
MapReduce编程例子之Combiner与Partitioner
0x00 教程内容本教程是在“MapReduce入门例子之单词计数”上做的升级,请查阅此教程。包括了实现Combiner与Partitioner编程,都是一些编程技巧。0x01 Combiner讲解1. 优势a. 其实就是本地的reducer,在本地先聚合一次b. 可以减少Map Tasks输出的数据量以及数据网络的传输量2. 使用场景a. 适用于求和、次数等的加载b. 求平均数等的计算并不合适....
mapReduce中combiner的作用是什么,一般使用情景,哪些情况不需要呢?
mapReduce中combiner的作用是什么,一般使用情景,哪些情况不需要呢?
请简述 mapreduce 中,combiner,partition 作用?
请简述 mapreduce 中,combiner,partition 作用?
MapReduce在Map端的Combiner和在Reduce端的Partitioner
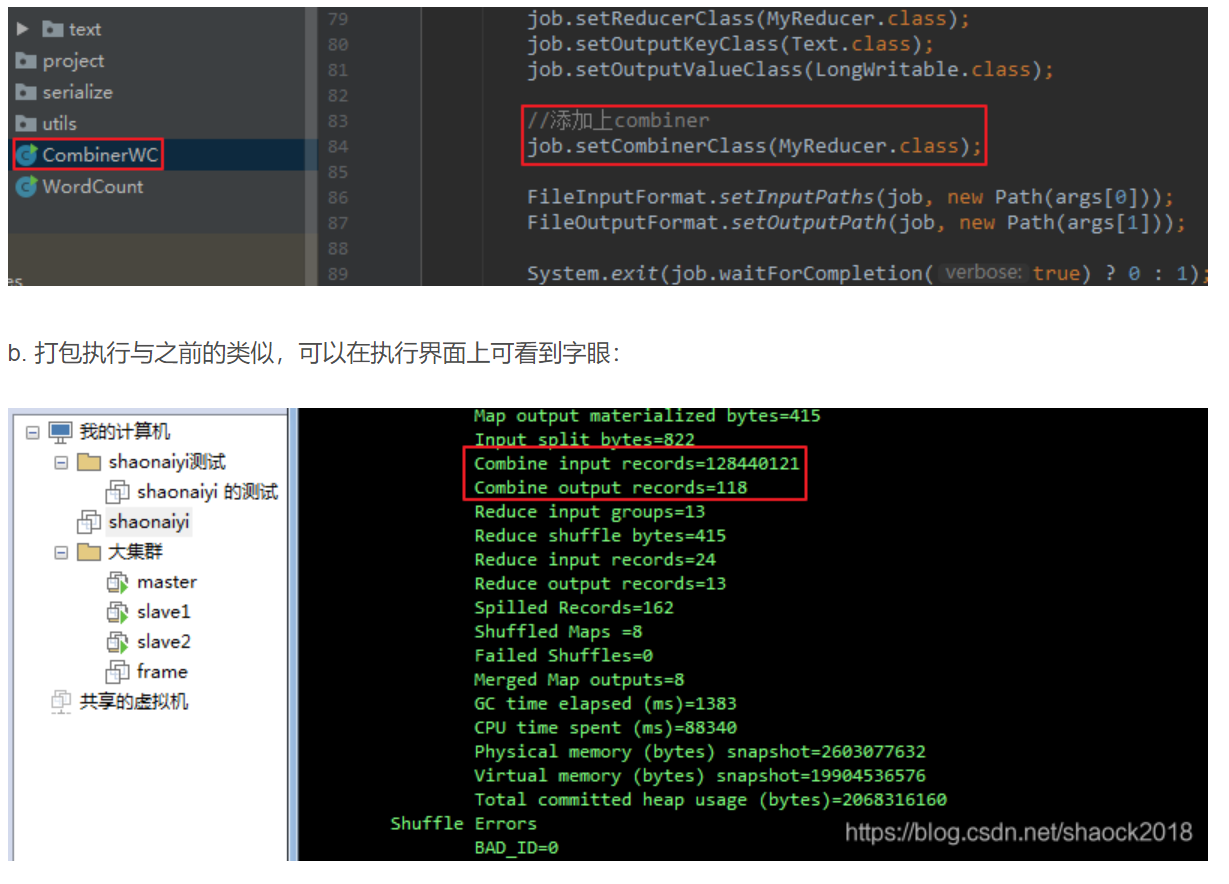
1.Map端的Combiner. 通过单词计数WordCountApp.java的例子,如何在Map端设置Combiner... 只附录部分代码: 1 /** 2 * 以文本 3 * hello you 4 * hello me 5 * 为例子. 6 * map方法调用了两次,因为有两行 7 * k2 v2 键值对的数量有几个? 8 * 有4个.有...
使用Mapreduce案例编写用于统计文本中单词出现的次数的案例、mapreduce本地运行等,Combiner使用及其相关的知识,流量统计案例和流量总和以及流量排序案例,自定义Partitioner
工程结构: 在整个案例过程中,代码如下: WordCountMapper的代码如下: package cn.toto.bigdata.mr.wc; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; i...
《Hadoop MapReduce实战手册》一1.4 给WordCount MapReduce程序增加combiner步骤
本节书摘来异步社区《Hadoop MapReduce实战手册》一书中的第1章,第1.4节,作者: 【美】Srinath Perera , Thilina Gunarathne 译者: 杨卓荦 责编: 杨海玲,更多章节内容可以访问云栖社区“异步社区”公众号查看。 1.4 给WordCount MapReduce程序增加combiner步骤 Hadoop MapReduce实战手册运行map函数后,....
[Hadoop]MapReduce中的Partitioner与Combiner
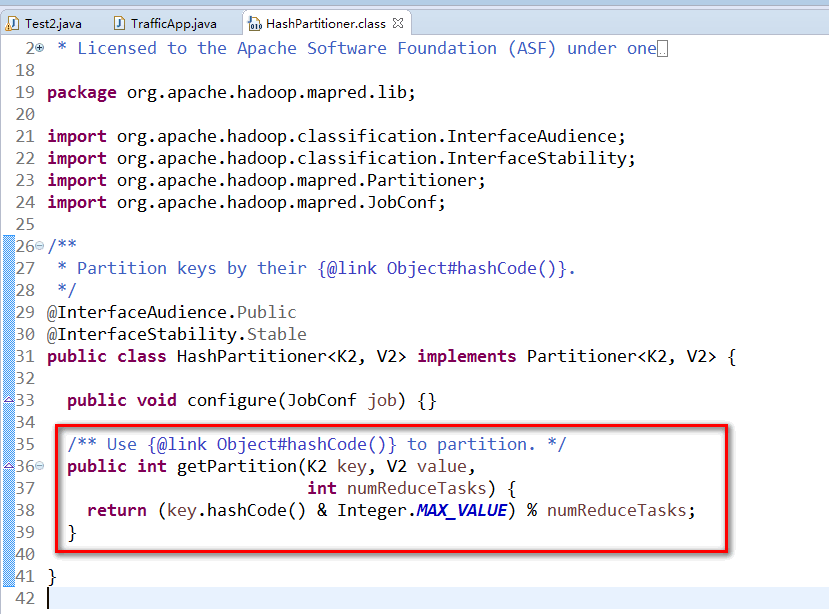
Partitioners负责划分Maper输出的中间键值对的key,分配中间键值对到不同的Reducer。Maper输出的中间结果交给指定的Partitioner,确保中间结果分发到指定的Reduce任务。在每个Reducer中,键按排序顺序处理(Within each reducer, keys are processed in sorted order)。Combiners是MapReduc....
![[Hadoop]MapReduce中的Partitioner与Combiner](https://ucc.alicdn.com/uztk64i7jwwta/developer-article632205/20241020/3f95ca17e02243beb82d48e27c0fe72d.png)
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注