
将HBase数据同步到阿里云ES
如果您需要对HBase中的数据进行搜索和分析,可借助阿里云Elasticsearch实现。本文介绍通过DataWorks的数据集成服务,快速将数据离线同步到阿里云ES中。
有什么方案既可以像es那样快速检索,也能像hbase那样做分布式存储以便更复杂的数据处理逻辑?
日志既要做实时分析,也要将原始数据存储起来做一些其他的可能的分析,有什么方案既可以像es那样快速检索,也能像hbase那样做分布式存储以便更复杂的数据处理逻辑?
Hbase+ES和MongoDB存储大数据的选用
1 需求解决海量数据的存储,并且能够实现海量数据的秒级查询Hbase是典型的nosql,是一种构建在HDFS之上的分布式、面向列的存储系统,在需要的时候可以进行实时的大规模数据集的读写操作;但是hbase的语法非常固话,即便在hbase之上嫁接了phoneix在应对复杂查询的时候,仍然力不从心;这里只说是大公司,小公司一个HBASE绝对够用所以说很多公司在历史遗留问题,最开始数据存储在hbase....

系统设计之ES和Hbase的结合使用设计
这里分享一种设计方案,也是用了好久慢慢优化过来的,可以针对大数据场景下非实时的数据挑战,将读写彻底分离开来,利用大数据组件读取,其他数据库集群当作写入,然后同步数据给我们的大数据相关集群,比如ES和Hbase,其中部分业务核心字段,我们可以先利用ES强大的搜索效率去查询出对应的根属性内容,在这里我们可以把根属性理解为基本表,也就是我们所谓的单表,在一对多的场景下,我们可以利用单表的某个业务字段去....
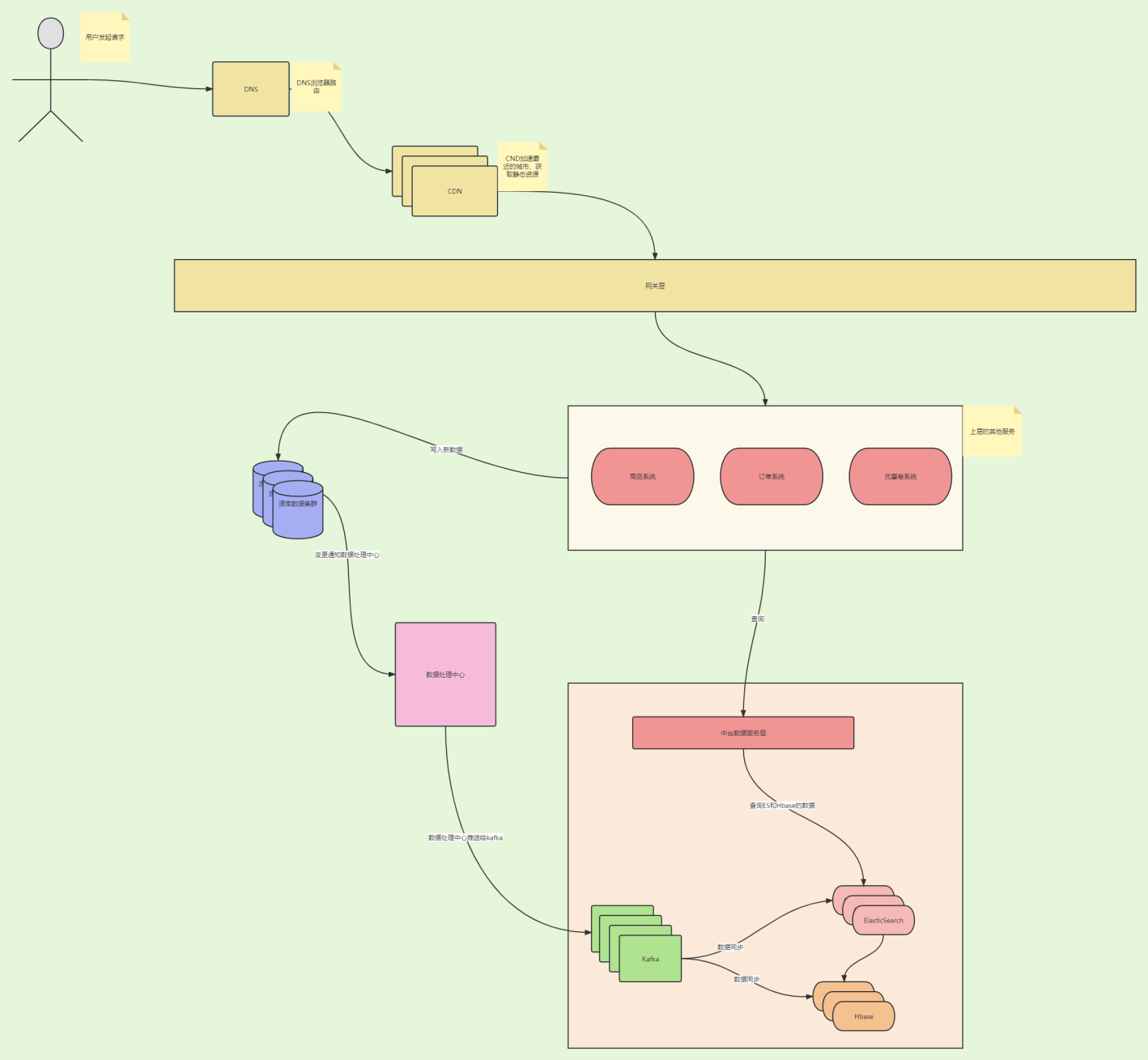
flink写es和hbase反压怎么解决?
现在用flink自定义source读取hbase的其中一张表的数据,表中这张表的总数据有三千万条,处理完之后的数据写入es和hbase,但是每次写的时候到一千多万条就出现反压,之前怀疑是es的问题,最后单独写hbase也出现相同的问题,出问题后就一条都不写了,大佬指点一下。日志也没有异常。详见附件。es和hbase都是批量写。source和sink的并行度都是1,中间map算子并行度16。*来自....
如果要对hbase中的数据做全文检索,是不是只能把hbase数据导入到es中去了?有没有其他方案?
如果要对hbase中的数据做全文检索,是不是只能把hbase数据导入到es中去了?有没有其他方案? 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 点击这里欢迎加入感兴趣的技术领域群。
为什么不直接把数据存到es/solr里 是因为hbase适合高吞吐写入吗
请教个问题 : es/solr 可以用于hbase的二级索引, 那为什么不直接把数据存到es/solr里 ,是因为hbase适合高吞吐写入吗? 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云数据库HBase版es相关内容
云数据库HBase版您可能感兴趣
- 云数据库HBase版类型
- 云数据库HBase版导入
- 云数据库HBase版监控
- 云数据库HBase版导出
- 云数据库HBase版备份
- 云数据库HBase版数据
- 云数据库HBase版shell
- 云数据库HBase版集群
- 云数据库HBase版实时监控
- 云数据库HBase版性能指标
- 云数据库HBase版hadoop
- 云数据库HBase版flink
- 云数据库HBase版hive
- 云数据库HBase版表
- 云数据库HBase版报错
- 云数据库HBase版存储
- 云数据库HBase版应用
- 云数据库HBase版数据库
- 云数据库HBase版操作
- 云数据库HBase版大数据
- 云数据库HBase版安装
- 云数据库HBase版实践
- 云数据库HBase版java
- 云数据库HBase版地址
- 云数据库HBase版查询
- 云数据库HBase版spark
- 云数据库HBase版设计
- 云数据库HBase版技术
- 云数据库HBase版region
- 云数据库HBase版场景
NoSQL数据库
阿里云NoSQL数据库提供了一种灵活的数据存储方式,可以支持各种数据模型,包括文档型、图型、列型和键值型。此外,它还提供了一种分布式的数据处理方式,可以支持高可用性和容灾备份。包含Redis社区版和Tair、多模数据库 Lindorm、MongoDB 版。
+关注