PolarDB 分布式版
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about
+关注